

Month: December 2023

New on Microsoft AppSource – Office apps
We continue to expand the Microsoft AppSource ecosystem. For this volume, 52 new offers successfully met the onboarding criteria and went live. See details of the new offers below:
Get it now in our marketplace
AdvAIsor: AdvAIsor from Tendencias Consultoria Integrada is an AI tool for text creation, proofreading, and translation. This LLM-powered add-in for the Microsoft Office suite brings enhanced proofreading and translation experience for your documents, with maximum integration. Through a docked dashboard, get quick, easy, and dynamic access to all features with just one click.
AI Perfect Assistant for Microsoft 365: Powered by ChatGPT, AI Perfect Assistant from OOO enhances Microsoft Word and other Microsoft 365 applications to help users with tasks such as ghostwriting, translation, and summarizing text. With AI Perfect Assistant, you can generate stunning PowerPoint slides, reply to messages in Outlook and Teams, craft elegant documents in Word, and more.
aMail: From Asite Solutions, aMail is a Microsoft Outlook plugin and add-in that connects your inbox and the Asite Cloud. This customizable email management tool enables users to save emails and attachments in project folders on Asite, providing a secure and central filing cabinet for project-related correspondence.
Anagrams by Frameable: A simple yet competitive word game for Microsoft Teams, Anagrams by Frameable presents a team-building activity for before meetings get started or any time during the workday for engaging activity between coworkers. Combine letters to guess the word blanks collaboratively, competitively, or just on your own.
Atlan: Get effortless metadata enrichment and lineage impact analysis in bulk with this Atlan Technologies add-in for Microsoft Excel. This integration allows you to document descriptions, certifications, ownership, tags, and announcements for columns and any list of upstream or downstream assets right from Excel and sync it all to Atlan with a single click.
BlueCargo: This AI-powered add-in for Microsoft Outlook analyzes and recoups per diem fees directly from your inbox. After a user opens a per diem invoice attached to any email, BlueCargo analyzes the invoice, audits your per diem charges, and finds any potential savings. BlueCargo includes templates for presenting supporting evidence in dispute emails.
Blueink: Blueink is a secure, cloud-based e-signature solution that allows you to prepare, send, track, save, and download important documents and contracts for electronic signatures using Microsoft Teams. Blueink’s certificate of evidence provides a detailed audit trail of the entire signing process, including the document, the signers, and the IP address of the signer.
Carousel Pro: Prakash Software Solutions’ Carousel Pro elevates your Microsoft SharePoint experience with interactive storytelling through eye-catching animations and seamless integration. With this powerful tool, you have the freedom to infuse life into your site’s homepage and other pages, effortlessly engaging your audience and delivering information in a captivating format.
ClearContract: ClearContract offers AI-powered contract analysis to help reduce legal risk, helping in-house counsel and contract managers analyze incoming contracts by highlighting missing clauses and clauses that are deviating from the market standard. ClearContract frees up time for legal departments while reducing and streamlining contract risk.
Corcentric Platform Add-in for Word Online: This Corcentric add-in features contract clause libraries and template management to improve the editing workflow of contract documents in the Microsoft 365 online. version of Microsoft Word. Users can collaborate directly on files without having to download and re-upload to the Corcentric Platform, and changes will be integrated into the final negotiated contract.
Data Simulator: Turn to Prakash Software Solutions’ Data Simulator for Microsoft SharePoint data testing and development. The SharePoint List View Data Simulator Command Set is your passport to a hassle-free, efficient data generation experience in which you can handpick columns, set record counts, define data types, and impose numeric boundaries.
dokublick Add-In: Digital document management is made easy with this offer from Buhl Data Service. dokublick is an add-in for Microsoft Outlook that automatically stores all documents and receipts in digital folders, giving users an overview of documents and access from anywhere at any time.
Domo: The Domo app allows you to find cards and datasets you have access to within the Domo platform. When discussing data in a Microsoft Teams chat or meeting, users can easily find and post Domo data without leaving Teams. Additionally, all KPI cards you post will display a snapshot of the data.
Don’t Interrupt: From Hootware Limited, Don’t Interrupt is a powerful tool designed to enhance productivity and work-life balance while using Microsoft Teams. With a subset of our full features, users can easily enable or disable Don’t Interrupt and manage overrides directly within Teams.
Donut: This offer from Donut Technologies makes strategic connections in Microsoft Teams to achieve common goals and better outcomes. Donut will pair everyone on the team and send a message prompting them to connect — they can open a chat or video call in Teams or find a time to meet using the Teams calendar.
ELIGO eVoting: ELIGO eVoting by ID Technology is a secure election management platform that digitizes and automates the entire process. Catering to public and private organizations, ELIGO eVoting meets legal requirements, ensuring legally valid election results. Microsoft Teams users will benefit from an integrated voting experience that’s secure and anonymous.
Enjo: From Troopr Labs, Enjo is a full-stack generative AI toolkit purpose-built for support teams. After being added to Microsoft Teams, Enjo assists in the resolution of employee requests by deeply embedding generative AI capabilities into your existing support workflow. Enjo understands user intent and retrieves relevant information from across all knowledge sources to craft human-like responses.
farBooking: From FAR Networks, farBooking helps users better organize their work, both remotely and in person, via Microsoft Outlook and Teams. Give your employees the ability to connect with colleagues, find spaces, desks, and resources, and increase productivity, all from one platform. A farBooking account is required to use this app.
GanttPRO App: GanttPRO from DPM Solutions is an online project management tool based on Gantt charts that transforms work through seamless collaboration without having to leave Microsoft Teams. Intuitive and visually appealing, GanttPRO has a short learning curve so even new team members can start working on a project in 10 to 15 minutes.
HGC UC Talk: From Deltapath Limited, HGC UC Talk allows you to call anywhere from Microsoft Teams with HGC Softphone or the HGC Mobile App. Outgoing calls launch the HGC UC Softphone or HGC UC Mobile App. A subscription to HGC UC Softphone or HGC UC Mobile App is required.
HiHello Email Signatures: Email signatures from HiHello allow organizations to ensure that every email sent presents a professional and consistent brand experience. Admins can create custom email signatures and instantly deploy them to everyone at your company for a consistent, beautiful email experience.
Jambo: Jambo for Microsoft Outlook enables fast and easy creation of new communication records for your Jambo projects, saving you time and effort. When you send emails, this add-in lets you easily log the interaction.
JobPts for Outlook Add-In: Designed to seamlessly integrate colleague appreciation into your email workflow, the JobPts add-in for Microsoft Outlook lets you choose the recognition type, recipient, and message with just a few clicks.
KeeperAI: The KeeperAI add-in for Microsoft 365, Teams, and Outlook enables you to build meaningful connections within your virtual workspace. KeeperAI does this by helping you understand colleagues’ personalities and soft skills. This add-in requires a KeeperAI account.
Lexter.ai: The Lexter.ai assistant for Microsoft Word empowers lawyers with AI-driven features enabling them to optimize daily practices. Lexter.ai simplifies the creation of legal documents, saving time and effort, while also providing enhanced search capabilities within its internal document repository.
Macroplot Link for Excel: Economists, macroeconomic analysts, and financial analysts can use Macroplot Link for Excel to easily import time series data FRED, New York Fed, BIS, World Bank, WITS, and ECB. It also supports national sources from Uruguay (BCU, INE, BEVSA, DNA), Argentina (BCRA, datos.gob.ar), and Brazil (BCB).
Maileva: Available in French, Maileva by Docaposte supports fast preparation of shipments for La Poste, France’s universal postal service provider. Maileva can take care of printing, preparing, and delivering traditional mail to the post office or send your registered mail 100% electronically.
mybrand.center: This add-in from RGN Brand Identity Services simplifies the selection and integration of uploaded and tagged assets from the mybrand.center application. With a paid subscription, users gain access to a beautiful library of branded images to effortlessly enhance Microsoft 365 documents.
News Scroller: This web part by Prakash Software Solutions turns your Microsoft SharePoint site into an engaging, information-rich hub. Enjoy dynamic, customizable, and interactive new updates that will captivate readers.
Overview by Frameable: This simple dashboard for Microsoft Teams surfaces your most important chats, channels, files, meetings, and ongoing calls. Save valuable time with a view of new messages, calls, and meetings, all on one page. Unlock total flexibility to add, move, or hide columns to fit your work style.
Peliqan.io: Paliqan.io syncs your data from business applications such as CRM, ERP, finance, and accounting tools into Microsoft Excel, centralizing it into a data warehouse. Get a complete view of your customers, products, and invoices, and analyze further and build reports with just a few clicks.
Pixel Art: This app from Digital Inspiration creates stunning pixel art using Microsoft Excel. Simply upload an image and watch as it’s transformed into a grid of colored pixels within your spreadsheet.
ProFile – Large File Exchange: This solution from Mevitco lets you send and receive large files that aren’t suitable for email. It features integrated and self-updated antivirus protection, configurable file extensions, and native Microsoft Entra ID integration. There’s no file size limit, and transfers auto-retry when connections are lost.
Rowsie AI: Rowsie helps you understand, build, and update Microsoft Excel modes with ease. Ask it anything about your spreadsheets, from model logic to deciphering complex formulas. Rowsie can craft formulas, clean up formatting, and even build new models from scratch.
Seleam: This fixed assets management platform manages physical assets and consumables. By providing accurate tracking and reducing waste, Seleam helps enterprises optimize spending. Employees can even view and manage fixed assets assigned to them and request repairs, apply for new assets, and initiate asset handover.
Sidekick: A companion app to the XOPS Control Center, XOPS Sidekick gives employees contextual notifications through Microsoft Teams channels from the XOPS platform delivering Autonomous IT. Sidekick gives you a heads-up for your action items and takes care of the rest.
SigningCloud eSign: This solution from Securemetric Technology lets you securely sign and manage documents in Microsoft Teams. Sign documents from almost any device and keep track of the signing process. Once signing is complete, download a tamper-proof, digitally signed document via Teams.
Simply Stakeholders for Outlook (Restricted): Simply Stakeholders from Darzin Software creates a comprehensive record of all your stakeholder engagements so you always know who important stakeholders are, and who has been meeting with and talking to them.
Skills Copilot: Skills Copilot by Lake Union Solutions lets you record your professional skills, acquire new skills, and set career goals, it provides access to more than 98,000 skill definitions and 1.25 million job-to-skill mappings. Use it to find skilled coworkers, learn about different roles, and access training resources.
SMS2GO: Send and receive SMS messages from Microsoft Outlook with SMS2GO by CIM-Mobility. It features message scheduling, templates, and the ability to send to users in more than 150 countries.
Sortino: Investment bankers and institutional investors use Sortino to automatically build fully linked comparable companies analysis, DCFs, 3-statement models, and more. It extracts and analyzes data from many sources such as company financials, SEC filings, earning call transcripts, news, and market data.
Squadify: More than just an opinion poll or engagement tool, Squadify analyzes, tracks, and develops teams to drive optimal outcomes in performance. It spotlights issues to remove barriers to team success quickly, and translates them into clear, actionable insights that enable constructive conversations and drive results.
Swarm Phishnet: Swarm Phishnet from Autnhive is an integrated email and data transfer security platform that combines multiple layers of protection and verification to safeguard your communications. Its primary goal is to detect fraud and phishing attacks while protecting data during transfer.
Tall Emu CRM: The Tall Emu CRM add-in lets you view, edit, and upload all your document templates directly into Microsoft Word. Give your business documents a cohesive, branded look and feel by editing logos, information, and layout.
TR Legal Communication Hub: Streamline your team’s approval process with the TR Legal Communication Hub from Thomson Reuters. It enhances collaboration and efficiency with quick and easy approval management right in Microsoft Teams. Say goodbye to decision making delays and endless emails.
Trusty: Trusty makes referrals easy, allowing any member of your organization to refer talent from their network or share personal referral links to boost your brand and communicate open positions. Trusty helps your recruiting team by automating many daily tasks like announcements, referral campaigns, and more.
Viva Announcements to SharePoint Connector: Cloudwell’s solution will help you stay informed and updated with a seamless announcements experience, bringing announcements from Microsoft Viva Connections into your SharePoint intranet as a web part.
VOXO Meet: Arrange online meetings efficiently with the VOXO Meet add-in for Microsoft Outlook. Designed for VOXO platform users, it automatically creates an online meeting room for every calendar event and email, no more manual scheduling or scrambling to set up online meeting rooms.
Waybook: Waybook lets you bring all your training, onboarding, documentation, and best practices together in one place. Assign team members policies they’re responsible for and empower employees with a searchable Waybook knowledge base available anywhere using Microsoft Teams.
WellB: The WellB platform infuses moments throughout the workday with curated content that empowers and rejuvenates. It brings together global content creators to provide desk optimized exercises, mindfulness tools, and more. The world of wellbeing is now available within Microsoft Teams.
XM Fax (CA): Send faxes securely, directly from Microsoft Teams with XM Fax from OpenText. XM Fax eliminates mishandling of sensitive information by allowing users to manage document transmission without leaving Teams; no printing or device switching required. Faxes are encrypted, with centralized traceability for easier audits. Optional zero-retention settings further ensure document protection.
XM Fax (EMEA): Send faxes securely, directly from Microsoft Teams with XM Fax from OpenText. XM Fax eliminates mishandling of sensitive information by allowing users to manage document transmission without leaving Teams; no printing or device switching required. Faxes are encrypted, with centralized traceability for easier audits. Optional zero-retention settings further ensure document protection.
Microsoft Tech Community – Latest Blogs –Read More

Simplify your Windows 365 Enterprise deployment with the updated Windows 365 deployment checklist
We’re excited to announce that we’ve just released an updated Windows 365 deployment checklist in the Microsoft 365 admin center (MAC).
What is Windows 365?
Windows 365 is a cloud-based Desktop as a service (DaaS) solution that automatically creates a new type of Windows virtual machine for your customer, known as a Cloud PC. A Cloud PC is a highly available, optimized, and scalable virtual machine that provides customers with a rich Windows desktop experience. Cloud PCs are hosted in the Windows 365 service and is accessible from anywhere, on any device (Learn more about Windows 365).
Windows 365 deployment is made to be simple (to see an end-to-end deployment overview, visit Overview of Windows 365 deployment). However, we understand that our customers have unique and complex environments.
What is the Windows 365 deployment checklist?
To help you integrate Windows 365 with your existing enterprise environment, we’ve compiled learnings and best practices from the Microsoft 365 FastTrack Team, which has worked with hundreds of enterprise customers. We’re excited to offer these in an updated Windows 365 deployment checklist experience as part of the Advanced Deployment Guides in the Microsoft 365 Admin Center. This checklist will guide you as you plan, deploy, and scale Windows 365 in your environment.
The Windows 365 deployment checklist guides admins through the considerations around Azure basics, identity, networking, licensing, management, security, applications, and end user experiences that are applicable to their deployment configuration. Admins can assign tasks for each area to the responsible stakeholders and define a target date of completion. Admins can also see a summary view with an overall status to track progress against their timelines.
How can I access the Windows 365 deployment checklist?
To access the Windows Enterprise 365 checklist, visit this link or directly at https://go.microsoft.com/fwlink/?linkid=2251210.
Additional Resources:
Product Info: Windows 365 Enterprise on Microsoft.com
Microsoft Learn: What is Windows 365 Enterprise?
Microsoft Learn: Requirements for Windows 365
Access all Microsoft 365 Advanced Deployment Guides
Microsoft Tech Community – Latest Blogs –Read More

Get Rewarded for Sharing Your Experience with Azure Machine Learning
Artificial Intelligence (AI) and Machine Learning (ML) have become essential tools for businesses to stay competitive in today’s data-driven world. Whether you’re working with traditional ML or generative AI, with Microsoft Azure Machine Learning, we strive to empower your data science and app developments teams to build, fine-tune, evaluate, deploy, and manage high-quality models at scale, with confidence. The platform is built to help organizations accelerate time to value with industry-leading MLOps, open-source interoperability, responsible AI practices, integrated tools, and built-in governance, security, and compliance for running machine learning workloads anywhere. We continually improve with the valued input of our customers.
Your voice matters—help other organizations learn about Azure Machine Learning
We humbly invite our customers to get rewarded for sharing your first-hand experience working with Azure Machine Learning by writing a review on Gartner Peer Insights. Your review will not only assist other developers, data scientists, and technical decision-makers in their platform evaluation process, but also help shape the future of our platform. Thank you for your time and feedback!
Write a review and claim your reward*
*Reward: You will receive a $25 gift card, a 3-month subscription to Gartner research, or a donation to a charitable cause as a token of our appreciation.
Writing a Review is Simple:
Highlight your experience using Azure Machine Learning.
Personal emails are not accepted, so please use your business email or sign in with LinkedIn.
You must attest to not being an employee, partner, consultant, reseller, or a direct competitor of Microsoft.
Explore past reviews here: Microsoft Azure Machine Learning Reviews
What is Gartner Peer Insights?
Gartner Peer Insights is a trusted online platform where IT professionals and technology decision-makers read and write reviews and ratings for various IT software and services. Your review holds immense value in helping others make informed decisions and finding solutions that meet their unique needs.
Terms and Conditions Apply:
Your privacy is paramount, as only your role, industry, and organization size will be displayed.
The reviewer must be an Azure AI customer and be a working enterprise professional including technology decision-makers, enterprise-level users, executives, and their teams (e.g., students and freelancers are not allowed to submit a review). The reviewer must: attest to the authenticity of the review by certifying that (i) he or she is not an employee of Microsoft a partner of Microsoft or a direct competitor of Microsoft; (ii) employed by an organization with an exclusive relationship with the product being reviewed (this includes exclusive partners, value-added resellers, system integrators, and consultants); and (iii) the feedback is based entirely on his or her own personal experience with Microsoft’s Azure AI.
The offer is good only for those who submit a product review on Gartner Peer Insights and receive confirmation their review has been approved by Gartner. Limited to one reward per person. This offer is non-transferable and cannot be combined with any other offer. The offer is valid while supplies last. It is not redeemable for cash. Taxes, if there are any, are the sole responsibility of the recipient. Any gift returned as non-deliverable will not be re-sent. Please allow 6-8 weeks for shipment of your gift. Microsoft reserves the right to cancel, change, or suspend this offer at any time without notice. This offer is not applicable in Cuba, Iran, North Korea, Sudan, Syria, Crimea, Russia, and China. For more information, please refer to Gartner Peer Programs Community Guidelines.
Your Privacy Matters:
Rest assured that the respondent’s information will only be used for the purpose of mailing the gifts to recipients. For more information, please review our Microsoft Privacy Statement.
Microsoft Tech Community – Latest Blogs –Read More

Check This Out! (CTO!) Guide (November 2023)
Hi everyone! Brandon Wilson here once again with this month’s “Check This Out!” (CTO!) guide, and apologies for the delay!
These posts are only intended to be your guide, to lead you to some content of interest, and are just a way we are trying to help our readers a bit more, whether that is learning, troubleshooting, or just finding new content sources! We will give you a bit of a taste of the blog content itself, provide you a way to get to the source content directly, and help to introduce you to some other blogs you may not be aware of that you might find helpful.
From all of us on the Core Infrastructure and Security Tech Community blog team, thanks for your continued reading and support!
Title: Collecting Debug Information from Containerized Applications
Source: Ask The Performance Team
Author: Will Aftring
Publication Date: 11/17/2023
Content excerpt:
This blog post will assume that you have a fundamental understanding of Windows containers. If that isn’t the case, then then I highly recommend reading Get started: Run your first Windows container.
Many developers and IT Admins are in the midst of migrating long standing applications into containers to take advantage of the myriad of benefits made available with containerization.
NOTE: Not all applications are able to equally take advantage of the benefits of containerization. It is another tool for the toolbox to be used at your discretion.
But moving an existing application into a container can be a bit tricky. With this blog post I hope to help make that process a little bit easier for you.
Title: Bring Azure to your System Center environment: Announcing GA of SCVMM enabled by Azure Arc
Source: Azure Arc
Author: Karthik_KR07
Publication Date: 11/15/2023
Content excerpt:
At Microsoft, we’re committed to providing our customers with the tools they need to succeed wherever they are. By extending Azure services to the customer’s preferred environments like System Center, we empower customers with access to Azure’s potential along with a consistent experience across their hybrid estate.
Today we’re excited to deliver on that commitment as we announce that System Center Virtual Machine Manager (SCVMM) enabled by Azure Arc is now generally available to manage SCVMM resources in Azure.
Title: The first Windows Server 2012/R2 ESU Patches are out! Are you protected?
Source: Azure Arc
Author: Aurnov Chattopadhyay
Publication Date: 11/27/2023
Content excerpt:
It’s been almost two weeks since the first post-End of Life Patch Tuesday for Windows Server 2012/R2. To receive that critical security patch from November’s Patch Tuesday, your servers must be enrolled in Extended Security Updates. Fortunately, it’s not too late. You can enroll in WS2012 ESUs enabled by Azure Arc anytime, with just a few steps!
Title: Discover the latest Azure optimization skilling resources
Source: Azure Architecture
Author: Megan Pennie
Publication Date: 11/8/2023
Content excerpt:
Optimizing your Azure cloud investments is crucial for your organization’s success, helping you minimize unnecessary expenses, and ultimately drive better ROI. At Microsoft, we’re committed to optimizing your Azure environments and teaching you how to do it with resources, tools, and guidance, supporting continuous improvement of your cloud architectures and workloads, in both new and existing projects. We want you to gain confidence to reach your cloud goals, to become more effective and efficient when you have a better grasp of how to work in the cloud most successfully. To do that, our wide range of optimization skilling opportunities help you confidently achieve your cloud goals, resulting in more effectiveness and efficiency through a deeper knowledge of successful cloud operations.
Title: Deepening Well-Architected guidance for workloads hosted on Azure
Source: Azure Architecture
Author: Uli Homann
Publication Date: 11/14/2023
Content excerpt:
I am excited to announce a comprehensive refresh of the Well-Architected Framework for designing and running optimized workloads on Azure. Customers will not only get great, consistent guidance for making architectural trade-offs for their workloads, but they’ll also have much more precise instructions on how to implement this guidance within the context of their organization.
Title: Start Your Cloud Adoption Journey with the New Azure Expert Assessment Offering!
Source: Azure Architecture
Author: Pratima Sharma
Publication Date: 11/28/2023
Content excerpt:
Are you looking for a way to accelerate your cloud journey and optimize your IT infrastructure, data, and applications? If so, you might be interested in the Brand New Azure Expert Assessment Offering! It is being launched as a new option within the Microsoft Solution Assessment Program. This is a free one-to-one offering from Microsoft that helps you plan your cloud adoption by collaborating with a Certified Azure Expert who will personally guide you through the assessment, and will make remediation recommendations for your organization.
Title: Reduce Compute Costs by Pausing VMs (now in public preview)
Source: Azure Compute
Author: Ankit Jain
Publication Date: 11/15/2023
Content excerpt:
We are excited to announce that Azure is making it easier for customers to reduce Compute costs by providing them the ability to hibernate Virtual Machines (VMs). Starting today, customers can hibernate their VMs and resume them at a later time. Hibernating a VM deallocates the machine while persisting the VM’s in-memory state. While the VM is hibernated, customers don’t pay for the Compute costs associated with the VM and only pay for storage and networking resources associated with the VM. Customers can later start back these VMs when needed and all their apps and processes that were previously running simply resume from their last state.
Title: Security and ransomware protection with Azure Backup
Source: Azure Governance and Management
Author: Utsav Raghuvanshi
Publication Date: 11/17/2023
Content excerpt:
Ransomware attacks can cause significant damage to organizations and individuals, including data loss, security breaches, and costly business disruptions. When successful, they can disable a business’ core IT infrastructure, and cause destruction that could have a debilitating impact on the physical, economic security or safety of a business. And unfortunately, over the last few years, the number of ransomware attacks have seen a significant growth in their numbers as well as their sophistication. Having a sound BCDR strategy in place is essential to meeting your overall goals when it comes to ensuring security against ransomware attacks and minimizing their possible impact on your business. To make sure all customers are well protected against such attacks, Azure Backup provides a host of capabilities, some built-in while others optional, that significantly improve the security of your backups. In this article, we discuss some such capabilities offered by Azure Backup that can help you prepare better to recover from ransomware attacks as well as other data loss scenarios.
Title: Improve visibility into workload-related spend using Copilot in Microsoft Cost Management
Source: Azure Governance and Management
Author: Antonio Ortoll
Publication Date: 11/20/2023
Content excerpt:
Reducing spend is more important than ever given today’s dynamic economy. Today’s businesses strive to create efficiencies that safeguard against unpredictable shifts in the economy, beat competitors, and prioritize what matters most. But accomplishing this is less about cutting costs and more about the ability to continuously optimize your cloud investments. Continuous optimization can help you drive innovation, productivity, and agility and realize an ongoing cycle of growth and innovation in your business.
Title: Using Azure Site Recovery & Microsoft Defender for Servers to securely failover to malware-free VMs
Source: Azure Governance and Management
Author: Utsav Raghuvanshi
Publication Date: 11/29/2023
Content excerpt:
In this article, we will see how Azure Site Recovery offers an automated way to help you ensure that all your DR data, to which you would fail over, is safe and free of any malware using Microsoft Defender for Cloud.
Azure Site Recovery helps ensure business continuity by keeping business apps and workloads running during outages. Site Recovery replicates workloads running on physical and virtual machines (VMs) from a primary site to a secondary location. After the primary location is running again, you can fail back to it. Azure Site Recovery provides Recovery Plans to impose order, and automate the actions needed at each step, using Azure Automation runbooks for failover to Azure, or scripts.
Title: Accelerate Innovation with Azure Migrate and Modernize and Azure Innovate
Source: Azure Migration and Modernization
Author: Cyril Belikoff
Publication Date: 11/15/2023
Content excerpt:
In July this year, we announced the launch of Azure Migrate and Modernize, and Azure Innovate, our flagship offerings to help accelerate your move to the cloud. Azure Migrate and Modernize helps you migrate and modernize your existing applications, data and infrastructure to Azure, while Azure Innovate helps you with your advanced innovation needs such as infusing AI into your apps and experiences, advanced analytics, and building custom cloud native applications.
Title: Secure your subnet via private subnet and explicit outbound methods
Source: Azure Networking
Author: Brian Lehr, Aimee Littleton
Publication Date: 11/16/2023
Content excerpt:
While there are multiple methods for obtaining explicit outbound connectivity to the internet from your virtual machines on Azure, there is also one method for implicit outbound connectivity – default outbound access. When virtual machines (VMs) are created in a virtual network without any explicit outbound connectivity, they are assigned a default outbound public IP address. These IP addresses may seem convenient, but they have a number of issues and therefore are only used as a “last resort”…
Title: Understanding Azure DDoS Protection: A Closer Look
Source: Azure Network Security
Author: David Frazee
Publication Date: 11/15/2023
Content excerpt:
Azure DDoS Protection is a service that constantly innovates itself to protect customers from ever-changing distributed denial-of-service (DDoS) attacks. One of the major challenges of cloud computing is ensuring customer solutions maintain security and application availability. Microsoft has been addressing this challenge with its Azure DDoS Protection service, which was launched in public preview in 2017 and became generally available in 2018. Since its inception, Microsoft has renamed its Azure DDoS Protection service to better reflect its capabilities and features. We’ll discuss how this protection service has transformed through the years and provide more insights into the levels of protection offered by the separate tiers.
Title: 2023 Holiday DDoS Protection Guide
Source: Azure Network Security
Author: Amir Dahan
Publication Date: 11/21/2023
Content excerpt:
As the holiday season approaches, businesses and organizations should brace for an increase in Distributed Denial of Service (DDoS) attacks. Historically, this period has seen a spike in such attacks, targeting sectors like e-commerce and gaming that experience heightened activity. DDoS threats persist throughout the year, but the holiday season’s unique combination of increased online activity and heightened cyber threats makes it a critical time for heightened vigilance.
Title: Personal Desktop Autoscale on Azure Virtual Desktop generally available
Source: Azure Virtual Desktop
Author: Jessie Duan
Publication Date: 11/28/2023
Content excerpt:
We are excited to announce that Personal Desktop Autoscale on Azure Virtual Desktop is generally available as of November 15, 2023! With this feature, organizations with personal host pools can optimize costs by shutting down or hibernating idle session hosts, while ensuring that session hosts can be started when needed.
Title: Microsoft Assessments – Milestones
Source: Core Infrastructure and Security
Author: Felipe Binotto
Publication Date: 11/7/2023
Content excerpt:
In this post, I want to talk about Microsoft Assessments but more specifically Microsoft Assessments Milestones because they are a very useful tool which is not widely used.
In case you don’t know what Microsoft Assessments are, they are a free, online platform that helps you evaluate your business strategies and workloads. They work through a series of questions and recommendations that result in a curated guidance report that is actionable and informative.
Title: Azure MMA Agent Bulk Removal
Source: Core Infrastructure and Security
Author: Paul Bergson
Publication Date: 11/13/2023
Content excerpt:
In the following sections of this blog, I will provide a step-by-step guide to help you migrate away from MMA to AMA. This guide is designed to make the transition as smooth and seamless as possible, minimizing any potential disruptions to your monitoring workflow.
But that is not all. To make things even easier, there is a GitHub site that hosts the necessary binaries for this migration process. These binaries will be used to install a set of utilities in Azure, including a process dashboard. This dashboard will provide you with a visual representation of the migration process, making it easier to track and manage.
Title: Active Directory Hardening Series – Part 2 – Removing SMBv1
Source: Core Infrastructure and Security
Author: Jerry Devore
Publication Date: 11/20/2023
Content excerpt:
Ok, let’s get into today’s topic which is removing SMBv1 from domain controllers. Like my previous blog on NTLM, a lot of great content has already been written on SMBv1. My objective is to not to rehash the why but rather focus on how you can take action in a production environment.
Title: The Twelve Days of Blog-mas: No.1 – A Creative Use for Intune Remediations
Source: Core Infrastructure and Security
Author: Michael Hildebrand
Publication Date: 11/28/2023
Content excerpt:
For Post #1, I offer to you a quick’n’easy way to use Intune Remediations to get some info from Windows PCs.
Last reboot dates/times are frequently used as simple indicators of life for devices. I was asked if this is captured anywhere in Intune and oddly, I’d never looked – but as I went hunting through Intune (Portal and Graph), the more I looked, the more I couldn’t find it anywhere obvious. “Surely it can’t be THIS hard…?“
Title: Connecting to Azure Services on the Microsoft Global Network
Source: Core Infrastructure and Security
Author: Preston Romney
Publication Date: 11/28/2023
Content excerpt:
Azure Services and the solutions you deploy into Azure are connected to the Microsoft global wide-area network also known as the Microsoft Global Network or the Azure Backbone. There are a few different ways to connect to an Azure service from a subnet, depending on your requirements around securing access to these services. Your requirements should dictate which method you choose. There are some common misconceptions around connectivity, and the goal of this article is to provide some clarity around connecting to Azure Services.
Title: The Twelve Days of Blog-mas: No.2 – Windows Web Sign in and Passwordless
Source: Core Infrastructure and Security
Author: Michael Hildebrand
Publication Date: 11/29/2023
Content excerpt:
Hi folks – welcome to the second post in the holiday ’23 series.
Today’s post is about a capability that came to preview long ago but recently surprised much of the world and moved to General Availability (GA).
Title: The Twelve Days of Blog-mas: No.3 – Windows Local Admin Password Solution (LAPS)
Source: Core Infrastructure and Security
Author: Michael Hildebrand
Publication Date: 11/30/2023
Content excerpt:
Buenos días and welcome to número tres in the holiday ’23 series.
This one is sure to please the crowd – it’s the NEW AND IMPROVED easy to setup/deploy/use solution for when IT Ops/Support needs a local admin ID and password to perform some management task(s) on a Windows endpoint.
Title: First Party Services Adoption for Migrated Virtual Machines via Azure Policy
Source: FastTrack for Azure
Author: Alejandra8481
Publication Date: 11/2/2023
Content excerpt:
Server migrations to Azure Virtual Machines either through Azure Migrate or via a redeploy approach can benefit from Azure policies to accelerate adoption of Azure first party services across BCDR, Security, Monitoring and Management.
Our Cloud Adoption Framework’s guidance for Azure Landing Zones already provides a good baseline of recommended Azure policies. However, a variation to this baseline is described in this article with a focus on newly migrated Azure Virtual Machine resources.
Title: Windows Events, how to collect them in Sentinel and which way is preferred to detect Incidents
Source: FastTrack for Azure
Author: Lizet Pena De Sola
Publication Date: 11/20/2023
Content excerpt:
How can a SOC team ingest and analyze Windows Logs with Microsoft Sentinel? What are the main options to ingest Windows Logs into a Log Analytics Workspace and use Microsoft Sentinel as a SIEM to manage security incidents from events recorded on these logs?
Read on to find out!
Title: Step-by-Step : Assign access packages automatically based on user properties in Microsoft Entra ID
Source: ITOps Talk
Author: Dishan Francis
Publication Date: 11/27/2023
Content excerpt:
Traditionally, during the setup of an access package, you could specify who can request access, including users and groups in the organization’s directory or guest users. Now, you have the option to use an automatic assignment policy to manage access packages. This policy includes membership rules that evaluate user attribute values to determine access. You can create one automatic assignment policy per access package, which can assess built-in user attributes or custom attribute values generated by third-party HR systems and on-premises directories. Behind the scenes, Entitlement Management automatically creates dynamic security groups based on the policy rules, which are adjusted as the rules change.
Title: Extended Security Updates (ESUs): Online or proxy activation
Source: Windows IT Pro
Author: Poornima Priyadarshini
Publication Date: 11/9/2023
Content excerpt:
When your Windows products reach the end of support, Extended Security Updates (ESUs) are there to protect your organization while you modernize your estate. To take advantage of this optional service, you’d purchase and download ESU product keys, install them, and finally activate the extended support.
Title: Windows Server 2012/R2: Extended Security Updates
Source: Windows IT Pro
Author: Poornima Priyadarshini
Publication Date: 11/9/2023
Content excerpt:
You can now get three additional years of Extended Security Updates (ESUs) if you need more time to upgrade and modernize your Windows Server 2012, Windows Server R2, or Windows Embedded Server 2012 R2 on Azure. This also applies to Azure Stack HCI, Azure Stack Hub, and other Azure products.
Title: Universal Print makes cloud printing truly “universal”
Source: Windows IT Pro
Author: Robert Cunningham
Publication Date: 11/15/2023
Content excerpt:
Universal Print is a cloud-based print solution that enables a simple, rich, and secure print experience for users while also reducing time and effort for IT pros. By shifting print management to the cloud, IT professionals can simplify administration and end-users can easily print, reducing the expense of organizations’ print infrastructure.
Title: Copilot coming to Windows 10
Source: Windows IT Pro
Author: Alan Meeus
Publication Date: 11/20/2023
Content excerpt:
Today, we start to roll out Copilot in Windows (in preview) for Windows 10, version 22H2 to Windows Insiders in the Release Preview Channel. Bringing Copilot to Windows 10 enables organizations managing both Windows 11 and Windows 10 devices to continue considering a rollout of Copilot in Windows and provide this powerful productivity experience to more of their workforce.
Previous CTO! Guides:
CIS Tech Community-Check This Out! (CTO!) Guides
Additional resources:
Azure documentation
Azure pricing calculator (VERY handy!)
Microsoft Azure Well-Architected Framework
Microsoft Cloud Adoption Framework
Windows Server documentation
Windows client documentation for IT Pros
PowerShell documentation
Core Infrastructure and Security blog
Microsoft Tech Community blogs
Microsoft technical documentation (Microsoft Docs)
Sysinternals blog
Microsoft Learn
Microsoft Support (Knowledge Base)
Microsoft Archived Content (MSDN/TechNet blogs, MSDN Magazine, MSDN Newsletter, TechNet Newsletter)
Microsoft Tech Community – Latest Blogs –Read More
Lesson Learned #462: Understanding the Key Updates in SQL Server Management Studio (SSMS) 19.1
Introduction:
SQL Server Management Studio (SSMS) 19.1 has introduced a range of updates and changes, enhancing its database management capabilities. This article provides a summary of these changes, offering insights into how they impact the functionality and user experience of SSMS.
1. Driver Updates and Configuration Changes:
SSMS 19.1 features a significant shift from System.Data.Sqlclient (SDS) to Microsoft.Data.Sqlclient (MDS), impacting how SQL Server connections are managed. This change includes validation of certificates, a new feature in MDS 3.x not present in SDS 3.x. For more details, see the full article.
2. Authentication Library Transition:
The migration from Azure Active Directory Authentication Library (ADAL) to Microsoft Authentication Library (MSAL) is another critical update. This transition responds to the end of support and development for ADAL, with MSAL offering updated capabilities aligned with the Microsoft identity platform endpoint. For further information, refer to the Microsoft Tech Community article.
3. SQL Vulnerability Assessment Removal:
The SQL Vulnerability Assessment feature has been removed from SSMS 19.1 and incorporated into Microsoft Defender for SQL. This change aims to provide real-time updates and consistent vulnerability scanning across cloud and on-premises resources. Detailed information can be found in the Part 2 of the SSMS 19.1 changes series.
4. Startup Time Improvements:
Efforts to reduce the startup time of SSMS have been made, including delaying the output window’s initialization. These improvements are part of ongoing enhancements to optimize the tool’s performance. For more insights, check the detailed blog post.
5. “Can’t Reach This Page” Error:
A common issue in SSMS 19.1, especially in restricted network environments, is the “Can’t reach this page” error when using Microsoft Entra authentication. This problem stems from the default browser setting change in SSMS 19.1. Solutions and explanations for this issue are provided in the dedicated blog post.
URLs:
SSMS 19 driver changes (microsoft.com)
SSMS 19.1 (microsoft.com)
SSMS 19.1 New Features (microsoft.com)
Azure Data Studio 1.46 (microsoft.com)
Can’t reach this page (microsoft.com)
Microsoft Tech Community – Latest Blogs –Read More
Lesson Learned #461:Effective Load Balancing in Azure SQL Database: A Practical Approach
In today’s data-driven landscape, we are presented with numerous alternatives like Elastic Queries, Data Sync, Geo-Replication, ReadScale, etc., for distributing data across multiple databases. However, in this approach, I’d like to explore a slightly different path: creating two separate databases containing data from the years 2021 and 2022, respectively, and querying them simultaneously to fetch results. This method introduces a unique perspective in data distribution — partitioning by database, which could potentially lead to more efficient resource utilization and enhanced performance for each database. While partitioning within a single database is a common practice, this idea ventures into partitioning across databases.
Background:
As data accumulates over time, the strain on a single database intensifies, often leading to slower query responses and potential bottlenecks. Load balancing, a critical concept in database management, offers a remedy by evenly distributing the data load across multiple servers or databases, thus enhancing performance and ensuring scalability.
Solution Overview:
Our approach entails a distributed database architecture where separate Azure SQL databases are designated for different years (e.g., 2021 and 2022). This setup not only simplifies data management but also strategically distributes the read load. The technology stack for this solution involves C#, Azure SQL Database, and the .NET framework.
Implementation:
Database Setup: We established two Azure SQL databases, each storing data for a specific year. This division allows for a focused and organized data structure.
C# Application Structure: The core of our application is the ClsLoadData class, which is responsible for connecting to and querying the databases. This class demonstrates effective organization and clarity in its purpose.
Connection String Mapping: A crucial aspect of our implementation is the mapping of different years to specific database connection strings within the C# application. This mapping ensures that queries are directed to the correct database.
Asynchronous Data Retrieval: We employed asynchronous programming in C#, using async and await, for efficient and non-blocking data retrieval. This approach is particularly beneficial in maintaining application responsiveness.
Retry Logic: To enhance robustness, we implemented a retry logic mechanism, which is vital in handling transient failures and ensuring reliable database connectivity.
Load Balancing in Action:
Parallel Execution: By querying both databases simultaneously, our application effectively distributes the read load. This parallel execution is key in maximizing performance and reducing the overall strain on each database.
Performance Benefits: The observed performance benefits were significant. We noted faster response times and a marked reduction in load on each individual database, confirming the efficacy of our load balancing strategy.
Lessons Learned:
Scalability: This approach scales seamlessly with additional databases and larger datasets. It proves that load balancing is not just a theoretical concept but a practical solution for growing data demands.
Maintainability: The ease of maintaining and updating separate databases was another critical takeaway. This architecture simplifies data management and enhances overall system maintainability.
Best Practices: Key best practices include thorough exception handling and secure management of connection strings. These practices are essential in safeguarding the application and ensuring its smooth operation.
Conclusion:
In summary, this implementation of load balancing using C# and Azure SQL Database not only addressed the challenge of managing large datasets but also offered insights into scalable, maintainable database architecture. The lessons learned and best practices identified here serve as valuable guides for similar scenarios.
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.Data.SqlClient;
using System.Threading.Tasks;
using System.Threading;
namespace DockerHealth
{
class ClsLoadData
{
public async Task Main()
{
// Define a dictionary mapping years to specific connection strings
var yearConnectionMappings = new Dictionary<int, string>
{
{ 2021, “Server=tcp:servername1.database.windows.net,1433; User Id=usrname;Password=Pwd1!;Initial Catalog=db1;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2021”},
{ 2022, “Server=tcp:servername2.database.windows.net,1433; User Id=usrname;Password=Pwd2!;Initial Catalog=db2;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2022” }
};
var tasks = new List<Task<List<MyEntity>>>();
foreach (var mapping in yearConnectionMappings)
{
int year = mapping.Key;
string connectionString = mapping.Value;
tasks.Add(FilterByYear(year, connectionString));
}
var results = await Task.WhenAll(tasks);
// Combine all results into a single set
var combinedResults = new List<MyEntity>();
foreach (var result in results)
{
combinedResults.AddRange(result);
}
// Display the results
DisplayResults(combinedResults);
Console.WriteLine(“end”);
}
static async Task<List<MyEntity>> FilterByYear(int year, string connectionString)
{
string query = “SELECT [Year], ID, Cost, Unit FROM [Values] WHERE [Year] = @year”;
List<MyEntity> results = new List<MyEntity>();
int maxRetries = 3; // Maximum number of retries
int delay = 1000; // Initial delay in milliseconds (1 second)
for (int retry = 0; retry < maxRetries; retry++)
{
try
{
using (SqlConnection connection = new SqlConnection(connectionString))
{
await connection.OpenAsync();
using (SqlCommand command = new SqlCommand(query, connection))
{
command.Parameters.AddWithValue(“@year”, year);
using (SqlDataReader reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
int readYear = (int)reader[“Year”];
int id = (int)reader[“ID”];
decimal cost = (decimal)reader[“Cost”];
int unit = (int)reader[“Unit”];
var entity = new MyEntity(readYear, id, cost, unit);
results.Add(entity);
}
}
}
}
break; // Break the loop on successful execution
}
catch (Exception ex)
{
if (retry == maxRetries – 1) break; // Rethrow the exception on the last retry
await Task.Delay(delay); // Wait before retrying
delay *= 2; // Double the delay for the next retry
}
}
return results;
}
static void DisplayResults(List<MyEntity> results)
{
Console.WriteLine(“Year | ID | Cost | Unit | TotalCost”);
Console.WriteLine(“———————————–“);
foreach (var entity in results)
{
Console.WriteLine($”{entity.Year} | {entity.ID} | {entity.Cost} | {entity.Unit} | {entity.TotalCost}”);
}
}
}
class MyEntity
{
public int Year { get; set; }
public int ID { get; set; }
public decimal Cost { get; set; }
public int Unit { get; set; }
public decimal TotalCost
{
get { return Cost * Unit; }
}
// Constructor for initializing properties
public MyEntity(int year, int id, decimal cost, int unit)
{
Year = year;
ID = id;
Cost = cost;
Unit = unit;
}
}
}
TSQL Scripts
CREATE TABLE [Values] (
[Year] INT,
[ID] INT IDENTITY(1,1) PRIMARY KEY,
[Cost] DECIMAL(10, 2),
[Unit] INT
);
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2021 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2022 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
Microsoft Tech Community – Latest Blogs –Read More
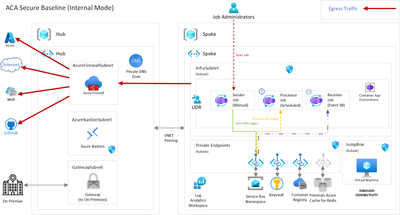
Azure Container Apps Jobs in a secure Landing Zone
Customers in their migration/modernization journey to cloud want to update their apps to be compatible with the cloud and rebuild the apps as microservices that involve tasks that run for a short time and deployed into a secure container infrastructure and ready for production. For these scenarios, Azure Container Apps Landing Zone Accelerator can help the users start with the best practices included to speed up their production process.
Azure Container Apps (ACA) Landing Zone Accelerator provides packaged design guidance on critical design areas with reference architecture backed by reference implementation to help users build and deploy containerized apps to Azure Container Apps in an enterprise landing zone design. Landing Zone Accelerator has been built on the lessons we learned with our customer engagements so you can leverage the design recommendations and considerations without reinventing the wheel.
Design Guidance is published for 4 critical design areas namely Identity, Networking, Security, Management and Operations.
Azure Container Apps is built on top of powerful open-source technologies like KEDA, Dapr, Kubernetes, envoy providing the easiest and quickest path to host the containerized workloads empowering developers to focus on the apps not exposed to the complexities of Kubernetes.
Jobs in Azure Container Apps
Azure Container Apps Jobs allow you to run containerized tasks that execute for a given duration and complete. You can use jobs to run tasks such as data processing, machine learning, or any scenario where on-demand processing is required.
For more information, see the following tutorials:
Create a job with Azure Container Apps: In this tutorial, you create a manual or scheduled job.
Deploy an event-driven job with Azure Container Apps: shows how to create a job whose execution is triggered by each message that is sent to an Azure Storage Queue.
Deploy self-hosted CI/CD runners and agents with Azure Container Apps jobs shows how to run a GitHub Actions self-hosted runner as an event-driven Azure Container Apps Job.
Job trigger types
There are three different types of triggers that start the job and below are the available triggers.
Manual jobs – Manual jobs are triggered on-demand using the Azure CLI, through the Azure portal or a request to the Azure Resource Manager API.
Scheduled Jobs – Scheduled jobs are triggered at specific times and can run repeatedly using Cron expressions to define schedules. They support the standard cron expression format with five fields for minute, hour, day of month, month, and day of week. Cron expressions in scheduled jobs are evaluated in Universal Time Coordinated (UTC). The following are examples of cron expressions:
Expression
Description
0 */2 * * *
Runs every two hours.
0 0 * * *
Runs every day at midnight.
0 0 * * 0
Runs every Sunday at midnight.
0 0 1 * *
Runs on the first day of every month at midnight.
Event driven jobs
Event-driven jobs are triggered by events from supported custom scalers. Examples include like when a new message is added to a queue; a self-hosted GitHub Actions runner or Azure DevOps agent that runs when a new job is queued in a workflow or pipeline.
Reference Architecture
The reference implementation demonstrates the jobs feature within the context of Azure Container Apps landing zone accelerator, a secure baseline infrastructure architecture for a microservices workload deployed into Azure Container Apps. Specifically, this scenario addresses employing 3 types of Jobs, a manual triggered, a schedule triggered, and an event triggered one with basic functionality deploying Azure Container Apps Jobs into a virtual network with no public endpoint.
Jobs bicep implementation
The sample is deployed to Azure using a bicep template found at the root directory and named main.bicep. This, besides deploying the Service Bus namespace, deploys:
The Manual Container Apps Job
To deploy a manual triggered job in bicep you need to define a manualTriggerConfig at the configuration section of the container app and set the triggerType to ‘Manual’.
The Scheduled Container Apps Job
Similar to the manual triggered job to deploy a scheduled one you need to define a scheduleTriggerConfig at the configuration section of the container app and set the triggerType to ‘Schedule’
The Event triggered Container Apps Job
To deploy an event triggered job in bicep you need to define an eventTriggerConfig at the configuration section of the container app and set the triggerType to ‘Event’.
Deployment
To deploy the sample jobs apps into the Azure container apps in a secure landing zone, follow the below steps
Deploy the secure baseline following the pre-requisites documentation.
Since the Container Apps Environment is completely internal and the container registry is not available through the internet, you will need to perform the deployment steps for the container image steps through the VM jumphost at the spoke virtual network for which the ACR is available.
Follow the deployment steps to build and push the container to ACR, deploy the jobs and when the deployment completes 4 additional resources namely 3 jobs and 1 service bus would be seen in the portal view.
Observability
To continuously monitor and observe the state of your app, you can utilize the built-in observability features like Log Streaming, Container Console, Azure Monitor metrics, Application logging, Azure Monitor Log Analytics and Azure Monitor alerts
In the landing zone accelerator, the receiver job in the sample app will poll the result queue for new messages. Once the processor has processed the incoming messages it will post them there.
To get the results, navigate to the execution logs and run the following query.
ContainerAppConsoleLogs
| where ContainerGroupName startswith ‘lzaacajobs-receiver’
| project TimeGenerated, Log
ACA Landing Zone simplifies the process of running jobs at scale in a serverless containers environment. With the secure baseline, it provides a secure and compliant environment for running jobs.
To learn more, visit our official GitHub repository here with detailed step by step guidance to deploy the Jobs in a landing zone. We welcome your feedback and do submit an issue with your ideas.
A big thank you goes to @Konstantinos Pantos for contributing to the Jobs scenario in landing zone.
If you like this blog post, be sure to share it with other people who may be interested to learn more about landing zone accelerators.
Microsoft Tech Community – Latest Blogs –Read More

Key Takeaways from Creating Transactable Offers on Azure Marketplace
In our recent session on creating transactable offers on the Azure Marketplace, our subject matter experts provided guidance on the process of creating pricing for your solutions on the Azure Marketplace, how to choose the best offer type for your solution, and how to set the optimal price for your offer. Here are some of the top takeaways from the presentation by Christine Brown and Julio Colon, from Microsoft’s marketplace team.
There are many benefits to publishing a transactable offer on the marketplace, such as reaching a large customer base, leveraging Microsoft’s billing and tax services, and accessing various partner programs and incentives.
You can reach millions of customers who use the Microsoft marketplace to find and buy solutions that meet their needs.
You can leverage Microsoft’s billing and commerce capabilities to handle the transactions, invoicing, and tax remittance for you.
You can offer different pricing options, such as flat rate, per user, per meter, or reservation pricing, to suit your business model and customer preferences.
You can create private plans or private offers to customize your pricing and terms for specific customers or markets.
You can test your offer before publishing it to ensure that it works as expected and provides a seamless customer experience.
Access to a large and global customer base of over 75 million buyers
Increased visibility and discoverability of your solution
Enhanced customer experience and trust
Opportunity to participate in co-selling and co-marketing programs with Microsoft and partners
There are a few different types of transactable offers, such as software as a service (SAS), virtual machines (VM), containers, and Azure managed apps, and their key features and options.
SaaS (Software as a service): This is the most common offer type, where your solution runs in your own tenant and customers access it through a web browser or an app. You can charge a flat rate or per user, and you can use meters to track variable usage. You can also integrate with Azure Active Directory, Microsoft 365, and other Microsoft services.
VM: Virtual machine. This is where your solution runs in the customer’s tenant as a virtual machine image. You can charge per hour, per CPU, per market, or per reservation. You can also offer different VM sizes and configurations.
Container: This is where your solution runs in the customer’s tenant as a containerized application on a Kubernetes cluster. You can charge per core, per node, per pod, or per cluster. You can also use custom meters to track usage based on your own metrics.
Managed app: This is where your solution runs in the customer’s tenant as a fully managed application that you can monitor and update. You can charge a flat rate per month and use meters to track variable usage. You can also offer different service levels and support options.
The webinar walked through the steps to create a transactable offer in the Partner Center, such as choosing an offer type, setting up the offer details, configuring the technical aspects, creating plans and pricing, and publishing the offer.
Best practices and tips for designing and pricing your plans include considering your target markets, customer segments, usage levels, and billing terms, and using meters and variables to charge for different aspects of your solution.
Think about how you want to sell and market your solution to your customers and what value proposition you offer them.
Choose the appropriate offer type for your solution, whether it is SaaS, VM, container, or managed app, and understand the technical configuration and requirements for each one.
Decide on the billing terms and pricing models that suit your solution and your customers’ needs. Some of these options include flat rate, per user, per CPU, and custom meters, depending on the offer type.
Select the markets where you want to sell your solution and be aware of the tax implications and currency conversions for each country.
Create multiple plans to offer different levels of service, features, or discounts to your customers. You can use the plan name, description, and summary to highlight the differences and benefits of each plan.
Test your plan before publishing it to make sure it works as expected and you can track the usage and billing correctly. You can use the private plan option and the preview audience feature to do a test purchase.
Review and publish your offer and make sure it passes the validation check and meets the certification criteria.
We covered the scenarios and examples of how to use different pricing models and options, such as flat rate, per user, per market, per vCPU, reservation pricing, and custom meters, and how to adjust them for different customer needs and preferences.
Flat rate: This is a fixed price for the entire offer, regardless of the usage or consumption. It can be used for SaaS, VM, or managed app offers. It can have different billing terms, such as one month, one year, two year, or three year. It can also have variable pricing based on meters, such as number of reports, invoices, or API calls. The publisher needs to track and report the usage of these meters to Microsoft.
Per user: This is a price based on the number of users or licenses that the customer purchases. It can be used only for SaaS offers. It can have different billing terms, such as one month, one year, two year, or three year. It can also have minimum and maximum number of users. The publisher needs to track and report the number of users to Microsoft.
Per market: This is a price based on the country or region where the customer is located. It can be used for VM or container offers. The publisher can select the markets where they want to sell their offer and set different prices for each market. Microsoft will do the currency conversion and tax remittance for some markets.
Per vCPU: This is a price based on the number of CPU cores or hours that the offer uses. It can be used for VM or container offers. The publisher can set different prices for different CPU sizes or types. Microsoft will track and bill the customer based on the CPU usage.
There are many resources and tools available to help you build, publish, and grow your transactable offer, such as the Mastering the Marketplace website, the Marketplace Community, the Marketplace Rewards program, and the ISV Success program.
Register to watch the recording! For more takeaways and more detailed info on those takeaways listed above, register to watch the recording.
Have follow up questions about this presentation’s content? Comment below to continue the conversation with our subject matter experts!
__________________________________________________________________________________________________________________________________________
Stay updated on upcoming marketplace community events: fill out this form. and we will email you with updates on new community events where you can participate in live Q&A with Microsoft!
Additional Resources:
Mastering the Marketplace series
Marketplace community
Marketplace Rewards
ISV Success
Microsoft Tech Community – Latest Blogs –Read More

In Preview: New Copilot Features in Azure AI Health Bot
In the current era of Large Language Models (LLMs), there is a growing demand for AI in healthcare. Healthcare organizations are actively exploring ways to leverage these advanced technologies to develop their own GPT-powered Copilots for doctors or virtual health assistants for patients. It’s important to understand that healthcare organizations will only use these tools when they adhere to the highest security and compliance standards required for healthcare purposes
The escalating demand is driven by the recognition that AI systems can significantly enhance healthcare experiences with many different tasks, such as assisting with administrative or clinical tasks. The goal is to build intelligent and engaging chat experiences that utilizes generative AI, providing accurate, relevant, and consistent information based on credible healthcare information or validated customer sources.
To meet these evolving needs, we’ve seen that healthcare organizations are looking for a hybrid approach. This approach involves the integration of protocol-based flows alongside generative AI-based healthcare scenarios. The aim is to offer a more personalized and comprehensive service to both healthcare professionals and patient.
More importantly, this hybrid approach requires healthcare-specific safeguards. Recognizing the sensitive nature of healthcare data, it is crucial to implement measures that adhere to the quality standards of the healthcare industry. This includes leveraging grounded models, having the needed disclaimers, including evidence, include feedback system, have real-time abuse monitoring and incorporating safeguards of the information provided.
In response to these industry demands, we are excited that our team recently announced the private preview of the Azure AI Health Bot Copilot features. This expansion empowers healthcare organizations to build Copilots for their organization, leveraging the capabilities of generative AI to streamline administrative and clinical workloads.
New Copilot features in the Azure AI Health Bot
We are enabling these features by integrating the Azure AI Health bot with Azure OpenAI, Azure AI Search service and Bing Custom Search. With these integrations we are enabling the following capabilities
Generate customized responses by tapping into your own data sources. Integrate your Azure OpenAI service endpoint and Azure AI Search index to produce answers tailored to your preferred sources.
Generate responses using your own websites. Incorporate your Azure OpenAI service endpoint and Big Custom Search service to utilize trusted website content for refining the Language Model.
Harness healthcare intelligence capabilities for generative answers from reliable healthcare sources.
Make use of the Azure AI Health Bot’s built-in Credible sources, such as the National Institutes of Health (NIH)
Implement a comprehensive fallback sequence incorporating the above capabilities. Design a copilot that follows a fallback sequence if no answer is found, ensuring a robust response strategy.
All this is available through our Template Catalog. Where you are able to import one or more templates into your own bot instance. By importing these templates you recieve a validated scenario that shows how you can utilize these new features in the best way possible.
All the different templates provides a scenario that explains how to use the new Generative Answers or Healthcare Intelligence step and also shows how you can cascade from one source to another, ensuring a robust and flexible response strategy.
Adhering to healthcare security and compliance standards
The Azure AI Health Bot prioritizes security and compliance of Personal Health Information (PHI), ensuring confidentiality and integrity of sensitive health-related data and makes sure it adheres to the needed compliance standards.
The Azure AI Health Bot, which has over 50 global and regional certifications, such as GDPR, HIPAA and FedRAMP, has built-in controls for Data Subject Rights (DSRs) and compliance measures, offering a comprehensive approach to managing user data in adherence to regulatory standards.
To enable consent management, the Health Bot includes a built-in Consent Management system, facilitating the acquisition, retention, and renewal of user consents. This not only enhances the user experience but also ensures compliance with data protection regulations.
In addition to consent management, the platform provides out-of-the-box Audit Trails for a detailed analysis and traceability of changes and data access. This feature promotes transparency and accountability in the handling of health-related data.
It also incorporates automated and customizable Data Retention Policies specifically designed for conversation data. These out-of-the-box policies ensure that data retention is managed efficiently, aligning with regulatory requirements and organizational needs.
Ensuring that Generative AI is used in a responsible way
With the integration of Generative AI, we made sure every AI response generated by the Azure AI Health Bot includes a disclaimer, reinforcing transparency in AI interactions and informing users about the nature of the automated responses. To further enhance transparency, we automatically append evidence to every AI response, creating a documented trail that contributes to accountability and establishes trust in the platform’s functionalities.
With the built-in end-user feedback mechanism we allow users to provide feedback, fostering a continuous feedback loop for the improvement and refinement of the AI Health Bot’s capabilities.
The platform’s architecture also supports healthcare safeguards, including battle-tested meta-prompts and Azure Content Filtering, ensuring a secure and reliable environment for health-related interactions.
Lastly, Real-Time Abuse Monitoring is constantly monitoring and acting on problematic prompts, adding an extra layer of security by blocking and logging abusive interactions and providing an overview of potential issues.
We can’t wait to see what your organization will do with these new capabilities. Feel free to request access to the private preview of these new features here: Microsoft Forms or via the template catalog in your Azure AI Health Bot instance. (Places are limited)
We are looking forward to see how you will utilize AI to transform your way of working to reduce clinician burnout, increase patient satisfaction or improve healthcare altogether.
Microsoft Tech Community – Latest Blogs –Read More
Lesson Learned #461:Effective Load Balancing in Azure SQL Database: A Practical Approach
In today’s data-driven landscape, we are presented with numerous alternatives like Elastic Queries, Data Sync, Geo-Replication, ReadScale, etc., for distributing data across multiple databases. However, in this approach, I’d like to explore a slightly different path: creating two separate databases containing data from the years 2021 and 2022, respectively, and querying them simultaneously to fetch results. This method introduces a unique perspective in data distribution — partitioning by database, which could potentially lead to more efficient resource utilization and enhanced performance for each database. While partitioning within a single database is a common practice, this idea ventures into partitioning across databases.
Background:
As data accumulates over time, the strain on a single database intensifies, often leading to slower query responses and potential bottlenecks. Load balancing, a critical concept in database management, offers a remedy by evenly distributing the data load across multiple servers or databases, thus enhancing performance and ensuring scalability.
Solution Overview:
Our approach entails a distributed database architecture where separate Azure SQL databases are designated for different years (e.g., 2021 and 2022). This setup not only simplifies data management but also strategically distributes the read load. The technology stack for this solution involves C#, Azure SQL Database, and the .NET framework.
Implementation:
Database Setup: We established two Azure SQL databases, each storing data for a specific year. This division allows for a focused and organized data structure.
C# Application Structure: The core of our application is the ClsLoadData class, which is responsible for connecting to and querying the databases. This class demonstrates effective organization and clarity in its purpose.
Connection String Mapping: A crucial aspect of our implementation is the mapping of different years to specific database connection strings within the C# application. This mapping ensures that queries are directed to the correct database.
Asynchronous Data Retrieval: We employed asynchronous programming in C#, using async and await, for efficient and non-blocking data retrieval. This approach is particularly beneficial in maintaining application responsiveness.
Retry Logic: To enhance robustness, we implemented a retry logic mechanism, which is vital in handling transient failures and ensuring reliable database connectivity.
Load Balancing in Action:
Parallel Execution: By querying both databases simultaneously, our application effectively distributes the read load. This parallel execution is key in maximizing performance and reducing the overall strain on each database.
Performance Benefits: The observed performance benefits were significant. We noted faster response times and a marked reduction in load on each individual database, confirming the efficacy of our load balancing strategy.
Lessons Learned:
Scalability: This approach scales seamlessly with additional databases and larger datasets. It proves that load balancing is not just a theoretical concept but a practical solution for growing data demands.
Maintainability: The ease of maintaining and updating separate databases was another critical takeaway. This architecture simplifies data management and enhances overall system maintainability.
Best Practices: Key best practices include thorough exception handling and secure management of connection strings. These practices are essential in safeguarding the application and ensuring its smooth operation.
Conclusion:
In summary, this implementation of load balancing using C# and Azure SQL Database not only addressed the challenge of managing large datasets but also offered insights into scalable, maintainable database architecture. The lessons learned and best practices identified here serve as valuable guides for similar scenarios.
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.Data.SqlClient;
using System.Threading.Tasks;
using System.Threading;
namespace DockerHealth
{
class ClsLoadData
{
public async Task Main()
{
// Define a dictionary mapping years to specific connection strings
var yearConnectionMappings = new Dictionary<int, string>
{
{ 2021, “Server=tcp:servername1.database.windows.net,1433; User Id=usrname;Password=Pwd1!;Initial Catalog=db1;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2021”},
{ 2022, “Server=tcp:servername2.database.windows.net,1433; User Id=usrname;Password=Pwd2!;Initial Catalog=db2;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2022” }
};
var tasks = new List<Task<List<MyEntity>>>();
foreach (var mapping in yearConnectionMappings)
{
int year = mapping.Key;
string connectionString = mapping.Value;
tasks.Add(FilterByYear(year, connectionString));
}
var results = await Task.WhenAll(tasks);
// Combine all results into a single set
var combinedResults = new List<MyEntity>();
foreach (var result in results)
{
combinedResults.AddRange(result);
}
// Display the results
DisplayResults(combinedResults);
Console.WriteLine(“end”);
}
static async Task<List<MyEntity>> FilterByYear(int year, string connectionString)
{
string query = “SELECT [Year], ID, Cost, Unit FROM [Values] WHERE [Year] = @year”;
List<MyEntity> results = new List<MyEntity>();
int maxRetries = 3; // Maximum number of retries
int delay = 1000; // Initial delay in milliseconds (1 second)
for (int retry = 0; retry < maxRetries; retry++)
{
try
{
using (SqlConnection connection = new SqlConnection(connectionString))
{
await connection.OpenAsync();
using (SqlCommand command = new SqlCommand(query, connection))
{
command.Parameters.AddWithValue(“@year”, year);
using (SqlDataReader reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
int readYear = (int)reader[“Year”];
int id = (int)reader[“ID”];
decimal cost = (decimal)reader[“Cost”];
int unit = (int)reader[“Unit”];
var entity = new MyEntity(readYear, id, cost, unit);
results.Add(entity);
}
}
}
}
break; // Break the loop on successful execution
}
catch (Exception ex)
{
if (retry == maxRetries – 1) break; // Rethrow the exception on the last retry
await Task.Delay(delay); // Wait before retrying
delay *= 2; // Double the delay for the next retry
}
}
return results;
}
static void DisplayResults(List<MyEntity> results)
{
Console.WriteLine(“Year | ID | Cost | Unit | TotalCost”);
Console.WriteLine(“———————————–“);
foreach (var entity in results)
{
Console.WriteLine($”{entity.Year} | {entity.ID} | {entity.Cost} | {entity.Unit} | {entity.TotalCost}”);
}
}
}
class MyEntity
{
public int Year { get; set; }
public int ID { get; set; }
public decimal Cost { get; set; }
public int Unit { get; set; }
public decimal TotalCost
{
get { return Cost * Unit; }
}
// Constructor for initializing properties
public MyEntity(int year, int id, decimal cost, int unit)
{
Year = year;
ID = id;
Cost = cost;
Unit = unit;
}
}
}
TSQL Scripts
CREATE TABLE [Values] (
[Year] INT,
[ID] INT IDENTITY(1,1) PRIMARY KEY,
[Cost] DECIMAL(10, 2),
[Unit] INT
);
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2021 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2022 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
Microsoft Tech Community – Latest Blogs –Read More
Lesson Learned #461:Effective Load Balancing in Azure SQL Database: A Practical Approach
In today’s data-driven landscape, we are presented with numerous alternatives like Elastic Queries, Data Sync, Geo-Replication, ReadScale, etc., for distributing data across multiple databases. However, in this approach, I’d like to explore a slightly different path: creating two separate databases containing data from the years 2021 and 2022, respectively, and querying them simultaneously to fetch results. This method introduces a unique perspective in data distribution — partitioning by database, which could potentially lead to more efficient resource utilization and enhanced performance for each database. While partitioning within a single database is a common practice, this idea ventures into partitioning across databases.
Background:
As data accumulates over time, the strain on a single database intensifies, often leading to slower query responses and potential bottlenecks. Load balancing, a critical concept in database management, offers a remedy by evenly distributing the data load across multiple servers or databases, thus enhancing performance and ensuring scalability.
Solution Overview:
Our approach entails a distributed database architecture where separate Azure SQL databases are designated for different years (e.g., 2021 and 2022). This setup not only simplifies data management but also strategically distributes the read load. The technology stack for this solution involves C#, Azure SQL Database, and the .NET framework.
Implementation:
Database Setup: We established two Azure SQL databases, each storing data for a specific year. This division allows for a focused and organized data structure.
C# Application Structure: The core of our application is the ClsLoadData class, which is responsible for connecting to and querying the databases. This class demonstrates effective organization and clarity in its purpose.
Connection String Mapping: A crucial aspect of our implementation is the mapping of different years to specific database connection strings within the C# application. This mapping ensures that queries are directed to the correct database.
Asynchronous Data Retrieval: We employed asynchronous programming in C#, using async and await, for efficient and non-blocking data retrieval. This approach is particularly beneficial in maintaining application responsiveness.
Retry Logic: To enhance robustness, we implemented a retry logic mechanism, which is vital in handling transient failures and ensuring reliable database connectivity.
Load Balancing in Action:
Parallel Execution: By querying both databases simultaneously, our application effectively distributes the read load. This parallel execution is key in maximizing performance and reducing the overall strain on each database.
Performance Benefits: The observed performance benefits were significant. We noted faster response times and a marked reduction in load on each individual database, confirming the efficacy of our load balancing strategy.
Lessons Learned:
Scalability: This approach scales seamlessly with additional databases and larger datasets. It proves that load balancing is not just a theoretical concept but a practical solution for growing data demands.
Maintainability: The ease of maintaining and updating separate databases was another critical takeaway. This architecture simplifies data management and enhances overall system maintainability.
Best Practices: Key best practices include thorough exception handling and secure management of connection strings. These practices are essential in safeguarding the application and ensuring its smooth operation.
Conclusion:
In summary, this implementation of load balancing using C# and Azure SQL Database not only addressed the challenge of managing large datasets but also offered insights into scalable, maintainable database architecture. The lessons learned and best practices identified here serve as valuable guides for similar scenarios.
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.Data.SqlClient;
using System.Threading.Tasks;
using System.Threading;
namespace DockerHealth
{
class ClsLoadData
{
public async Task Main()
{
// Define a dictionary mapping years to specific connection strings
var yearConnectionMappings = new Dictionary<int, string>
{
{ 2021, “Server=tcp:servername1.database.windows.net,1433; User Id=usrname;Password=Pwd1!;Initial Catalog=db1;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2021”},
{ 2022, “Server=tcp:servername2.database.windows.net,1433; User Id=usrname;Password=Pwd2!;Initial Catalog=db2;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;Pooling=true;Max Pool size=100;Min Pool Size=1;ConnectRetryCount=3;ConnectRetryInterval=10;Application Name = ConnTest 2022” }
};
var tasks = new List<Task<List<MyEntity>>>();
foreach (var mapping in yearConnectionMappings)
{
int year = mapping.Key;
string connectionString = mapping.Value;
tasks.Add(FilterByYear(year, connectionString));
}
var results = await Task.WhenAll(tasks);
// Combine all results into a single set
var combinedResults = new List<MyEntity>();
foreach (var result in results)
{
combinedResults.AddRange(result);
}
// Display the results
DisplayResults(combinedResults);
Console.WriteLine(“end”);
}
static async Task<List<MyEntity>> FilterByYear(int year, string connectionString)
{
string query = “SELECT [Year], ID, Cost, Unit FROM [Values] WHERE [Year] = @year”;
List<MyEntity> results = new List<MyEntity>();
int maxRetries = 3; // Maximum number of retries
int delay = 1000; // Initial delay in milliseconds (1 second)
for (int retry = 0; retry < maxRetries; retry++)
{
try
{
using (SqlConnection connection = new SqlConnection(connectionString))
{
await connection.OpenAsync();
using (SqlCommand command = new SqlCommand(query, connection))
{
command.Parameters.AddWithValue(“@year”, year);
using (SqlDataReader reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
int readYear = (int)reader[“Year”];
int id = (int)reader[“ID”];
decimal cost = (decimal)reader[“Cost”];
int unit = (int)reader[“Unit”];
var entity = new MyEntity(readYear, id, cost, unit);
results.Add(entity);
}
}
}
}
break; // Break the loop on successful execution
}
catch (Exception ex)
{
if (retry == maxRetries – 1) break; // Rethrow the exception on the last retry
await Task.Delay(delay); // Wait before retrying
delay *= 2; // Double the delay for the next retry
}
}
return results;
}
static void DisplayResults(List<MyEntity> results)
{
Console.WriteLine(“Year | ID | Cost | Unit | TotalCost”);
Console.WriteLine(“———————————–“);
foreach (var entity in results)
{
Console.WriteLine($”{entity.Year} | {entity.ID} | {entity.Cost} | {entity.Unit} | {entity.TotalCost}”);
}
}
}
class MyEntity
{
public int Year { get; set; }
public int ID { get; set; }
public decimal Cost { get; set; }
public int Unit { get; set; }
public decimal TotalCost
{
get { return Cost * Unit; }
}
// Constructor for initializing properties
public MyEntity(int year, int id, decimal cost, int unit)
{
Year = year;
ID = id;
Cost = cost;
Unit = unit;
}
}
}
TSQL Scripts
CREATE TABLE [Values] (
[Year] INT,
[ID] INT IDENTITY(1,1) PRIMARY KEY,
[Cost] DECIMAL(10, 2),
[Unit] INT
);
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2021 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
DECLARE @i INT = 0;
WHILE @i < 100
BEGIN
INSERT INTO [Values] ([Year], [Cost], [Unit])
VALUES (2022 + (@i % 2), CAST(RAND() * 100 AS DECIMAL(10, 2)), CAST(RAND() * 10 AS INT));
SET @i = @i + 1;
END;
Microsoft Tech Community – Latest Blogs –Read More

Partner Blog | Empowering innovation: Microsoft partners unite for transformative success
Our guest contributor for this blog is Regina Johnson, BPGI Global Strategy Director, with contributions from Raamel Mitchell, BPGI Global Director of Business Development.
Collaborative success in the Microsoft partner ecosystem
In a world where technology shapes our everyday lives, entrepreneurs in the Microsoft AI Cloud Partner Program exemplify innovation, leveraging Microsoft technology to deliver outstanding customer solutions and services through partnership. The Microsoft partner ecosystem is a testament to the transformative power of collaboration as a proven pathway to success. The FY23 Catalyst Accelerator is a prime example, with a cohort model developed with the Black Channel Partner Alliance (BCPA), the Microsoft Black Partner Growth Initiative (BPGI), and AppMeetup. This cohort brought together partners excelling in several industries and building on the Microsoft industry clouds. Their expertise in leveraging Microsoft technologies has led to advancements in their respective fields As they continue their journey, these partners are part of a larger global partner ecosystem, working alongside thousands of partners who are all pushing the boundaries of what’s possible in the tech world.
Continue reading here
Microsoft Tech Community – Latest Blogs –Read More

Azure Firewall’s Auto Learn SNAT Routes: A Guide to Dynamic Routing and SNAT Configuration
Introduction
Azure Firewall is a cloud-native network security service that protects your Azure virtual network resources. It is a fully stateful firewall as a service with built-in high availability and unrestricted cloud scalability. However, some Azure Firewall customers may face challenges when they need to configure non-RFC-1918 address spaces to not SNAT through the Azure Firewall. This can cause issues with routing, connectivity, and performance. To address this problem, Azure Firewall has introduced a new feature that allows customers to specify which address spaces should not be SNATed by the firewall. This feature can help customers reduce the overhead of managing custom routes and NAT rules and improve the efficiency and reliability of their network traffic. In this blog, we will explain how the feature works, what Azure Route Server is, and how to enable it. We will also provide a QuickStart guide and some examples to help you get started with this feature.
What is Azure Route Server?
The Azure Route Server (ARS) is a fully managed service that enables dynamic routing between your network virtual appliance (NVA) and your Azure virtual network, without requiring any manual configuration or intervention. The ARS is configured with high availability, meaning that it can automatically fail over to another instance in case of failure or disruption. The ARS uses the Border Gateway Protocol (BGP) routing protocol to exchange routing information directly with any NVA that supports BGP, such as firewalls, load balancers, or VPN gateways. This way, the ARS can learn the network address spaces that are advertised by the NVA and propagate them to the entire Azure virtual network. This eliminates the need for customers to manually configure route tables across all the subnets of an Azure virtual network, which can be tedious and error prone. Moreover, the ARS can dynamically update the route tables whenever a new address space is added or an old address space is removed by the NVA, ensuring that the routing is always consistent and up to date. The ARS simplifies the integration of NVAs with the Azure Software Defined Network (SDN), which provides a flexible and scalable network infrastructure for cloud applications. By using the ARS, customers can leverage the benefits of both NVAs and Azure SDN, such as security, performance, reliability, and cost-efficiency.
How does Auto-learn work?
Auto-learn SNAT routes is a public preview feature that can help reduce time and complexity spent manually defining SNAT private ranges. The Azure Firewall will pull an updated list of learned address ranges from the Azure Route Server every 30 minutes. These learned address ranges are considered to be internal to the network, so traffic to destinations in the learned ranges aren’t SNATed. This is especially useful when enterprises must use non-RFC-1918 address spaces in their environments.
Auto-learn SNAT routes is simple to configure either through the Azure Portal or using a variety of Infrastructure as Code (IaC) flavors.
To enable the feature, you’ll first have to create an Azure Route Server and BGP peer it to your network virtual appliance. The Azure Route Server must be in the same virtual network as the Azure Firewall. Use this QuickStart guide to learn how to deploy the ARS and configure it to peer with your appliance. Once the ARS has been successfully peered with the appliance, we can start associating the Azure Firewall with the Azure Route Server to auto-learn out of network address spaces. To enable the feature in the Azure Portal, follow the steps below:
1. Navigate to the Azure Firewall’s Overview blade and select Learned SNAT IP Prefixes. From this view, select Add to choose which Azure Route Server will teach this particular firewall its learned routes. Remember that the Azure Firewall and the ARS must be in the same Azure virtual network.
2. Once an ARS has been selected, the feature needs to be enabled on the associated Azure Firewall Policy. From the previous screenshot, simply select Disabled on Firewall policy to be redirected to the Private IP ranges (SNAT) blade in the associated Azure Firewall Policy. On this blade, select Auto-learn IP prefixes under Exceptions to finish configuring the Auto-learn SNAT feature.
3. After you finish the steps on the Azure Firewall, and after the ARS and the NVA can talk to each other using BGP, you can see the new routes that the ARS told the Azure Firewall on the Learned SNAT IP Prefixes blade. In the picture below, you can see that we learned one private address range and one public address range, 20.32.0.0/24. The Azure Firewall will now know that 20.32.0.0/24 is not for public internet but for local networks in Azure and other remote networks. This prevents the Azure Firewall from changing the source IP of the public address range when it checks the traffic. But any traffic that goes through Application Rules on the Azure Firewall will still have its source IP changed to either the private IP or the public IP of the Azure Firewall, depending on where it goes next.
Conclusion
Azure Firewall’s Auto-learn SNAT routes feature can help you simplify and optimize your network configuration in Azure. This feature allows the Azure Firewall to automatically learn the out-of-network address spaces from the Azure Route Server and avoid SNATing the traffic to those destinations. This can save you time and effort in manually defining the SNAT private ranges, and also improve the performance and security of your network traffic. Auto-learn SNAT routes is easy to enable either through the Azure Portal or using your preferred IaC tool. You just need to create an Azure Route Server, peer it with your network virtual appliance, and associate it with your Azure Firewall policy. If you want to try this feature, you can follow the QuickStart guide and the steps we have provided in this blog. Auto-learn SNAT routes is a public preview feature that can enhance your network experience in Azure, so don’t miss this opportunity and give it a try today!
Resources
What is Azure Firewall? | Microsoft Learn
Azure Firewall FAQ | Microsoft Learn
Azure Firewall preview features | Microsoft Learn
Azure Firewall SNAT private IP address ranges | Microsoft Learn
What is Azure Route Server? | Microsoft Learn
Azure Route Server frequently asked questions (FAQ) | Microsoft Learn
Lab/RS-AA-OPNsense-ForceTunnel-ER at master · dmauser/Lab (github.com)
Microsoft Tech Community – Latest Blogs –Read More
Free SQL Managed Instance
Introducing Free Azure SQL Managed Instance
We’re thrilled to announce the Free SQL Managed Instance, allowing you to experience the full capabilities of managed SQL Server in the cloud at absolutely no cost for the first 12 months!
What You Get:
General Purpose instance with up to 100 databases
720 vCore hours of compute every month (do not accumulate)
64 GB of storage
One instance per Azure subscription
The instance is automatically stopped when you reach the monthly vCore limit; managed instance starts automatically when credits are available again, or you can manually stop it to preserve free monthly vCore hours
How to Get Started:
Getting started with Azure SQL Managed Instance Free Trial is a breeze. Follow these simple steps:
Visit the Azure portal: Head to the provisioning page for Azure SQL Managed Instance.
Apply Free Offer: Look for the “Want to try Azure SQL Managed Instance for free?” banner and click on the “Apply offer” button.
Resource Group: Choose an existing resource group or create a new one.
Configure Instance: Set up your instance details, including region, authentication method, networking, security, and additional settings.
Review and Create: Review your settings, then click “Create” to set up your free instance.
And just like that, you’re ready to explore the capabilities of Azure SQL Managed Instance!
Connect Seamlessly to Your Instance
Connecting to your instance is a breeze, whether you have a public endpoint enabled or disabled:
Public Endpoint Enabled: Copy the Host value from the Azure portal, paste it into your preferred data tool, and connect.
Public Endpoint Disabled: Choose to create an Azure VM within the same virtual network or configure point-to-site for connection.
Instance Schedule Tailored to Your Needs
To conserve credits, your free instance is scheduled to be on from 9 am to 5 pm Monday through Friday in your configured time zone. Modify the schedule to suit your business requirements.
Offer Details – Know Before You Go
While our Azure SQL Managed Instance Free Trial is packed with features, there are some limitations to keep in mind:
vCore hours: 720
Storage: Up to 64 GB (system files may use up to 32 GB)
Instances per subscription: 1
Compute: 4 and 8 vCore instances only
Service tier: General purpose only
Hardware: Standard only
Zone redundancy: Not available
Failover groups: Not available
Scaling: Scale up or down within the compute limits
Backups: 0-7 days for short-term retention, long-term retention (LTR) is unavailable
Charge for SQL Server license: None
Availability and Support
The free offer is currently available in select regions, including Australia East, East US, East US 2, North Europe, Sweden Central, Southeast Asia, South Central US, UK South, West Europe, West US 2, and West US 3 (subject to change).
Please note:
No guaranteed SLA
Currently, upgrading your free instance to the paid version isn’t possible. Create a new instance and restore your database to continue without limitations.
Microsoft Tech Community – Latest Blogs –Read More
Wired for Hybrid – What’s New in Azure Networking December 2023 edition
Hello Folks,
Azure Networking is the foundation of your infrastructure in Azure. Each month we bring you an update on What’s new in Azure Networking.
In this blog post, we’ll cover what’s new with Azure Networking in December 2023. In this blog post, we will cover the following announcements and how they can help you.
Enjoy!
Integration of Azure Monitor Agent support with Connection Monitor
Connection Monitor, a multi-agent monitoring solution, detects network connectivity and performance errors real time with aggregated packet loss and latency, localizes the problematic network component with end-to-end path visibility in unified topology and provides actionable insights to diagnose and troubleshoot the issues, thus reducing the overall Mean Time to Resolve network connectivity issues.
With Azure Monitor Agent, we aim to consolidate multi-monitoring agents into a single agent. This capability addresses connectivity monitoring logs and metrics data collection needs across Azure and ARC enabled on-premises machines, thus eliminating the overhead of management and enablement of multiple monitoring agents. Additionally, Azure Monitor Agent provides enhanced security and performance capabilities, effective cost savings & ease of troubleshooting with simpler management of data collection. With this support, the dependency on soon to be deprecated Log Analytics agent is eliminated, while increasing the coverage for on-premises machines with support for ARC enable endpoints.
The highlighted features of this new update are:
Connectivity monitoring support for ARC enabled on-premises endpoints as source as well as destination.
Simpler management of network monitoring extensions
One agent for monitoring Azure and non-Azure Arc endpoints
Enhanced security through Managed Identity and Azure Active Directory (Azure AD) tokens
The roadmap for the feature includes:
Portal support for auto-enablement of Azure Monitor Agent extension
Integrated support for enablement of Network Watcher extension with Azure Monitor Agent
Extended support across Azure resources beyond VM and VM scale set
Enhanced performance metrics with Throughput and Jitter UI support
Using a common port for public and private listeners
The support for configuring the same port number for public and private listeners on your Application Gateway is now generally available.
The provision enables you to easily use a single Application Gateway deployment to serve both internet-facing and internal clients. With this, you don’t need to use non-standard ports on listeners or customize the backend application. This feature is now generally available in all public regions, Azure China cloud regions, and Azure Government cloud regions.
An additional configuration may be needed for Inbound rules if you use Network Security Groups with your application gateway.
Rate-limit rules for Application Gateway Web Application Firewall
Rate-limit custom rules on Azure’s regional Web Application Firewall (WAF) running on Application Gateway are now available. Rate-limiting enables you to detect and block abnormally high levels of traffic destined for your application. By using rate limiting, you can mitigate many types of denial-of-service attacks, protect against clients that have accidentally been misconfigured to send large volumes of requests in a short time period, or control traffic rates to your site from specific geographies.
ExpressRoute Direct and Circuit in different subscriptions
ExpressRoute Direct customers will be able to manage network costs, connect ExpressRoute circuits from multiple subscriptions with one ExpressRoute direct Port resource, and isolate management of ExpressRoute Direct resource from your ExpressRoute circuits.
ExpressRoute Direct gives you the ability to connect directly into the Microsoft global network at peering locations strategically distributed around the world. ExpressRoute Direct provides dual 100-Gbps or 10-Gbps connectivity, that supports Active/Active connectivity at scale.
This requires an ExpressRoute Direct port and an ExpressRoute Circuit. Previously, ExpressRoute circuits and ExpressRoute Direct resources were created in one subscription, you then could connect their circuit to a Virtual Network resource that is located in a different subscription using an authorization.
With this feature today, you can create the Port and ExpressRoute circuit in different subscriptions redeeming the authorizations to create a circuit.
Resources
Azure ExpressRoute Overview: Connect over a private connection
Azure ExpressRoute: Configure ExpressRoute Direct using the Azure portal
Connect your on-premises network to the Microsoft global network by using ExpressRoute – Training
General availability: ExpressRoute as a Trusted Service
Express Route is now a Trusted Service in Azure. This means you can store your Media Access Control, or MACsec, secrets (Connectivity Association Key and Connectivity Association Key Name) in an Azure Key Vault with Firewall policies enabled. That way you can restrict public access to Keyvault yet allow Trusted services like ExpressRoute to access secrets, passwords, or keys stored in the Keyvault.
This continues with our push to make it easier for you to securely connect to Azure from your on-premises environment.
Resources
Trusted Services: Configure Azure Storage firewalls and virtual networks
Azure Virtual Network Manager Security Admin Rule generally available in select regions
With security admin rules & virtual network manager, you can centrally manage and apply security policies across your organization. Security admin rules applied through security configuration. This config can be applied to network groups containing any set of virtual networks in your organization.
Brings greater ability to manage org wide your security posture. Unlike NSGs, sec admin rules will be applied to any virtual network added to a network group w/ a sec configuration applied.
Resources
Security admin rules in Azure Virtual Network Manager
How to block network traffic with Azure Virtual Network Manager – Azure portal
Wired for Hybrid – Deep Dive 3 – Azure Virtual Network Manager
That’s it for this month. Happy Holidays!
Cheers
Pierre
Microsoft Tech Community – Latest Blogs –Read More

Microsoft Ignite 2023 with MVP Communities
This year’s conference Microsoft Ignite, which was themed around “Experience AI transformation in action, online from anywhere”, was held in Seattle from November 14 to 17. As the CEO Satya Nadella mentioned at the beginning of the opening keynote speech, ‘We are introducing 100 new updates,’ it became an event that delivered the latest technology information, including cutting-edge Microsoft AI and Microsoft Copilot, to users around the world who participated in-person and those who watched the Ignite livestream.
At this conference, over 100 Microsoft MVPs and Regional Directors (RDs) from around the world joined the Microsoft Ignite in Seattle to explore the latest technologies that are pioneering the newly arrived AI era, and to develop new solutions and explore their applications in various businesses. For MVPs and RDs, not only was learning a purpose, but they also took part in numerous initiatives to deliver unique information as community leaders, including being session speakers, organizing demo sessions, supporting Expert Meetups and Learn Labs. Their involvement in sharing their knowledge and experience enhanced the technological understanding of other participants.
Jorge Maia, an IoT MVP in Brazil, participated in this Microsoft Ignite as a Proctor for Lab session LAB742: Configure secure access to your workloads using Azure networking, assisting participants, and at the Microsoft Learning Booth, he introduced the Microsoft Learn community and Microsoft Applied Skills, a new system for proving skills that was launched in October 2023.
“I now understand the potential of the Copilot ecosystem, which can empower companies and users. During my experience, I saw the generative AI for coding and low code in action, learned about various AI use cases, and gained great ideas to use for my own company’s clients. On the infrastructure side, I learned about Arc and other essential resources for managing, securing, and observing the infrastructure,” Jorge shares what he learned at this Microsoft Ignite.
He also mentions that interactions with participants provided insights into his future community activities related to AI and related technologies. “AI has become a new buzzword and a challenge for everyone. Everybody was looking for ways to integrate it into their daily tasks. I have realized there is a real need for AI and, but there are too many misunderstandings. I have gotten several ideas to create new content for the community about this topic, integrating with infrastructure, IoT, and everyday activities, along with key points to increase our productivity.”
Jorge tells us what new technology topics at the conference he is particularly paying attention to. “I have focused on Azure IoT Operations, Azure AI Studio, and the Copilot ecosystem as my work involves IoT and digital transformation. With IoT Operations, we can now provide better solutions for complex-edged environments. Azure AI Studio provides a complete solution development environment for creating, experimenting, and developing new intelligent solutions. The Copilot ecosystem takes everyday tasks to another level. We can even create our own Copilot solution, which is great!”
With many exciting activities taking place during Ignite, Jorge had difficulty finding time to participate in sessions himself. He says, “I did some labs on the website and attended a few sessions; as I didn’t have much time on the site, I saved some sessions on my Backpack; this was an excellent benefit for attendees.”
In addition to the main conference, our program hosted an exclusive event, MVP Connect, offering private networking opportunities for MVPs and RDs who usually work around the world and came to Seattle specifically for Microsoft Ignite. The leaders welcomed everyone, expressed gratitude for their community activities, and Product Group members also joined to provide information directly and receive feedback, offering a unique program experience
Tetsuya Odashima, an Azure MVP from Japan, was one of the MVPs who visited Seattle to join Microsoft Ignite. He had previously participated in conferences like Microsoft Ignite and Microsoft Build online, but this was his first visit to Seattle to experience a conference in person. “I have been satisfied with gathering information through online participation. However, attending the conference in-person made me realize that information is conveyed more accurately, and I could fully feel the passion from the speakers and fellow engineers around me. The world is indeed vast! It has motivated me to keep striving and doing my best. If I have the opportunity to attend such global events in the future, I would like to participate, and I highly recommend others to join the conference in person.”
At Microsoft Ignite, Tetsuya was particularly interested in the new technology information about Copilot services. “With the advent of Copilot, I believe the way we work will change dramatically as the use of Copilot gradually increases. I also strongly feel that we need new skills to get along well with Copilot.”
He also participated in the side event MVP Connect and expressed his enthusiasm for future growth based on this experience. “It was very impressive to see MVPs and RDs from other countries actively providing feedback for further improvements in discussion with Microsoft employees. It’s regrettable that I couldn’t converse well when approached by another MVP. I want to improve my English conversation skills…”
To learn more about Microsoft Ignite, please visit the following websites.
Microsoft Ignite (Official website)
Microsoft Ignite 2023 Book of News (Stories)
Microsoft Learn for Ignite (Microsoft Learn)
Microsoft Ignite | Cloud Skills Challenge (Microsoft Learn)
The challenges end on January 15, 2024, at 4:00 PM UTC
Microsoft Ignite (YouTube)
Microsoft Tech Community – Latest Blogs –Read More

Securing DevOps with Microsoft’s CNAPP: Defender for Cloud
As the landscape of DevOps continues to expand and confront increasingly sophisticated security threats, the need for proactive attack surface reduction measures has never been more critical. To enhance DevOps security and prevent attacks, Defender for Cloud, a Cloud Native Application Protection Platform (CNAPP), is enabling customers with new capabilities: DevOps Environment Posture Management, Code to Cloud Mapping for Service Principals, and new DevOps Attack Paths. These features represent a strategic shift towards a more integrated and holistic approach to cloud native application security throughout the entire development lifecycle.
DevOps Environment Posture Management
DevOps Environment Posture Management offers a deep dive into the security health of the cloud-native application lifecycle. Through deep scanning of source code management systems, Defender for Cloud identifies weaknesses in resources such as pipelines, repositories, and service connections, identifying potential vulnerabilities in platform configurations.
DevOps Environment Posture Management recommendations are critical for starting secure at the source and enhancing the overall security posture of cloud native applications end-to-end. They address key vulnerabilities and potential attack vectors in Azure DevOps and GitHub environments, including:
Azure DevOps Pipelines: Ensure that secrets are not accessible in builds of forks to prevent external entities from accessing internal build pipeline secrets.
GitHub Repositories and Organizations: Implement protection policies for default branches to safeguard against unauthorized or malicious changes.
Azure DevOps Service Connections, Variable Groups, and Secure Files: Recommendations to limit the access of the secure CI/CD resources to only pipelines that need access to reinforce least privilege access and prevent against privilege escalation threats.
Imagine a scenario where a developer inadvertently allows Azure DevOps pipelines to expose secrets in forked builds. This could potentially allow external threat actors to access sensitive internal data. By implementing recommendations from the DevOps Environment Posture Management, such as ensuring secrets are not accessible in builds of forks, organizations can prevent these kinds of security breaches.
An example of the recommendation for “Azure DevOps pipelines should not have secrets available to builds of forks” is in Figure 1 below. This recommendation provides a clear description of the issue, detailed remediation steps, and a list of all the unhealthy and healthy Azure DevOps pipelines. Additionally, the recommendation also contains a severity level and mapping to the DevOps Threat Matrix tactics.
Figure 1. DevOps Environment Posture Management recommendation
By clicking on the unhealthy resource, customers can gain more information on the Resource health blade, including the Azure DevOps Organization and Project and a direct link to the affected component.
Figure 2. DevOps resource details
This information can also be found in the DevOps Security workbook in the Posture Management tab.
Figure 3. DevOps Posture Management tab in the DevOps Security workbook
When implemented, these recommendations significantly strengthen the security posture of the source code environments used to develop cloud applications.
Service Principal Mapping
Enhancing the capabilities of posture management recommendations, Service Principal Mapping in Defender for Cloud connects CI/CD pipelines directly to cloud environments. This connection is crucial for providing visibility and control from code development all the way to cloud deployment.
CI/CD pipelines typically interact with cloud resources using a Service Principal (SPN) as their identity. However, this can create security risks, especially when SPNs are over-privileged or when pipelines, such as those in public Azure DevOps repositories, lack sufficient security controls. Such weaknesses can turn these pipelines into targets for malicious actors, who may exploit these weaknesses to gain unauthorized access to cloud resources. The consequences of these breaches can range from data leaks to unauthorized alterations of critical infrastructure, posing significant threats to organizational security.
Service Principal Mapping addresses this risk by offering visibility into the specific Azure resources accessible by each SPN. This creates a clear and comprehensive map of access points within the cloud environment, which is vital for organizations to accurately assess and manage the extent of cloud access privileges granted to their DevOps platforms. By exposing these access relationships and evaluating the risks associated with them, Defender for Cloud reduces the attack surface and enhances the security posture of applications from code to cloud.
To test this in your environment, first ensure you have a connector to Azure DevOps and/or GitHub in Defender for Cloud with Defender CSPM enabled, and then run the following queries:
Azure DevOps Service Principal Mapping.
GitHub Service Principal Mapping
Figure 4: Service Principal Mapping Query in Cloud Security Explorer
DevOps Attack Paths
By leveraging insights from the new recommendations and mapping capabilities, our Microsoft Security research team has released new attack path, highlighting the most critical risks within a customer’s environment.
As an example, we now have an attack path for a GitHub repository without branch protection rules that has permissions to connect to Azure resources. This means that if the repository were to be compromised, then an adversary would be able to modify and execute the GitHub workflow to compromise your Azure environment.
Figure 5. New DevOps Attack Path
Conclusion
DevOps security in Defender for Cloud offers a comprehensive approach to securing the cloud-native application development lifecycle. This approach extends beyond just protecting individual DevOps components to secure the entire software development process, from the initial coding phase to the final deployment in the cloud. As technology evolves and new cybersecurity threats emerge, these capabilities assist in proactively strengthening the posture of applications, ensuring that organizations can safely navigate the complexities of cloud-native development.
Microsoft Tech Community – Latest Blogs –Read More

Top Takeaways from Unlocking the Channel Opportunity: Strategies for Marketplace Success
If you missed the recent webinar on unlocking the channel opportunity strategies for marketplace success, don’t worry, we’ve got you covered! This session covered how to activate the Microsoft commercial marketplace for your go-to-market strategy and explored best practices for maximizing the marketplace opportunity, with an emphasis on collaborative selling with other partners. Here are some of the top takeaways from the presentation by Kristen Maddox and Jason Rook, from Microsoft’s marketplace team.
The cloud marketplace is a huge and growing opportunity for ISVs and partners, with an estimated value of $50 billion by 2025. Some of the drivers of this growth include the shift to modern procurement, the cost and efficiency benefits for ISVs and customers, and the ecosystem and co-selling advantages.
The marketplace helps ISVs reach every Microsoft customer, simplify sales by handling global commerce, and unlock growth by accessing the Microsoft partner and field ecosystem.
By publishing your app on the marketplace, you can expose it to millions of Microsoft customers who are looking for cloud solutions that work with Microsoft products and services.
By selling your app through the marketplace, you can leverage Microsoft’s billing and payment infrastructure, which supports over 140 markets and 17 currencies, and reduces your operational overhead and complexity.
By partnering with Microsoft, you can access the Microsoft partner ecosystem, which consists of over 400,000 partners who can resell, co-sell, or integrate your app with their solutions. You can also access the Microsoft field sellers, who are incentivized to co-sell your app with Microsoft products and services, and who can help you reach enterprise customers and close larger deals.
The marketplace also helps customers increase efficiency, buy confidently, and spend smarter by using their cloud commitments to purchase third-party solutions. Through marketplace, customers can:
Find and buy solutions that are compatible with their Microsoft cloud products and services, such as Azure, M365, or Teams, and that meet their business needs and industry standards.
Reduce the vendor onboarding and procurement processes by buying from Microsoft as a trusted provider and using their existing contracts and billing methods.
Leverage their Azure consumption commitments, which are pre-paid cloud spend that they agree to with Microsoft, to buy third-party solutions from the marketplace and get discounts or incentives.
Optimize their cloud spend by having better visibility and control over their usage and costs, and by choosing the best pricing and licensing options for their solutions.
There are three paths for ISVs to get their solutions to customers through the marketplace:
Direct is when the ISV publishes their solution and the customer buys it from the marketplace, either at list price or with a private offer.
Through CSP is when the ISV works with a cloud solution provider partner who sells their solution to SMB customers on a CSP contract, either at list price or with a private offer.
Through selling partner is when the ISV works with a partner who sells their solution to enterprise customers on an enterprise contract, with a multi-party private offer.
ISVs should leverage Marketplace Rewards, a free program that Microsoft offers to ISVs who publish their solutions on the marketplace. Key benefits include:
GTM support: This includes optimizing your product display page, getting featured on Microsoft marketing channels, and accessing best practices and guidance for marketplace success.
Azure sponsorship: This is a way to get Azure credits that you can use for your own development, testing, or demo purposes, or to offer to your customers as an incentive to close deals. You can unlock up to 100K in Azure sponsorship based on your marketplace sales.
Field webinars: This is an opportunity to present your solution to Microsoft field sellers who can help you co-sell and reach more customers. You can unlock a field webinar when you reach a certain level of marketplace sales and co-sell status.
Register to watch the recording! For more takeaways and more detailed info on those takeaways listed above, register to watch the recording.
Have follow up questions about this presentation’s content? Comment below to continue the conversation with our presenters, @KMCloudgirl and @jasonrook!
__________________________________________________________________________________________________________________________________________
Stay updated on upcoming marketplace community events: fill out this form. and we will email you with updates on new community events where you can participate in live Q&A with Microsoft!
Microsoft Tech Community – Latest Blogs –Read More

* DMC On Demand Tool * New Microsoft 365 Campaigns
Digital Marketing Content (DMC) OnDemand works as a personal digital marketing assistant and delivers fresh, relevant and customized content and share on social, email, website, or blog. It runs 3-to-12-week digital campaigns that include to-customer content and to-partner resources. This includes an interactive dashboard that will allow partners to track both campaign performance and leads generated in real time and to schedule campaigns in advance
NEW CAMPAIGNS
NOTE: To access localised versions, click the product area link, then select the language from the drop-down menu.
Product Area: Microsoft 365
Cloud Endpoints
Secure Productivity for Retail
Secure Productivity for Healthcare
MICROSOFT AI CLOUD PARTNER PROGRAM
The world and how we work are rapidly changing. The opportunities for Microsoft partners—whether you build and sell services, software solutions, or devices—are significant. The capabilities that are required by our customers are evolving, and our partner programs are changing to meet that demand.
The Microsoft AI Cloud Partner Program is focused on simplifying our programs, delivering greater customer value, investing in your growth in new ways, and recognizing how you deliver customer value. Check out links below to learn more:
Admins can sign-in to Partner Center to see how your organisation is progressing towards a Solutions Partner designation and see the associated benefits.
Go to Training Gallery & Microsoft docs to learn about the requirements needed to attain a Solutions Partner designation.
For more information visit the Microsoft partner website and Microsoft partner blog.
Create a logo using Logo Builder
PROGRAM & GETTING STARTED RESOURCES
If you’re still new to DMC, you can find program decks with links to recorded demos here. This collection of resources expands all of our digital services.
FEATURES & FUNCTIONALITY
If you’re just returning to DMC or just want a quick recap of the updates we’ve made, you can find them under ”Program Updates” of the Resources section in DMC, which can also be found by clicking the help icon on the top right.
In addition to English, the DMC user interface now supports additional languages. To update, go to your profile, click the edit button on the top right, and then select your preferred language from the drop down menu in the “your information” section.
CONNECT WITH US
If you’d like to speak with someone directly, please join our monthly office hours on January 4, 2024 (occurs the first Thursday of each month.) We offer morning and evening (PST) sessions to accommodate different time zones.
FEEDBACK AND SUPPORT
We’re always working on making DMC a better experience for you. If you have 5 minutes to review your current experience with DMC, we’d love to hear your thoughts. NOTE: All submissions are anonymous, so please reach out to us if you need support, or join our office hours the first Thursday of each month.
Microsoft Tech Community – Latest Blogs –Read More
Wired for Hybrid – What’s New in Azure Networking December 2023 edition
Hello Folks,
Azure Networking is the foundation of your infrastructure in Azure. Each month we bring you an update on What’s new in Azure Networking.
In this blog post, we’ll cover what’s new with Azure Networking in December 2023. In this blog post, we will cover the following announcements and how they can help you.
Enjoy!
Integration of Azure Monitor Agent support with Connection Monitor
Connection Monitor, a multi-agent monitoring solution, detects network connectivity and performance errors real time with aggregated packet loss and latency, localizes the problematic network component with end-to-end path visibility in unified topology and provides actionable insights to diagnose and troubleshoot the issues, thus reducing the overall Mean Time to Resolve network connectivity issues.
With Azure Monitor Agent, we aim to consolidate multi-monitoring agents into a single agent. This capability addresses connectivity monitoring logs and metrics data collection needs across Azure and ARC enabled on-premises machines, thus eliminating the overhead of management and enablement of multiple monitoring agents. Additionally, Azure Monitor Agent provides enhanced security and performance capabilities, effective cost savings & ease of troubleshooting with simpler management of data collection. With this support, the dependency on soon to be deprecated Log Analytics agent is eliminated, while increasing the coverage for on-premises machines with support for ARC enable endpoints.
The highlighted features of this new update are:
Connectivity monitoring support for ARC enabled on-premises endpoints as source as well as destination.
Simpler management of network monitoring extensions
One agent for monitoring Azure and non-Azure Arc endpoints
Enhanced security through Managed Identity and Azure Active Directory (Azure AD) tokens
The roadmap for the feature includes:
Portal support for auto-enablement of Azure Monitor Agent extension
Integrated support for enablement of Network Watcher extension with Azure Monitor Agent
Extended support across Azure resources beyond VM and VM scale set
Enhanced performance metrics with Throughput and Jitter UI support
Using a common port for public and private listeners
The support for configuring the same port number for public and private listeners on your Application Gateway is now generally available.
The provision enables you to easily use a single Application Gateway deployment to serve both internet-facing and internal clients. With this, you don’t need to use non-standard ports on listeners or customize the backend application. This feature is now generally available in all public regions, Azure China cloud regions, and Azure Government cloud regions.
An additional configuration may be needed for Inbound rules if you use Network Security Groups with your application gateway.
Rate-limit rules for Application Gateway Web Application Firewall
Rate-limit custom rules on Azure’s regional Web Application Firewall (WAF) running on Application Gateway are now available. Rate-limiting enables you to detect and block abnormally high levels of traffic destined for your application. By using rate limiting, you can mitigate many types of denial-of-service attacks, protect against clients that have accidentally been misconfigured to send large volumes of requests in a short time period, or control traffic rates to your site from specific geographies.
ExpressRoute Direct and Circuit in different subscriptions
ExpressRoute Direct customers will be able to manage network costs, connect ExpressRoute circuits from multiple subscriptions with one ExpressRoute direct Port resource, and isolate management of ExpressRoute Direct resource from your ExpressRoute circuits.
ExpressRoute Direct gives you the ability to connect directly into the Microsoft global network at peering locations strategically distributed around the world. ExpressRoute Direct provides dual 100-Gbps or 10-Gbps connectivity, that supports Active/Active connectivity at scale.
This requires an ExpressRoute Direct port and an ExpressRoute Circuit. Previously, ExpressRoute circuits and ExpressRoute Direct resources were created in one subscription, you then could connect their circuit to a Virtual Network resource that is located in a different subscription using an authorization.
With this feature today, you can create the Port and ExpressRoute circuit in different subscriptions redeeming the authorizations to create a circuit.
Resources
Azure ExpressRoute Overview: Connect over a private connection
Azure ExpressRoute: Configure ExpressRoute Direct using the Azure portal
Connect your on-premises network to the Microsoft global network by using ExpressRoute – Training
General availability: ExpressRoute as a Trusted Service
Express Route is now a Trusted Service in Azure. This means you can store your Media Access Control, or MACsec, secrets (Connectivity Association Key and Connectivity Association Key Name) in an Azure Key Vault with Firewall policies enabled. That way you can restrict public access to Keyvault yet allow Trusted services like ExpressRoute to access secrets, passwords, or keys stored in the Keyvault.
This continues with our push to make it easier for you to securely connect to Azure from your on-premises environment.
Resources
Trusted Services: Configure Azure Storage firewalls and virtual networks
Azure Virtual Network Manager Security Admin Rule generally available in select regions
With security admin rules & virtual network manager, you can centrally manage and apply security policies across your organization. Security admin rules applied through security configuration. This config can be applied to network groups containing any set of virtual networks in your organization.
Brings greater ability to manage org wide your security posture. Unlike NSGs, sec admin rules will be applied to any virtual network added to a network group w/ a sec configuration applied.
Resources
Security admin rules in Azure Virtual Network Manager
How to block network traffic with Azure Virtual Network Manager – Azure portal
Wired for Hybrid – Deep Dive 3 – Azure Virtual Network Manager
That’s it for this month. Happy Holidays!
Cheers
Pierre
Microsoft Tech Community – Latest Blogs –Read More







