

Category: Microsoft
Category Archives: Microsoft
Report Delegated Permission Assignments for Users and Apps
This article describes how to use the Microsoft Graph PowerShell SDK to report delegated permission assignments to user accounts and apps. Like in other parts of Microsoft 365, the tendency exists to accrue delegated permissions for both user accounts and apps over time. There’s nothing wrong with having delegated permissions in place, if they are appropriate and needed – and that’s why we report their existence.
https://office365itpros.com/2024/06/06/delegated-permissions-report/
This article describes how to use the Microsoft Graph PowerShell SDK to report delegated permission assignments to user accounts and apps. Like in other parts of Microsoft 365, the tendency exists to accrue delegated permissions for both user accounts and apps over time. There’s nothing wrong with having delegated permissions in place, if they are appropriate and needed – and that’s why we report their existence.
https://office365itpros.com/2024/06/06/delegated-permissions-report/ Read More
Exceptions for Security recommendations – CVE Weakness
Hi All,
We have a critical CVE (Defender Portal) on a system that is no longer in operation. Now I want the CVE to no longer appear in the dashboard under “Weaknesses”.
So I have manually tagged the system as “Decommissioned” and built a device group “Decommissioned” based on the tag.
As far as I know, you can only set the “Exceptions” to “Security Recommendations” globally or on Device Groups.
So I set an exception on the “Recommendation” related to the device group.
However, the vulnerability is still displayed under “Weaknesses”.
My hope was that the vulnerability would be removed from the overview so that I would see fewer false positives.
My guess is that since the Security Recommendations contain a total of 55 CVEs, the process is not working as expected.
How do you handle Exceptions in the Dashboard/Overview?
Thanks for the help.
Hi All, We have a critical CVE (Defender Portal) on a system that is no longer in operation. Now I want the CVE to no longer appear in the dashboard under “Weaknesses”.So I have manually tagged the system as “Decommissioned” and built a device group “Decommissioned” based on the tag.As far as I know, you can only set the “Exceptions” to “Security Recommendations” globally or on Device Groups.So I set an exception on the “Recommendation” related to the device group.However, the vulnerability is still displayed under “Weaknesses”. My hope was that the vulnerability would be removed from the overview so that I would see fewer false positives.My guess is that since the Security Recommendations contain a total of 55 CVEs, the process is not working as expected.How do you handle Exceptions in the Dashboard/Overview? Thanks for the help. Read More
Lists – affected item – custom permissions
Hello,
If the tasks in the “planner” could be much more customizable, I’d use “planner”, however, the tasks are too rigid, not customizable enough, so I’m forced to use lists.
But how can I reproduce the native behavior of “planner”: have a global list, with members only see the tasks to which they are assigned?
I see two approaches.
1) Define a master list containing a “team” column, define a list in each team, then synchronize the items in each list, update them when modified, etc. with PowerAutomate.
Or :
2) Define lists in each team and build a global list from all items in each list.
Which is the better option? Is there another way of doing this?
Hello, If the tasks in the “planner” could be much more customizable, I’d use “planner”, however, the tasks are too rigid, not customizable enough, so I’m forced to use lists. But how can I reproduce the native behavior of “planner”: have a global list, with members only see the tasks to which they are assigned? I see two approaches. 1) Define a master list containing a “team” column, define a list in each team, then synchronize the items in each list, update them when modified, etc. with PowerAutomate. Or : 2) Define lists in each team and build a global list from all items in each list.Which is the better option? Is there another way of doing this? Read More
how to remove unwished ranges or how to shrink the displayed part of a Graph/Chart
Dear all
I have a defined Chart and I would ‘restrict’ the area of the x-axis that is shown w/o creating a
different chart.
I know how to restrict the values on the y-axis.
Is there a similar way to zoom-in the X-axis (or indeed to zoom out as there could be the wish to) w/o
creating a different chart?
BTW the question is also valid if the x-axis does not have numerical values
Thank you and regards
Dear allI have a defined Chart and I would ‘restrict’ the area of the x-axis that is shown w/o creating adifferent chart.I know how to restrict the values on the y-axis. Is there a similar way to zoom-in the X-axis (or indeed to zoom out as there could be the wish to) w/ocreating a different chart? BTW the question is also valid if the x-axis does not have numerical values Thank you and regards Read More
Adaptive Scope – Just Active Mailboxes
Hi,
Can I create an adaptive scope that just included all active mailboxes? E.g. if the query was just “isInactiveMailbox -eq “False”
Would that work by itself?
Hi, Can I create an adaptive scope that just included all active mailboxes? E.g. if the query was just “isInactiveMailbox -eq “False” Would that work by itself? Read More
Is there a simplified way to submit CPoR claim?
I have joined an organisation as Head of Digital Transformation and Consultancy Services. As part of the role, I am responsible for the relationship with Microsoft and the Partner Centre. I am working to ensure we have now registered CPoR against our clients (and there are a lot) as it had not previously been done.
It has been some time since I actually ran through the process and I have been alarmed how “manual” it is and how time consuming. The need to physically print off, manually complete the PoE form, scan, send to the client, client print, client sign, client scan, client send back is very 2003 and very time consuming.
Also finding that different members of the review team want to see different things and so the process is turning into a difficult task when it doesn’t need to be (since all of the evidence and information is already in the Partner Center).
Does anyone have a recommendation for improving or automating the process? have i missed something in relation to the PoE form? any guidance would be appreciated.
I have joined an organisation as Head of Digital Transformation and Consultancy Services. As part of the role, I am responsible for the relationship with Microsoft and the Partner Centre. I am working to ensure we have now registered CPoR against our clients (and there are a lot) as it had not previously been done. It has been some time since I actually ran through the process and I have been alarmed how “manual” it is and how time consuming. The need to physically print off, manually complete the PoE form, scan, send to the client, client print, client sign, client scan, client send back is very 2003 and very time consuming. Also finding that different members of the review team want to see different things and so the process is turning into a difficult task when it doesn’t need to be (since all of the evidence and information is already in the Partner Center). Does anyone have a recommendation for improving or automating the process? have i missed something in relation to the PoE form? any guidance would be appreciated. Read More
IIS and PHP access permissions
Hi.
I’m not sure if this is a question for the IIS community, or the PHP forum, but since most of the guys running PHP seem to do this under Apache and Linux, I’d like to try here first:
Most of our sites in IIS run PHP and connects as Application user. A couple of them are web shops and run WordPress and WooCommerce. Some of these are integrating through the WooCommerce REST API with external Point-of-Sale systems, which then require me to open up for GET, PUT, DELETE on the separate PHP-instances. Am I jeopardizing the security of this IIS application by doing this?
Thanks.
Hi. I’m not sure if this is a question for the IIS community, or the PHP forum, but since most of the guys running PHP seem to do this under Apache and Linux, I’d like to try here first: Most of our sites in IIS run PHP and connects as Application user. A couple of them are web shops and run WordPress and WooCommerce. Some of these are integrating through the WooCommerce REST API with external Point-of-Sale systems, which then require me to open up for GET, PUT, DELETE on the separate PHP-instances. Am I jeopardizing the security of this IIS application by doing this? Thanks. Read More

My computer can’t download the drivers i need for built in camera
I’m having trouble with my computer’s built-in camera. When I try to use the camera, it doesn’t seem to be functioning properly. The problem is that my computer is unable to download the necessary drivers for the camera. I’ve tried searching for the drivers online and following the instructions to install them, but nothing seems to work. I’ve also checked the device manager and it says that the camera is not recognized. I’ve tried restarting my computer and updating my graphics drivers, but that didn’t help either.
I’m not sure what’s causing the problem or how to fix it. I’ve tried using different cameras and they all work fine on other computers, so I’m hoping someone can help me figure out what’s going on and how to fix it.
I’m having trouble with my computer’s built-in camera. When I try to use the camera, it doesn’t seem to be functioning properly. The problem is that my computer is unable to download the necessary drivers for the camera. I’ve tried searching for the drivers online and following the instructions to install them, but nothing seems to work. I’ve also checked the device manager and it says that the camera is not recognized. I’ve tried restarting my computer and updating my graphics drivers, but that didn’t help either. I’m not sure what’s causing the problem or how to fix it. I’ve tried using different cameras and they all work fine on other computers, so I’m hoping someone can help me figure out what’s going on and how to fix it. Read More
Xlook up empty cell (repeat)
Hi team,
I applied Xlookup and found in my look up array there are some cells which are emptied and in return array there are different values for empty cells.
In my result I only see value from return array with first empty cell in look up array.
Can someone please help how to see /look empty cells from look up array in return array against different values?
thanks
Hi team, I applied Xlookup and found in my look up array there are some cells which are emptied and in return array there are different values for empty cells. In my result I only see value from return array with first empty cell in look up array. Can someone please help how to see /look empty cells from look up array in return array against different values? thanks Read More
Copilot’s Macedonian Language Support
Hi,
I have been using Copilot and noticed that, despite Macedonian not being listed as a supported language, the bot still responds reasonably well. It appears that when trained on a substantial amount of data, Copilot can handle Macedonian by focusing on keywords rather than full sentences.
Given this, I believe that enhancing Copilot’s support for Macedonian should be feasible and beneficial. Is there a possibility to prioritize this language in future updates? Additionally, could we expect improved sentence-level understanding and response accuracy as more data becomes available?
Thank you for considering this suggestion. I look forward to your feedback.
Best regards,
Nikola
Hi, I have been using Copilot and noticed that, despite Macedonian not being listed as a supported language, the bot still responds reasonably well. It appears that when trained on a substantial amount of data, Copilot can handle Macedonian by focusing on keywords rather than full sentences. Given this, I believe that enhancing Copilot’s support for Macedonian should be feasible and beneficial. Is there a possibility to prioritize this language in future updates? Additionally, could we expect improved sentence-level understanding and response accuracy as more data becomes available? Thank you for considering this suggestion. I look forward to your feedback.Best regards,Nikola Read More

Power Query to fetch the earliest record based on timestamp
I have two tables to calculate a response time value. It works like this: A job (e.. job number 98712) gets created (timestamp A). Then this job undergoes various workflow status to closure with the first one being ‘job status set to Connect: Onsite’ – timestamp B. The response time is timestamp B – A.
Now it’s possible that there are a few trips until this job gets closed and every trip has its own onsite timestamp as you can see in the example where the technician is onsite 4 times. So I need to load the very first entry (i.e. 1 May 9:31). The others 3 in this case are irrelevant. I create merge query to pull in this data based on job number.
How can I either update the load criteria or transform the data so that the calculation takes the first timestamp (timestamp B)
I have two tables to calculate a response time value. It works like this: A job (e.. job number 98712) gets created (timestamp A). Then this job undergoes various workflow status to closure with the first one being ‘job status set to Connect: Onsite’ – timestamp B. The response time is timestamp B – A. Now it’s possible that there are a few trips until this job gets closed and every trip has its own onsite timestamp as you can see in the example where the technician is onsite 4 times. So I need to load the very first entry (i.e. 1 May 9:31). The others 3 in this case are irrelevant. I create merge query to pull in this data based on job number. How can I either update the load criteria or transform the data so that the calculation takes the first timestamp (timestamp B) Read More
Upgrade the OData version to V4 in SharePoint
Kindly we have Odata V3 is assigned in our SharPoint tenant where we need to upgrade it to V4.
Could you please support me on all steps details?
Thanks
Kindly we have Odata V3 is assigned in our SharPoint tenant where we need to upgrade it to V4.Could you please support me on all steps details?Thanks Read More
What should i do to become a certified Azure Solutions Architect?
I want to become a certified Azure Solutions Architect because I am interested in cloud computing and Microsoft Azure. Certification will give my skills and knowledge industry recognition and open new pathways for career growth. I wanted to know the steps involved so that I can prepare accordingly.
I want to become a certified Azure Solutions Architect because I am interested in cloud computing and Microsoft Azure. Certification will give my skills and knowledge industry recognition and open new pathways for career growth. I wanted to know the steps involved so that I can prepare accordingly. Read More
how to substitute or mask “#VALUE!” on the fly without creating a intermediate cell/formula
I have the following formula:
=IF(SEARCH(“XYZ”, Product),Product, 0)
where:
Product is a named area in a spreadsheet.
From time to time the pattern “XYZ” is not found (and it should be so) and the formula returns #VALUE! , as it should.
In a different blog/thread I have found that I can use
=IF(COUNTIF(A1,”#Value!”),NA(),””)
=IF(ISERROR(A1),NA(),””)
to mask the a specific error, or value, or to capture all error cases.
But joining my formula and one of the previous suggestions, I receive an error and the formula is not accepted by excel.
=IF( COUNTIF( SEARCH(“XYZ”, Product) , “#Value!” ), Product, 0)
(I have added “blanks” to improve readability).
Using:
=IF( ISERROR( SEARCH(“XYZ”, Product) ) , Product, 0)
does nothing reasonable and always shows the value of Product as if no error is ever raised, indeed it is as if the SEARCH function was not there.
Any suggestions?
thx
I have the following formula:=IF(SEARCH(“XYZ”, Product),Product, 0)where:Product is a named area in a spreadsheet.From time to time the pattern “XYZ” is not found (and it should be so) and the formula returns #VALUE! , as it should. In a different blog/thread I have found that I can use=IF(COUNTIF(A1,”#Value!”),NA(),””)=IF(ISERROR(A1),NA(),””)to mask the a specific error, or value, or to capture all error cases. But joining my formula and one of the previous suggestions, I receive an error and the formula is not accepted by excel.=IF( COUNTIF( SEARCH(“XYZ”, Product) , “#Value!” ), Product, 0)(I have added “blanks” to improve readability). Using:=IF( ISERROR( SEARCH(“XYZ”, Product) ) , Product, 0)does nothing reasonable and always shows the value of Product as if no error is ever raised, indeed it is as if the SEARCH function was not there. Any suggestions?thx Read More

Always Encrypted vs Always Encrypted with secure enclaves
Introduction
Encryption is a vital technique for protecting sensitive data from unauthorized access or modification. SQL Server and Azure SQL Database offer two encryption technologies that allow you to encrypt data in use: Always Encrypted and Always Encrypted with secure enclaves. In this blog post, we will compare these two technologies and highlight their benefits and limitations.
What is Always Encrypted?
We began our journey towards the confidential computing vision in 2015 and we introduced the first version of Always Encrypted in SQL Server 2016 and Azure SQL Database. Always Encrypted is a client-side encryption technology where the client driver transparently encrypts query parameters and decrypts encrypted results. The data gets encrypted on the client side (inside the client driver) before being stored in the database. The data is never decrypted inside the database. The encryption keys are never exposed to the database engine, ensuring that the data stays secure even if the database is breached.
Always Encrypted provides strong encryption, but computations on protected data is limited to just one operation – equality comparison, which is supported via deterministic encryption. All other operations, including cryptographic operations (initial data encryption or key rotation) and richer queries (for example, pattern matching) aren’t supported inside the database. Users need to move their data outside of the database to perform these operations on the client-side.
What is Always Encrypted with secure enclaves?
Always Encrypted with secure enclaves is an enhancement of Always Encrypted that enables rich computations on encrypted data. When processing SQL queries, the database engine delegates computations on encrypted data to a secure enclave. The enclave decrypts the data and performs computations on plaintext. This can be done safely, because the enclave is a black box to the containing database engine process and the OS, so DBAs or machine admins cannot see the data inside the enclave.
Always Encrypted supports the following enclave technologies (or enclave types):
Virtualization-based Security (VBS) enclaves (also known as Virtual Secure Mode, or VSM enclaves) – a software-based technology that relies on Windows hypervisor and doesn’t require any special hardware.
Intel Software Guard Extensions (Intel SGX) enclaves – a hardware-based trusted execution environment technology.
What are the differences between Always Encrypted and Always Encrypted with secure enclaves?
Always Encrypted
Always Encrypted with secure enclaves
Version
Introduced in SQL Server 2016 and Azure SQL Database in 2015. Also available in Azure SQL Managed Instance and CosmosDB
Available from SQL Server 2019 and later, as well as in Azure SQL Database
Trusted Execution Environment
Ensures data confidentiality by encrypting it on the client side.
Utilizes a secure enclave. which is a trusted execution environment that can safely access cryptographic keys and sensitive data in plaintext without compromising confidentiality.
Initial Encryption and key rotation
Encrypts data on the client side
Cryptographic operations on database columns inside the secure enclave on the server side. The data can stay inside the database.
Confidential Queries
Limits queries to equality comparisons only (only available with deterministic encryption)
Allows richer confidential queries, including pattern matching, range comparisons, and sorting.
In essence, Always Encrypted with secure enclaves provides more flexibility and functionality for querying and managing encrypted data while maintaining a high level of security. It leverages secure enclave technology to allow certain computations to be performed on encrypted columns directly inside the database, without exposing sensitive data outside of the enclave.
Why do people still use Always Encrypted instead of Always Encrypted with secure enclaves?
I noticed that many customers are still creating new databases without using an enclave, even though we have learned that Always Encrypted with secure enclaves offers you more flexibility and functionality. So, what is the explanation for this? I contacted many of these customers and the main reasons are the following:
They are not aware of Always Encrypted with secure enclaves.
They don’t need the functionality. They only need to encrypt PII information but there is no need to use it for filtering or in a where-clause.
Their application already works with Always Encrypted and they don’t have resources, time or budget to migrate to Always Encrypted with secure enclaves.
So, I’m interested in your opinion. Are you using Always Encrypted? Or are you planning to use it? What is the reason why you’re not using it with enclaves? Please let me know on this form. It would be great to get some more insights.
Learn more
Always Encrypted with secure enclaves documentation
How to convert Always Encrypted to Always Encrypted with Secure Enclaves – Microsoft Community Hub
Getting started using Always Encrypted with secure enclaves
GitHub Demo
Data Exposed episode (video)
Microsoft Tech Community – Latest Blogs –Read More
Doing RAG? Vector search is *not* enough
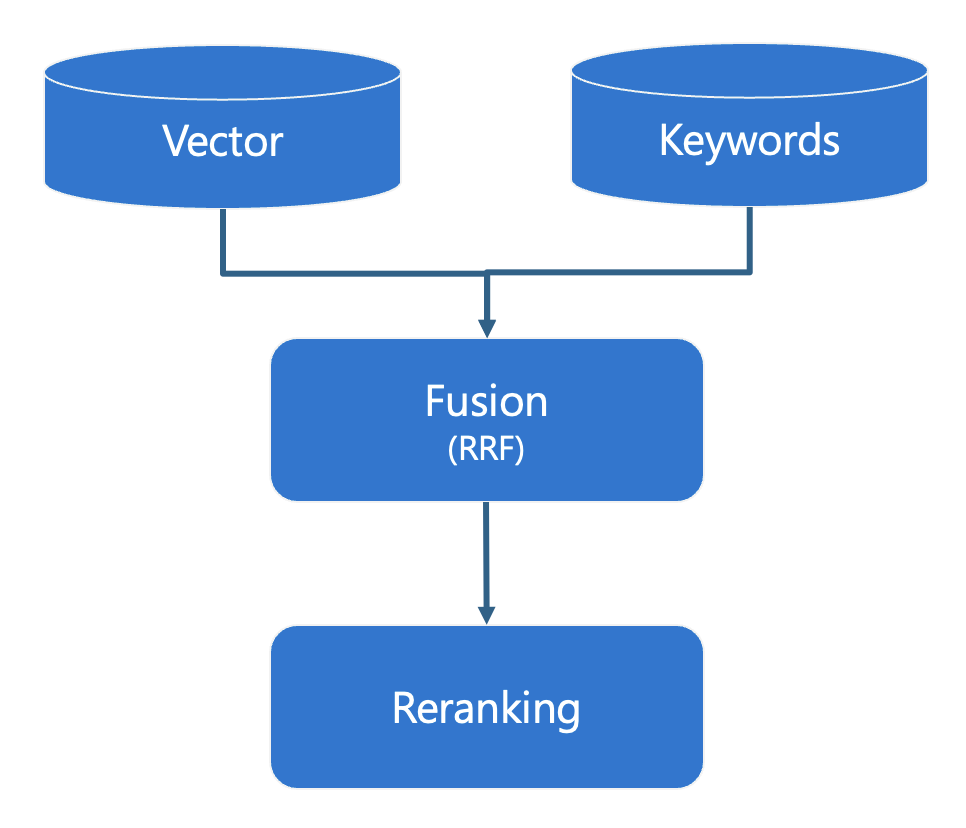
I’m concerned by the number of times I’ve heard, “oh, we can do RAG with retriever X, here’s the vector search query.” Yes, your retriever for a RAG flow should definitely support vector search, since that will let you find documents with similar semantics to a user’s query, but vector search is not enough. Your retriever should support a full hybrid search, meaning that it can perform both a vector search and full text search, then merge and re-rank the results. That will allow your RAG flow to find both semantically similar concepts, but also find exact matches like proper names, IDs, and numbers.
Hybrid search steps
Azure AI Search offers a full hybrid search with all those components:
It performs a vector search using a distance metric (typically cosine or dot product).
It performs a full-text search using the BM25 scoring algorithm.
It merges the results using Reciprocal Rank Fusion algorithm.
It re-ranks the results using semantic ranker, a machine learning model used by Bing, that compares each result to the original usery query and assigns a score from 0-4.
The search team even researched all the options against a standard dataset, and wrote a blog post comparing the retrieval results for full text search only, vector search only, hybrid search only, and hybrid plus ranker. Unsurprisingly, they found that the best results came from using the full stack, and that’s why it’s the default configuration we use in the AI Search RAG starter app.
When is hybrid search needed?
To demonstrate the importance of going beyond vector search, I’ll show some queries based off the sample documents in the AI Search RAG starter app. Those documents are from a fictional company and discuss internal policies like healthcare and benefits.
Let’s start by searching “what plan costs $45.00?” with a pure vector search using an AI Search index:
search_query = “what plan costs $45.00”
search_vector = get_embedding(search_query)
r = search_client.search(None, top=3, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=50, fields=”embedding”)])
The results for that query contain numbers and costs, like the string “The copayment for primary care visits is typically around $20, while specialist visits have a copayment of around $50.”, but none of the results contain an exact cost of $45.00, what the user was looking for.
Now let’s try that query with a pure full-text search:
r = search_client.search(search_query, top=3)
The top result for that query contain a table of costs for the health insurance plans, with a row containing $45.00.
Of course, we don’t want to be limited to full text queries, since many user queries would be better answered by vector search, so let’s try this query with hybrid:
r = search_client.search(search_query, top=15, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=10, fields=”embedding”)])
Once again, the top result is the table with the costs and exact string of $45.00. When the user asks that question in the context of the full RAG app, they get the answer they were hoping for:
You might think, well, how many users are searching for exact strings? Consider how often you search your email for a particular person’s name, or how often you search the web for a particular programming function name. Users will make queries that are better answered by full-text search, and that’s why we need hybrid search solutions.
Here’s one more reason why vector search alone isn’t enough: assuming you’re using generic embedding models like the OpenAI models, those models are generally not a perfect fit for your domain. Their understanding of certain terms aren’t going to be the same as a model that was trained entirely on your domain’s data. Using hybrid search helps to compensate for the differences in the embedding domain.
When is re-ranking needed?
Now that you’re hopefully convinced about hybrid search, let’s talk about the final step: re-ranking results according to the original user query.
Now we’ll search the same documents for “learning about underwater activities” with a hybrid search:
search_query = “learning about underwater activities”
search_vector = get_embedding(search_query)
r = search_client.search(search_query, top=5, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=10, fields=”embedding”)])
The third result for that query contains the most relevant result, a benefits document that mentions surfing lessons and scuba diving lessons. The phrase “underwater” doesn’t appear in any documents, notably, so those results are coming from the vector search component.
What happens if we add in the semantic ranker?
search_query = “learning about underwater activities”
search_vector = get_embedding(search_query)
r = search_client.search(search_query, top=5, vector_queries=[
VectorizedQuery(search_vector, k_nearest_neighbors=50, fields=”embedding”)],
query_type=”semantic”, semantic_configuration_name=”default”)
Now the very top result for the query is the document chunk about surfing and scuba diving lessons, since the semantic ranker realized that was the most pertinent result for the user query. When the user asks a question like that in the RAG flow, they get a correct answer with the expected citation:
Our search yielded the right result in both cases, so why should we bother with the ranker? For RAG applications, which send search results to an LLM like GPT-3.5, we typically limit the number of results to a fairly low number, like 3 or 5 results. That’s due to research that shows that LLMs tend to get “lost in the middle” when too much context is thrown at them. We want those top N results to be the most relevant results, and to not contain any irrelevant results. By using the re-ranker, our top results are more likely to contain the closest matching content for the query.
Plus, there’s a big additional benefit: each of the results now has a re-ranker score from 0-4, which makes it easy for us to filter out results with re-ranker scores below some threshold (like < 1.5). Remember that any search algorithm that includes vector search will always find results, even if those results aren’t very close to the original query at all, since vector search just looks for the closest vectors in the entire vector space. So when your search involves vector search, you ideally want a re-ranking step and a scoring approach that will make it easier for you to discard results that just aren’t relevant enough on an absolute scale.
Implementing hybrid search
As you can see from my examples, Azure AI Search can do everything we need for a RAG retrieval solution (and even more than we’ve covered here, like filters and custom scoring algorithms. However, you might be reading this because you’re interested in using a different retriever for your RAG solution, such as a database. You should be able to implement hybrid search on top of most databases, provided they have some capability for text search and vector search.
As an example, consider the PostgreSQL database. It already has built-in full text search, and there’s a popular extension called pgvector for bringing in vector indexes and distance operators. The next step is to combine them together in a hybrid search, which is demonstrated in this example from the pgvector-python repository:.
WITH semantic_search AS (
SELECT id, RANK () OVER (ORDER BY embedding <=> %(embedding)s) AS rank
FROM documents
ORDER BY embedding <=> %(embedding)s
LIMIT 20
),
keyword_search AS (
SELECT id, RANK () OVER (ORDER BY ts_rank_cd(to_tsvector(‘english’, content), query) DESC)
FROM documents, plainto_tsquery(‘english’, %(query)s) query
WHERE to_tsvector(‘english’, content) @@ query
ORDER BY ts_rank_cd(to_tsvector(‘english’, content), query) DESC
LIMIT 20
)
SELECT
COALESCE(semantic_search.id, keyword_search.id) AS id,
COALESCE(1.0 / (%(k)s + semantic_search.rank), 0.0) +
COALESCE(1.0 / (%(k)s + keyword_search.rank), 0.0) AS score
FROM semantic_search
FULL OUTER JOIN keyword_search ON semantic_search.id = keyword_search.id
ORDER BY score DESC
LIMIT 5
That SQL performs a hybrid search by running a vector search and text search and combining them together with RRF.
Another example from that repo shows how we could bring in a cross-encoding model for a final re-ranking step:
encoder = CrossEncoder(‘cross-encoder/ms-marco-MiniLM-L-6-v2’)
scores = encoder.predict([(query, item[1]) for item in results])
results = [v for _, v in sorted(zip(scores, results), reverse=True)]
That code would run the cross-encoding model in the same process as the rest of the PostgreSQL query, so it could work well in a local or test environment, but it wouldn’t necessarily scale well in a production environment. Ideally, a call to a cross-encoder would be made in a separate service that had access to a GPU and dedicated resources.
I have implemented the first three steps of hybrid search in a RAG-on-PostgreSQL starter app. Since I don’t yet have a good way to productionize a call to a cross-encoding model, I have not brought in the final re-ranking step.
After seeing what it takes to replicate full hybrid search options on other database, I am even more appreciative of the work done by the Azure AI Search team. If you’ve decided that, nevermind, you’ll go with Azure AI Search, check out the AI Search RAG starter app. You might also check out open source packages, such as llamaindex which has at least partial hybrid search support for a number of databases. If you’ve used or implemented hybrid search on a different database, please share your experience in the comments.
When in doubt, evaluate
When choosing our retriever and retriever options for RAG applications, we need to evaluate answer quality. I stepped through a few example queries above, but for a user-facing app, we really need to do bulk evaluations of a large quantity of questions (~200) to see the effect of an option on answer quality. To make it easier to run bulk evaluations, I’ve created the ai-rag-chat-evaluator repository, that can run both GPT-based metrics and code-based metrics against RAG chat apps.
Here are the results from evaluations against a synthetically generated data set for a RAG app based on all my personal blog posts:
search mode
groundedness
relevance
answer_length
citation_match
vector only
2.79
1.81
366.73
0.02
text only
4.87
4.74
662.34
0.89
hybrid
3.26
2.15
365.66
0.11
hybrid with ranker
4.89
4.78
670.89
0.92
Despite being the author of this blog post, I was shocked to see how poorly vector search did on its own, with an average groundedness of 2.79 (out of 5) and only 2% of the answers with citations matching the ground truth citations. Full-text search on its own did fairly well, with an average groundedness of 4.87 and a citation match rate of 89%. Hybrid search without the semantic ranker improved upon vector search, with an average groundedness of 3.26 and citation match of 11%, but it did much better with the semantic ranker, with an average groundedness of 4.89 and a citation match rate of 92%. As we would expect, that’s the highest numbers across all the options.
But why do we see vector search and ranker-less hybrid search scoring so remarkably low? Besides what I’ve talked about above, I think it’s also due to:
The full-text search option in Azure AI Search is really good. It uses BM25 and is fairly battle-tested, having been around for many years before vector search became so popular. The BM25 algorithm is based off TF-IDF and produces something like sparse vectors itself, so it’s more advanced than a simple substring search. AI Search also uses standard NLP tricks like stemming and spell check. Many databases have full text search capabilities, but they won’t all be as full-featured as the Azure AI Search full-text search.
My ground truth data set is biased towards compatibility with full-text-search. I generated the sample questions and answers by feeding my blog posts to GPT-4 and asking it to come up with good Q&A based off the text, so I think it’s very likely that GPT-4 chose to use similar wording as my posts. An actual question-asker might use very different wording – heck, they might even ask in a different language like Spanish or Chinese! That’s where vector search could really shine, and where full-text search wouldn’t do so well. It’s a good reminder of why need to continue updating evaluation data sets based off what our RAG chat users ask in the real world.
So in conclusion, if we are going to go down the path of using vector search, it is absolutely imperative that we employ a full hybrid search with all four steps and that we evaluate our results to ensure we’re using the best retrieval options for the job.
Microsoft Tech Community – Latest Blogs –Read More
Teams No Audio
Hello
Please i need your help on this issue.
Our client is having issues with Teams Phone calls and no audio. This issue started on 6/4 and has been on and off. Are there any Teams related issues that are affecting audio via a Teams call?
Hello Please i need your help on this issue. Our client is having issues with Teams Phone calls and no audio. This issue started on 6/4 and has been on and off. Are there any Teams related issues that are affecting audio via a Teams call? Read More
盛世公司开户注册怎么样
盛世集团公司开户注册lx6789122,通常需要遵循以下一般步骤:准备相关资料:可能包括个人或企业身份证明、联系方式、地址证明等。联系盛世集团:通过其官方网站、客服渠道等,了解具体开户注册流程和所需资料要求。填写表格:按照要求如填写相关信息。提交资料:将准备好的资料提交给盛世集团,可能通过线上提交或线下提交的方式。等待审核:公司同意提交的资料进行审核。完成审核:审核通过后,即可成功开户注册。需要注意的是,具体步骤和要求可能因盛世集团的规定而有所不同。建议您与该公司进行详细沟通,以确保顺利完成开户注册。
盛世集团公司开户注册lx6789122,通常需要遵循以下一般步骤:准备相关资料:可能包括个人或企业身份证明、联系方式、地址证明等。联系盛世集团:通过其官方网站、客服渠道等,了解具体开户注册流程和所需资料要求。填写表格:按照要求如填写相关信息。提交资料:将准备好的资料提交给盛世集团,可能通过线上提交或线下提交的方式。等待审核:公司同意提交的资料进行审核。完成审核:审核通过后,即可成功开户注册。需要注意的是,具体步骤和要求可能因盛世集团的规定而有所不同。建议您与该公司进行详细沟通,以确保顺利完成开户注册。 Read More
盛世公司在线客服注册
盛世集团公司开户注册lx6789122,通常需要遵循以下一般步骤:准备相关资料:可能包括个人或企业身份证明、联系方式、地址证明等。联系盛世集团:通过其官方网站、客服渠道等,了解具体开户注册流程和所需资料要求。填写表格:按照要求如填写相关信息。提交资料:将准备好的资料提交给盛世集团,可能通过线上提交或线下提交的方式。等待审核:公司同意提交的资料进行审核。完成审核:审核通过后,即可成功开户注册。需要注意的是,具体步骤和要求可能因盛世集团的规定而有所不同。建议您与该公司进行详细沟通,以确保顺利完成开户注册。
盛世集团公司开户注册lx6789122,通常需要遵循以下一般步骤:准备相关资料:可能包括个人或企业身份证明、联系方式、地址证明等。联系盛世集团:通过其官方网站、客服渠道等,了解具体开户注册流程和所需资料要求。填写表格:按照要求如填写相关信息。提交资料:将准备好的资料提交给盛世集团,可能通过线上提交或线下提交的方式。等待审核:公司同意提交的资料进行审核。完成审核:审核通过后,即可成功开户注册。需要注意的是,具体步骤和要求可能因盛世集团的规定而有所不同。建议您与该公司进行详细沟通,以确保顺利完成开户注册。 Read More







