

Category: Microsoft
Category Archives: Microsoft
Microsoft Copilot for Sales is here!
Microsoft Copilot for Sales is here! The next step in the evolution of Viva Sales and Sales Copilot was released on February 1, 2024 for Dynamics 365 Sales and Salesforce CRM. You can read the announcement about the general availability of Copilot for Sales (and Copilot for Service) and learn what’s new.
With Copilot for Sales, we bring together the power of Copilot for Microsoft 365 with role-specific insights and actions to streamline business processes, automate repetitive tasks, and unlock productivity. We still provide the flexibility to integrate with Microsoft Dynamics 365 Sales and Salesforce to get more done with less effort.
Check out the Copilot for Sales Adoption Center where we provide resources to deploy, use, and scale Copilot for you, your team, and your organization!
Get started
Ready to join us and other top-performing sales organizations worldwide? Reach out to your Microsoft sales team or visit our product web page.
Ready to install? Have a look at our deployment guides for Dynamics 365 Sales users or for Salesforce users.
Stay connected
Keep up to date on the latest improvements at https://aka.ms/salescopilotupdates and learn what we’re planning next. Join our community in the community discussion forum and we always welcome your feedback and ideas in our product feedback portal.
Microsoft Tech Community – Latest Blogs –Read More
Microsoft Copilot for Sales is here!
Microsoft Copilot for Sales is here! The next step in the evolution of Viva Sales and Sales Copilot was released on February 1, 2024 for Dynamics 365 Sales and Salesforce CRM. You can read the announcement about the general availability of Copilot for Sales (and Copilot for Service) and learn what’s new.
With Copilot for Sales, we bring together the power of Copilot for Microsoft 365 with role-specific insights and actions to streamline business processes, automate repetitive tasks, and unlock productivity. We still provide the flexibility to integrate with Microsoft Dynamics 365 Sales and Salesforce to get more done with less effort.
Check out the Copilot for Sales Adoption Center where we provide resources to deploy, use, and scale Copilot for you, your team, and your organization!
Get started
Ready to join us and other top-performing sales organizations worldwide? Reach out to your Microsoft sales team or visit our product web page.
Ready to install? Have a look at our deployment guides for Dynamics 365 Sales users or for Salesforce users.
Stay connected
Keep up to date on the latest improvements at https://aka.ms/salescopilotupdates and learn what we’re planning next. Join our community in the community discussion forum and we always welcome your feedback and ideas in our product feedback portal.
Microsoft Tech Community – Latest Blogs –Read More
Microsoft Copilot for Sales is here!
Microsoft Copilot for Sales is here! The next step in the evolution of Viva Sales and Sales Copilot was released on February 1, 2024 for Dynamics 365 Sales and Salesforce CRM. You can read the announcement about the general availability of Copilot for Sales (and Copilot for Service) and learn what’s new.
With Copilot for Sales, we bring together the power of Copilot for Microsoft 365 with role-specific insights and actions to streamline business processes, automate repetitive tasks, and unlock productivity. We still provide the flexibility to integrate with Microsoft Dynamics 365 Sales and Salesforce to get more done with less effort.
Check out the Copilot for Sales Adoption Center where we provide resources to deploy, use, and scale Copilot for you, your team, and your organization!
Get started
Ready to join us and other top-performing sales organizations worldwide? Reach out to your Microsoft sales team or visit our product web page.
Ready to install? Have a look at our deployment guides for Dynamics 365 Sales users or for Salesforce users.
Stay connected
Keep up to date on the latest improvements at https://aka.ms/salescopilotupdates and learn what we’re planning next. Join our community in the community discussion forum and we always welcome your feedback and ideas in our product feedback portal.
Microsoft Tech Community – Latest Blogs –Read More
Microsoft Copilot for Sales is here!
Microsoft Copilot for Sales is here! The next step in the evolution of Viva Sales and Sales Copilot was released on February 1, 2024 for Dynamics 365 Sales and Salesforce CRM. You can read the announcement about the general availability of Copilot for Sales (and Copilot for Service) and learn what’s new.
With Copilot for Sales, we bring together the power of Copilot for Microsoft 365 with role-specific insights and actions to streamline business processes, automate repetitive tasks, and unlock productivity. We still provide the flexibility to integrate with Microsoft Dynamics 365 Sales and Salesforce to get more done with less effort.
Check out the Copilot for Sales Adoption Center where we provide resources to deploy, use, and scale Copilot for you, your team, and your organization!
Get started
Ready to join us and other top-performing sales organizations worldwide? Reach out to your Microsoft sales team or visit our product web page.
Ready to install? Have a look at our deployment guides for Dynamics 365 Sales users or for Salesforce users.
Stay connected
Keep up to date on the latest improvements at https://aka.ms/salescopilotupdates and learn what we’re planning next. Join our community in the community discussion forum and we always welcome your feedback and ideas in our product feedback portal.
Microsoft Tech Community – Latest Blogs –Read More
Sync Up Episode 08: From Waterfalls to Weekly Releases with Steven Bailey & John Selbie
Ever wanted to learn more about what goes into making OneDrive? Then this is the podcast for you! Join Stephen Rice and Arvind Mishra as they talk with CVP for OneDrive Engineering, Steven Bailey and engineering Manager John Selbie! This month, we’re talking about how OneDrive became the product that it is today, how engineering itself has evolved at Microsoft, and how the OneDrive engineering team strives to deliver a product that surpasses your expectations!
Microsoft Tech Community – Latest Blogs –Read More
Auto Rollout of Conditional Access Policies in Microsoft Entra ID
In November 2023 at Microsoft Ignite, we announced Microsoft-managed policies and the auto-rollout of multifactor authentication (MFA)-related Conditional Access policies in customer tenants. Since then, we’ve rolled out report-only policies for over 500,000 tenants. These policies are part of our Secure Future Initiative, which includes key engineering advances to improve security for customers against cyberthreats that we anticipate will increase over time.
This follow-up blog will dive deeper into these policies to provide you with a comprehensive understanding of what they entail and how they function.
Multifactor authentication for admins accessing Microsoft admin portals
Admin accounts with elevated privileges are more likely to be attacked, so enforcing MFA for these roles protects these privileged administrative functions. This policy covers 14 admin roles that we consider to be highly privileged, requiring administrators to perform multifactor authentication when signing into Microsoft admin portals. This policy targets Microsoft Entra ID P1 and P2 tenants, where security defaults aren’t enabled.
Multifactor authentication for per-user multifactor authentication users
Per-user MFA is when users are enabled individually and are required to perform multifactor authentication each time they sign in (with some exceptions, such as when they sign in from trusted IP addresses or when the remember MFA on trusted devices feature is turned on). For customers who are licensed for Entra ID P1, Conditional Access offers a better admin experience with many additional features, including user group and application targeting, more conditions such as risk- and device-based, integration with authentication strengths, session controls and report-only mode. This can help you be more targeted in requiring MFA, lowering end user friction while maintaining security posture.
This policy covers users with per-user MFA. These users are targeted by Conditional Access and are now required to perform multifactor authentication for all cloud apps. It aids organizations’ transition to Conditional Access seamlessly, ensuring no disruption to end user experiences while maintaining a high level of security.
This policy targets licensed users with Entra ID P1 and P2, where the security defaults policy isn’t enabled and there are less than 500 per-user MFA enabled enabled/enforced users. There will be no change to the end user experience due to this policy.
Multifactor authentication and reauthentication for risky sign-ins
This policy will help your organization achieve the Optimal level for Risk Assessments in the NIST Zero Trust Maturity Model because it provides a key layer of added security assurance that triggers only when we detect high-risk sign-ins. “High-risk sign-in” means there is a very high probability that a given authentication request isn’t the authorized identity owner and could indicate brute force, password spray, or token replay attacks. By dynamically responding to sign-in risk, this policy disrupts active attacks in real-time while remaining invisible to most users, particularly those who don’t have high sign-in risk. When Identity Protection detects an attack, your users will be prompted to self-remediate with MFA and reauthenticate to Entra ID, which will reset the compromised session.
This policy covers all users in Entra ID P2 tenants, where security defaults aren’t enabled, all active users are already registered for MFA, and there are enough licenses for each user. As with all policies, ensure you exclude any break-glass or service accounts to avoid locking yourself out.
Microsoft-managed Conditional Access policies have been created in all eligible tenants in Report-only mode. These policies are suggestions from Microsoft that organizations can adapt and use for their own environment. Administrators can view and review these policies in the Conditional Access policies blade. To enhance the policies, administrators are encouraged to add customizations such as excluding emergency accounts and service accounts. Once ready, the policies can be moved to the ON state. For additional customization needs, administrators have the flexibility to clone the policies and make further adjustments.
Call to Action
Don’t wait – take action now. Enable the Microsoft-managed Conditional Access policies now and/or customize the Microsoft-managed Conditional Access policies according to your organizational needs. Your proactive approach to implementing multifactor authentication policies is crucial in fortifying your organization against evolving security threats. To learn more about how to secure your resources, visit our Microsoft-managed policies documentation.
Nitika Gupta
Principal Group Product Manager, Microsoft
Learn more about Microsoft Entra:
See recent Microsoft Entra blogs
Dive into Microsoft Entra technical documentation
Learn more at Azure Active Directory (Azure AD) rename to Microsoft Entra ID
Join the conversation on the Microsoft Entra discussion space and Twitter
Learn more about Microsoft Security
Microsoft Tech Community – Latest Blogs –Read More
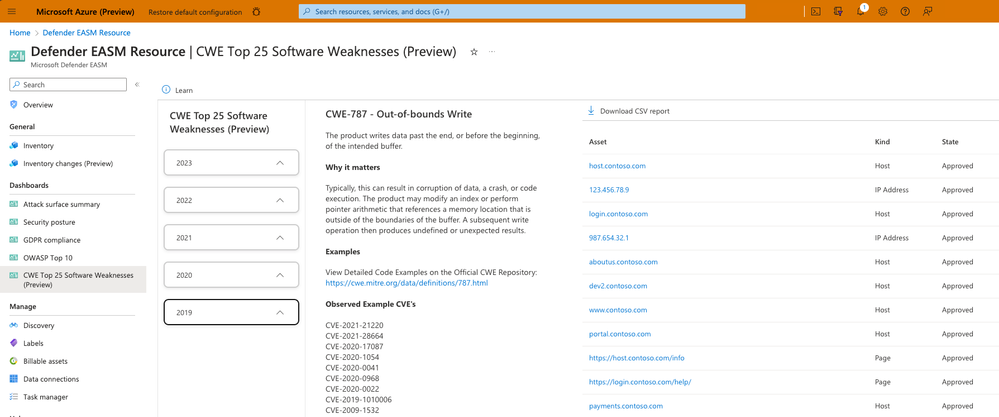
Latest Defender EASM Features Increase Visibility and Enhance Querying for Faster Remediation
Microsoft Defender External Attack Surface Management (Defender EASM) discovers and classifies assets and workloads across your organization’s digital presence to enable teams to understand and prioritize exposed weaknesses in cloud, SaaS, and IaaS resources to strengthen security posture. Features recently added increase CWE and CVE visibility and boost query efficiency so users can focus on finding the information that’s most important to their environment. Below, learn about these powerful new enhancements and how you can begin using them today.
New Features
CWE Top 25 Software Weaknesses dashboard
The Top 25 Common Weakness Enumeration (CWE) list is provided annually by MITRE. These CWEs represent the most common and impactful software weaknesses that are easy to find and exploit. This dashboard displays all CWEs included on the list over the last five years, listing all inventory assets that might be impacted by each CWE. Referencing this dashboard saves you research time and helps your vulnerability remediation efforts by helping you identify the greatest risks to your organization based on other tangible observed exploits.
CISA Known Exploits dashboard
While there are hundreds of thousands of identified CVE vulnerabilities, only a small subset hasve been identified by the Cybersecurity & Infrastructure Security Agency (CISA) as recently exploited by threat actors. This list includes less than .5% of all identified CVEs; for this reason, it is instrumental to helping security professionals prioritize the remediation of the greatest risks to their organization. Those who remediate threats based on this list operate with the upmost efficiency because they’re prioritizing the vulnerabilities that have resulted in real security incidents.
Both new Defender EASM dashboards are designed to help users find the threats that pose the greatest threat to their organization as efficiently as possible. To learn more about dashboards, see our help documentation.
Push notifications
Users now receive one-time push notifications in the Azure portal to alert them of key updates to their attack surface. These notifications are designed to guide users to the information that helps them create a comprehensive external attack surface and efficiently manage their ever-changing digital landscape. Users can expect notifications in the following instances:
Free Trial Ending (within 10 days): when you login to Defender EASM within 10 days of your free trial ending, you will receive a one-time notification that alerts you of the impending trial end.
New Insight published: if your external attack surface contains inventory assets that are potentially impacted by a new insight, you will receive a notification. Clicking the notification will route you to the detailed list of all assets that are affected by the insight.
Discovery run completion: when a discovery run is successfully completed and discovers new assets related to your external attack surface, you will receive a notification that “X (number) of assets” have been added to your inventory. Click this notification to view a list of the assets added to inventory through that particular discovery run.
Discovery run failure: when a discovery run fails, you will receive a push notification that routes you to the Discovery Group page when clicked. This page provides more details about the failure and offers the option to re-run the discovery.
Software Development Kits (SDKs) for Java and Javascript
Customers can now access client libraries for Javascript and Java that help them operationalize the Defender EASM REST API to automate processes and improve workflows. These SDKs are now available to customers in Public Preview.
Key enhancements
“NEW” flag for insights
New insights are now flagged with “NEW” on the “Attack surface priorities” charts and other areas in the UI. This helps customers quickly navigate to insights that they have not yet investigated, enabling better prioritization when reviewing your attack surface.
Discovery run improvements
Performance enhancements were completed on the backend of the discovery engine to enable larger asset counts to be brought into inventory with each discovery run. Furthermore, we have added tooltips to the Discovery Group details page to provide more insight into failed discovery runs. By hovering over the information icon next to any failed discovery run within the Run History section, users can understand why their run failed and adjust accordingly before running another discovery, improving efficiency.
Filter editor redesign
Defender EASM has implemented a new design for filters that makes it easier for you to quickly query your inventory. Each query is now constructed from the main inventory page in a more visual format, making it easier to construct multiple queries before submitting. Unlike the previous filter design, these improvements allow users to view and edit all queries simultaneously before submitting the request, improving the ease of usability of the feature. In addition, we have added an “OR” operator for many filters, allowing you to quickly search for multiple desired results.
New attack surface insights
The Defender EASM team is constantly adding new insights to the platform to ensure that our users have visibility into the latest security threats. The follow insights were added to Defender EASM in the last three months.
Detectable insights
CVE-2023-42115 – Exim Unauthenticated Remote Code Execution
CVE-2023-40044 – WS_FTP Server Ad Hoc Transfer Unauthorized Deserialization
CVE-2023-22515 – Confluence Privilege Escalation
CVE-2023-42793 – TeamCity Unauthenticated Remote Code Execution
CVE-2023-38646 Metabase Unauthenticated Command Execution
CVE-2023-33246 – Apache RocketMQ Broker Unauthenticated Remote Command Injection
CVE-2023-22518 – Atlassian Confluence Improper Authorization
CVE-2023-47246 – SysAid Help Desk Path Traversal to Remote Code Execution
CVE-2023-46604 – Apache ActiveMQ OpenWire Broker Remote Code Execution
CVE-2023-45849 – Perforce Helix Core Unauthenticated Remote Code Execution over RPC
Potential Insights
Potential Insights are created when a vulnerable version of software has not been detected and needs to be validated by the customer. Customers using this software should check if they have the vulnerable versions highlighted in the insight:
[Potential] August 2023 Juniper Junos OS Multiple Vulnerabilities in J-Web
[Potential] CVE-2023-40044 – WS_FTP Server Ad Hoc Transfer Unauthorized Deserialization
[Potential] CVE-2023-4966 – Citrix NetScaler Gateway and NetScaler ADC Session Token Leak
[Potential] CVE-2023-20198 & CVE-2023-20273 – Cisco IOS XE Authorization Bypass and Privilege Escalation
[Potential] CVE-2023-46747 – F5 BIG-IP Unauthenticated AJP Smuggling
[Potential] CVE-2023-41998 – Arcserve UDP Multiple Vulnerabilities
[Potential] CVE-2023-48365 – Qlik Sense Unauthenticated Remote Code Execution
[Potential] CVE-2023-50164 – Struts2 Unauthenticated File Traversal and Upload to Remote Code Execution
We want to hear from you!
MDEASM is made by security professionals for security professionals. Join our community of security pros and experts to provide product feedback and suggestions and start conversations about how MDEASM helps you manage your attack surface and strengthen your security posture. With an open dialogue, we can create a safer internet together.
Microsoft Tech Community – Latest Blogs –Read More
Announcing OpenAI text-to-speech voices on Azure OpenAI Service and Azure AI Speech
At OpenAI DevDay on November 6th 2023, OpenAI announced a new text-to-speech (TTS) model that offers 6 preset voices to choose from, in their standard format as well as their respective high-definition (HD) equivalents. Today, we are excited to announce that we are bringing those models in preview to Azure. Developers can now access OpenAI’s TTS voices through Azure OpenAI and Azure AI Speech services. Each of the 6 voices has its own personality and style. The standard voices models are optimized for real-time use cases, and the HD equivalents are optimized for quality.
These new TTS voices augment capabilities, such as building custom voices and avatars, already available in Azure AI and allow customers to build entirely new experiences across customer support, training videos, live-streaming and more.
This capability allows developers to give human-like voices to chatbots, audiobook or article narration, translation across multiple languages, content creation for games and offers much-needed assistance to the visually impaired.
Click here to see these voices in action:
The new voices will support a wide range of languages from Afrikaans to Welsh, and the service can cater to diverse linguistic needs. For a complete list of supported languages, please follow this link.
The table below shows the 6 preset voices:
Voice
Sample Text
Sample Language (s)
Sample Audio
(Standard)
Sample Audio
(HD)
Alloy
The world is full of beauty when your heart is full of love.
Le monde est plein de beauté quand votre cœur est plein d’amour.
English- French
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_alloy.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_alloyHD.wav
Echo
Well, John, that’s very kind of you to invite me to your quarters. I’m flattered that you want to spend more time with me.
Des efforts de collaboration entre les pays sont nécessaires pour lutter contre le changement climatique, protéger les océans et préserver les écosystèmes fragiles.
English – French
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_echo.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_echoHD.wav
Fable
Success is not the key to happiness, but happiness is the key to success.
Erfolg ist nicht der Schlüssel zum Glück, aber Glück ist der Schlüssel zum Erfolg.
English – German
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_fable.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_fableHD.wav
Onyx
Conserving water resources through efficient usage and implementing responsible water management practices is crucial, especially in regions prone to drought and water scarcity.
Die Einführung nachhaltiger Praktiken in unserem täglichen Leben, wie z. B. die Einsparung von Wasser und Energie, die Auswahl umweltfreundlicher Produkte und die Reduzierung unseres CO2-Fußabdrucks, kann erhebliche positive Auswirkungen auf die Umwelt haben.
English – German
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_onyx.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_onyxHD.wav
Nova
Success is not the key to happiness, but happiness is the key to success.
El éxito no es la clave de la felicidad, pero la felicidad es la clave del éxito.
English – Spanish
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_nova.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_novaHD.wav
Shimmer
In this moment, I realized that amid the chaos of life, tranquility and peace can always be found.
人生は、一度きりのチャンスです。失敗しても、次に向けて立ち上がりましょう。
English – Japanese
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_Shimmer.wav
https://nerualttswaves.blob.core.windows.net/oai-samples/test_oai_ShimmerHD.wav
In addition to making these voices available in Azure OpenAI Service, customers will also find them in the Azure AI Speech with the added support for Speech Synthesis Markup Language (SSML) SDK.
Getting started
With these updates, we’re excited to be powering natural and intuitive voice experiences for more customers.
For more information:
Try the demo from AI Studio
See our documentation (AI Speech Learn doc link)
Check out our sample code
Microsoft Tech Community – Latest Blogs –Read More
IPv6 Transition Technology Survey
The journey toward IPv6 only networking is challenging, and today there are several different approaches to the transition from IPv4 to IPv6 with multiple dual-stack or tunneling stages along the way. As we prioritize future Windows work, we would like to know more about what customers like you are using to support your own IPv6 deployments. We have published the survey below to ask you a few questions that will contribute to that exercise.
The survey is fairly short and anonymous (though we left a field for sharing your contact information if you would be ok with direct follow up). Thank you in advance for your responses; your experiences will help us focus on what you find most valuable in our future work.
Microsoft Tech Community – Latest Blogs –Read More

Migration and Modernization solutions for Windows-based applications to Azure Kubernetes Services
We’re excited to announce the launch of the Migration and Modernization Solutions page for Windows containers in Azure docs.
Azure Migrate, CAST and UnifyCloud are trusted solutions customers use to help with assessing, migrating and modernizing their applications to Windows containers.
We’ve partnered with each product team to showcase how to modernize the representative legacy eShop applications to Windows containers. The eShop demo provides three sample hypothetical legacy eShop web apps (traditional ASP.NET WebForms and MVC in .NET Framework and an N-Tier app based on a WCF service and a client WinForms desktop app).
We believe these hands-on examples will help you understand the available solutions available for you and make the best-informed decision to assist with your modernization initiatives.
If you are an interested partner or have any feedback about the Migration and Modernization Solutions page for Windows Containers, please let us know in the comments below.
Microsoft Tech Community – Latest Blogs –Read More

AI is for nonprofits: The journey starts here
AI is for nonprofits
This may have been a provocative headline months ago but after last week’s inaugural Global Nonprofit Leaders Summit, the verdict is in: AI is here, and it is for everyone when used responsibly. The summit kickstarted a new dialogue on AI for nonprofits that covered themes from responsible use to technical skilling and training, to collaborative models, to in-action use cases in program delivery, marketing, operations and fundraising.
Perhaps the most important message of them all is that AI is for everyone – big and small nonprofits, all cause categories, and all roles—admins, fundraisers, marketers, executive directors, and COOs. Microsoft Vice Chair and President Brad Smith talked about the growth of the nonprofit sector in the U.S. and the world. There were only 15,000 U.S. nonprofits before World War II in the U.S. By the end of the century, the sector had grown to 1.5 million nonprofits– all because of passionate humans and a brand new tax code. He defined the 10 million global nonprofits as “the sparks of humanity” with 250 million people working to serve the world.
AI offers a new foundation for progress for this sector, as Kate Behncken, Global Head of Microsoft Philanthropies, shared. AI democratizes how much the sector can innovate and how much AI can be designed to represent our human needs and challenges. Dr. Fei-Fei Li said, “AI should be governed by human roots. At the end of the day there is nothing artificial about artificial intelligence, it is made by people and it going to be used by people and it has to be governed by people.”
Here are the biggest themes that came from the summit:
AI use is a question of purpose, risk, and rewards
All experts and nonprofit leaders who use AI agree that whether leveraged in program delivery, fundraising or marketing to donors, AI must be governed by ethical guardrails. The core principles of those guardrails come down to equity, justice, and prosperity. Nonprofit leaders are always inviting interdisciplinary dialogue and bringing together diverse perspectives, and AI is the same. Rebecca Finlay, CEO of Partnerships on AI, urged us to center humans needs and rights in the development of technology. She also talked about government policies that help to mitigate both bias and risk. When we set fair practices for large language models (LLM), we can answer the question on whether AI will augment or automate that piece of work. Natasha Crampton, Microsoft Chief Responsible AI Officer, shared how Microsoft thinks about human agency and building systems that are “by the people and for the people.” For nonprofits, the consideration of the economic and social context of AI should not be ignored. In fact, to think through the fear, uncertainty, and doubt, the Charities Aid Foundation shared hot off the press data from thousands of donors indicating donor readiness for and encouragement of charities using data in their fundraising and program efforts.
AI readiness is a data conversation. And data is a culture conversation.
Perhaps the most poignant and sobering moment around practical applications came down to a conversation about data. But data is really people. We use the word data – but we need to keep people centered in data decisions and, “We need to be respectful and careful and protect it appropriately.” Justin Spelhaug, Microsoft VP, Tech for Social Impact, led a session on data collectives to allow nonprofits to come together to solve big challenges. Only 10% of the attendees in the room were part of a data collective. Common data models are at the root of facilitating interoperability. Woodrow Rosenbaum, Chief Data Officer of Giving Tuesday, highlighted the Giving Tuesday Data Commons, a tool that works to understand the full spectrum of human generosity. The Commons is tracking interoperable data—varied assets that can still talk to each other to standardize and connect data better. In the long term, collaborating with developers will help to curate and extract the data that meets common challenges and delivers the right data set for the solutions. Open data sets and digital public goods are the substrate that lays the foundation for more bespoke AI solutions. National Forest Foundation’s Jess McCutcheon confirmed that data and AI projects are really culture projects, and she talked about the uphill battle to bring along staff to ensure they feel ownership in this AI change.
AI skills are in demand, so are human skills
Meg Garlinghouse and Karin Kimbrough from LinkedIn presented the gap between the in-demand skills and in-demand jobs. AI skills for board-level and C-suite officers are important. Meg provided an example of Board.dev that will train technologists to equip them with what they need to do if they serve on nonprofit boards. Meg encouraged nonprofits to think about their talent management and hire humans who understand the impact of AI. She shared consistent data stating that 70% of executives say soft skills are more important than AI skills. Talent is needed to make AI work in a very human world. At the summit, we saw that learning AI is better as a community sport. We held a Generative AI skills workshop to train nonprofit professionals while on site—and over 300 in-person attendees received their certifications. We also talked about the Digital Skills Hub where leaders can find tools to share with their teams in all roles.
Nonprofits are at the heart of AI innovation
And nonprofits should be at the heart of AI design. Vilas Dhar, President of the Patrick J. McGovern Foundation, in his closing keynote led with, “Those who are proximate to the problem, should be proximate to technology.” But his message took this one step further with a call to all nonprofits to become deeply involved in training and designing LLM technology for their use so it can serve local communities well. Jared Spataro’s demo of Microsoft Copilot showed how to query for information and design prompts that best meet the needs of the sector and provided practical examples to retrain your own prompts.
The summit’s core message ended with the hope and knowledge that the nonprofit sector is a leader in this tech revolution. As Woodrow said, “If you want to build good tech, build it to do good because then you are going to be taking on the hardest challenges and the tech you develop will be really robust.” The nonprofit industry should lead the most profound solutions because of our ability to work together.
The summit is just the beginning of using AI for impact. As Kate said, it may feel like a sprint, but AI for impact is a marathon. And we’re here to run it together. We want to hear from you—and learn from you—about how you will take the insights and learnings from these conversations back to your organization and start putting AI into action for mission impact. AI transformation starts here. We can’t wait to see what comes next.
Microsoft Tech Community – Latest Blogs –Read More
IPv6 Transition Technology Survey
The journey toward IPv6 only networking is challenging, and today there are several different approaches to the transition from IPv4 to IPv6 with multiple dual-stack or tunneling stages along the way. As we prioritize future Windows work, we would like to know more about what customers like you are using to support your own IPv6 deployments. We have published the survey below to ask you a few questions that will contribute to that exercise.
The survey is fairly short and anonymous (though we left a field for sharing your contact information if you would be ok with direct follow up). Thank you in advance for your responses; your experiences will help us focus on what you find most valuable in our future work.
Microsoft Tech Community – Latest Blogs –Read More
To BE or not to be – case sensitive using Power BI and ADX/RTA in Fabric
To BE or not to be – case sensitive
Power BI, Power Query and ADX/RTA in Fabric
Summary
You use these combination – Power BI including Power query with data coming from Kusto/ADX/RTA in Fabric.
Is your solution case sensitive? Is “PoKer” == “poker”?
Depends on who you ask,
Power Query says definitely no, Power BI says definitely yes and Kusto says that
“PoKer” == “poker” is false but “PoKer” =~ “poker” is true.
What about your data? Is the same piece of information always written in the same way or is it sometimes Canada and some other times Canada?
In this article I’ll highlight the challenges of using mixed case data and navigating the differences between the different technologies.
Power BI
Chris Webb in his blog writes:
Case sensitivity is one of the more confusing aspects of Power BI: while the Power Query engine is case sensitive, the main Power BI engine (that means datasets, relationships, DAX etc.) is case insensitive
In this post, Chris mentioned a way to do cases insensitive comparisons in PQ but it is not supported in Direct Query.
Kusto/ADX/RTA
Kusto is case sensitive. Every function and language term must be written in the right case which is usually all lower case.
The same with tables, functions and columns.
What about text comparisons?
The KQL language offers case sensitive and case insensitive comparisons:
== vs. =~, != vs. !~ , has_cs vs. has , in vs. in~, contains_cs vs. contains
Comparisons created in Power BI or in Power Query and folded to KQL
The connector uses by default case sensitive comparisons: has_cs and ==
You can change this behavior by using settings in the connection.
Mixed case data
This is the trickiest topic. I attach a PBI report that shows a list of colors in two pages.
The slicer on the first page is showing the color Blue twice. If you edit the query, you can see that there are some products that have the color as “blue” all lower case.
This is confusing PBI and it shows two different variations that look exactly the same.
If you filter on either version in the first page, you get the same value which is the value of the version “Blue”.
For the second page I created a copy of the query where the versions of Blue are well separated, and you can see the total for each one. you can see that the total shown on the first page is just for the version “Blue”
What can you do in such cases (pun intended)
I create a third version of the query when I converted all color names to be proper cased.
The M function for right case couldn’t be used in Direct Query so I added a KQL snippet using the M function Value.NativeQuery.
The snippet is
| extend ColorName = strcat(toupper(substring(ColorName,0,1)),substring(ColorName,1))
In the third page you can see that filtering “Blue” shows the total values for “Upper blue” and “Lower blue” as they appear in the second page.
So, if you have a column in mixed case you must convert all values to a standard case.
Microsoft Tech Community – Latest Blogs –Read More
GenAI Solutions: Elevating Production Apps Performance Through Latency Optimization
As the influence of GenAI-based applications continues to expand, the critical need to enhance their performance becomes ever more apparent. In the realm of production applications, responses are expected within a range of milliseconds to seconds. The integration of Large Language Models (LLMs) has the potential to extend response times of such applications to few more seconds. This blog intricately explores diverse strategies aimed at optimizing response times in applications that harness Large Language Models on the Azure platform. In broad context, the subsequent methodologies can be employed to optimize the responsiveness of Generative Artificial Intelligence (GenAI) applications:
Response Optimization of LLM models
Designing an Efficient Workflow orchestration
Improving Latency in Ancillary AI Services
Response Optimization of LLM models
The inherent complexity and size of Language Model (LLM) architectures contribute substantially to the latency observed in any application upon their integration. Therefore, prioritizing the optimization of LLM responsiveness becomes imperative. Let’s now explore various strategies aimed at enhancing the responsiveness of LLM applications, placing particular emphasis on the optimization of the Large Language Model itself.
Key factors influencing the latency of LLMs are
Prompt Size and Output token count
A token is a unit of text that the model processes. It can be as short as one character or as long as one word, depending on the model’s architecture. For example, in the sentence “ChatGPT is amazing,” there are five tokens: [“Chat”, “G”, “PT”, ” is”, ” amazing”]. Each word or sub-word is considered a token, and the model analyses and generates text based on these units. A helpful rule of thumb is that one token corresponds to ~4 characters of text for common English text. This translates to ¾ of a word (so 100 tokens ~= 75 words).
A deployment of the GPT-3.5-turbo instance on Azure comes with a rate limit of around 120,000 tokens per minute, equivalent to approximately 2,000 tokens per second ( Details of TPM limits of each Azure OpenAI model are given here . It is evident that the quantity of output tokens has a direct impact on the response of Large Language Models (LLMs), consequently influencing the application’s responsiveness. To Optimize application response times, it is recommended to minimize the number of output tokens generated. Set an appropriate value for the max_tokens parameter to limit the response length. This can help in controlling the length of the generated output.
The latency of LLMs is influenced not only by the output tokens but also by the input prompts. Input prompts can be categorized into two main types:
Instructions, which serve as guidelines for LLMs to follow, and
Information, providing a summary or context for the grounded data to be processed by LLMs.
While instructions are typically of standard lengths and crucial for prompt construction, but the inclusion of multiple tasks may lead to varied instructions, and ultimately increasing the overall prompt size. It is advisable to limit prompts to a maximum of one or two tasks to manage prompt size effectively. Additionally, the information or content can be condensed or summarized to optimize the overall prompt length.
Model size
The size of the LLMs is typically measured in terms of its parameters. A simple neural network with just one hidden layer has a parameter for each connection between nodes (neurons) across layers and for each node’s bias. The more layers and nodes a model have, the more parameters it will contain. A larger parameter size usually translates into a more complex model that can capture intricate patterns in the data.
Applications frequently utilize Large Language Models (LLMs) for various tasks such as classification, keyword extraction, reasoning, and summarization. It is crucial to choose the appropriate model for the specific task at hand. Smaller models like Davinci are well-suited for tasks like classification or key value extraction, offering enhanced accuracy and speed compared to larger models. On the other hand, large models are more suitable for complex use cases like summarization, reasoning and chat conversations. Selecting the right model tailored to the task optimizes both efficiency and performance.
Leverage Azure-hosted LLM Models
Azure AI Studio provides customers with cutting-edge language models like OpenAI’s GPT-4, GPT-3, Codex, DALL-E, and Whisper models, and other open-source models all backed by the security, scalability, and enterprise assurances of Microsoft Azure. The OpenAI models are co-developed by Azure OpenAI and OpenAI, ensuring seamless compatibility and a smooth transition between the different models.
By opting for Azure OpenAI, customers not only benefit from the security features inherent to Microsoft Azure but also run on the same models employed by OpenAI. This service offers additional advantages such as private networking, regional availability, scalability, and responsible AI content filtering, enhancing the overall experience and reliability of language AI applications.
If anyone is using GenAI models from creators, the transition to Azure-hosted version of these Models has yielded notable enhancements in the response time of the models. This shift to Azure infrastructure has led to improved efficiency and performance, resulting in more responsive and timely outputs from the models.
Rate Limiting, Batching, Parallelize API calls
Large language models are subject to rate limits, such as RPM (requests per minute) and TPM (tokens per minute), which depend on the chosen model and platform. It is important to recognize that rate limiting can introduce latency into the application. To accommodate high traffic requirements, it is recommended to select the maximum value for the max_token parameter to prevent any occurrence of a 429 error, which can lead to subsequent latency issues. Additionally, it is advisable to implement retry logic in your application to further enhance its resilience.
Effectively managing the balance between RPM and TPM allows for enhanced latency through strategies like batching or parallelizing API calls.
When you find yourself reaching the upper limit of RPM but remain comfortably within TPM bounds, consolidating multiple requests into a single batch can optimize your response times. This batching approach enables more efficient utilization of the model’s token capacity without violating rate limits.
Moreover, if your application involves multiple calls to the LLMs API, you can achieve a notable speed boost by adopting an asynchronous programming approach that allows requests to be made in parallel. This concurrent execution minimizes idle time, enhancing overall responsiveness and making the most of available resources.
If the parameters are already optimized and the application requires additional support for higher traffic and a more scalable approach, consider implementing a load balancing solution through Azure API Management layer.
Stream output and use stop sequence
Every LLM endpoint has a particular throughput capacity. As discussed, earlier GPT-3.5-turbo instance on Azure comes with a rate limit of 120,000 tokens per minute, equivalent to approximately 2 tokens per milliseconds. So, to get an output paragraph with 2000 tokens it takes 1 second and the time taken to get the output response increases as the number of tokens increase. The time taken for the output response (Latency) can be measured as the sum of time taken for the first token generation and the time taken per token from the first token onwards. That is
Latency = (Time to first token + (Time taken per token * Total tokens))
So, to improve latency we can stream the output as every token gets generated instead of waiting for the entire paragraph to finish. Both the completions and chat Azure OpenAI APIs support a stream parameter, which when set to true, streams the response back from the model via Server Sevent Events (SSE). We can use Azure Functions with FastAPI to stream the output of OpenAI models in Azure as shown in the blog here.
Designing an Efficient Workflow orchestration
Incorporating GenAI solutions into applications requires the utilization of specialized frameworks like LangChain or Semantic Kernel. These frameworks play a crucial role in orchestrating multiple Large Language Model (LLM) based tasks and grounding these models on custom datasets. However, it’s essential to address the latency introduced by these frameworks in the overall application response. To minimize the impact on application latency, a strategic approach is imperative. A highly effective strategy involves optimizing LLM usage through workflow consolidation, either by minimizing the frequency of calls to LLM APIs or simplifying the overall workflow steps. By streamlining the process, you not only enhance the overall efficiency but also ensure a smoother user experience.
For example, when the requirement is to identify the intention of the user query and based on its context get response by grounding on data from multiple sources. Most times such requirements are executed as a 3-step process –
the first step is to identify the intent using a LLM
and the next step is to get the prompt content from the knowledge base relevant to the intent
and then with the prompt content get the output derived from the LLMs.
One simple approach could be to leverage data engineering and building a consolidated knowledge base with data from all sources and using the input user text directly as the prompt to the grounded data in knowledge base to get the final LLM response in almost a single step.
Improving Latency in Ancillary AI Services
The supporting AI services like Vector DB, Azure AI Search, data pipelines, and others that complement a Language Model (LLM)-based application within the overall Retrieval-Augmented Generation (RAG) pattern are often referred to as “ancillary AI services.” These services play a crucial role in enhancing different aspects of the application, such as data ingestion, searching, and processing, to create a comprehensive and efficient AI ecosystem. For instance, in scenarios where data ingestion plays a substantial role, optimizing the ingestion process becomes paramount to minimize latency in the application.
Similarly lets look at the improvement of few other such services –
Azure AI search
Here are some tips for better performance in Azure AI Search:
Index size and schema: Queries run faster on smaller indexes. One best practice is to periodically revisit index composition, both schema and documents, to look for content reduction opportunities. Schema complexity can also adversely affect indexing and query performance. Excessive field attribution builds in limitations and processing requirements.
Query design: Query composition and complexity are one of the most important factors for performance, and query optimization can drastically improve performance.
Service capacity: A service is overburdened when queries take too long or when the service starts dropping requests. To avoid this, you can increase capacity by adding replicas or upgrading the service tier.
For more information on the optimizations of Azure AI Search index please refer here .
For optimizing third-party vector databases, consider exploring techniques such as vector indexing, Approximate Nearest Neighbor (ANN) search (instead of KNN), optimizing data distribution, implementing parallel processing, and incorporating load balancing strategies. These approaches enhance scalability and improve overall performance significantly.
Conclusion
In conclusion, these strategies contribute significantly to mitigating latency and enhancing response in large language models. However, given the inherent complexity of these models, the optimal response time can fluctuate between milliseconds and 3-4 seconds. It is crucial to recognize that comparing the response expectations of large language models to those of traditional applications, which typically operate in milliseconds, may not be entirely equitable.
Microsoft Tech Community – Latest Blogs –Read More

ADX Web updates – Jan 2024
Introducing Data Profile
We are extremely pleased to introduce the new Data Profile feature.
Whether you’re a seasoned KQL writer or new to the language, our Data Profile feature is designed with you in mind. For KQL experts, it provides quick access to schema details and column statistics, enhancing query writing efficiency.
If you’re new to the language, use this feature as a steppingstone, to quickly gain basic insights and build confidence on your journey to becoming a proficient query writer.
Data Profile features (1) dynamic time chart showcasing data distribution based on ingestion time (or your chosen datetime field), alongside a comprehensive display of each table (2) columns with key statistics. For each column, there is a (3) display of top values.
View query of a dashboard tile
We’ve been actively listening to your feedback, and today, we’re thrilled to introduce a new experience for viewing a dashboard tile’s underlying KQL query without disrupting your workflow.
This enhancement directly addresses long-standing requests:
Effortless query viewing
Now, you can view the query (read-only) right from the dashboard without the need to navigate away, preserving your valuable context.
Query tab management made easy
No more creating new query tabs each time you explore a tile’s query. Our update ensures a streamlined experience, optimizing your dashboard navigation.
Base query
A very common use case is to build and maintain dashboards where numerous tiles draw insights from the same tables and parameters. Traditionally, each tile’s query starts from scratch, redundantly repeating query snippets. Not only is this process time-consuming, but it also invites inconsistencies across tiles.
With Base Queries, you can create query snippets and define them as foundational elements within the context of a single dashboard – Base queries.
Such a base query can be used to power the dashboard’s parameters, tiles and other base queries.
To learn more about base queries, please go to the announcement here – Introducing Dashboards Base Queries: Enhancing Productivity and Consistency – Microsoft Community Hub
Or read the docs here – https://learn.microsoft.com/en-us/azure/data-explorer/base-query
Azure Data Explorer Web UI team is looking forward for your feedback in KustoWebExpFeedback@service.microsoft.com
You’re also welcome to add more ideas and vote for them here – https://aka.ms/adx.ideas
Read more:
ADX Web Aug updates – ADX Web UI updates – August 2023 – Microsoft Community Hub
Base queries announcement – Introducing Dashboards Base Queries: Enhancing Productivity and Consistency – Microsoft Community Hub
Microsoft Tech Community – Latest Blogs –Read More

AI Guide Dog: How Technology Boost Accessibility
Ejoe Tso, a Microsoft Azure MVP in Hong Kong, has played a pivotal role in the creation of a groundbreaking cloud-based on an AI Guide Dog prototype.
By skillfully utilizing AI and Azure technologies, this project stands out as an extraordinary instance of harnessing digital tools to provide safe navigation for people with visual impairments, showcasing the vast possibilities of cloud-based assistive solutions. Additionally, through his mentorship of students participating in the project, he is spearheading the exploration and creation of inclusive technologies that embrace the forefront of innovation.
Below, you’ll find technical details of the AI Guide Dog prototype and a demonstration video showing how it guides people with visual impairments:
– The prototype trains computer vision models to identify obstacles and offers real-time navigation guidance using Azure Machine Learning.
– Users are able to avoid collisions with the help of auditory feedback, which uses AI to adapt to user preferences and mimics the functions of a guide dog.
– Rapid testing and dataset training were made possible by Azure’s global scale and storage, allowing the prototype’s capabilities to be refined.
– Azure DevOps and similar tools allowed distributed teams to work together agilely on the solution’s development and delivery.
*Demo video: VTC 機械狗導盲犬 AI Guide Dog (TMIT Research Project) Part 1 – Demo (youtube.com)
This prototype was recently showcased at the IVE Tuen Mun Info Day conference in Hong Kong. According to Ejoe, the feedback received from individuals who experienced it firsthand will be invaluable in further refining and improving the prototype, aiming towards its practical application in the future.
Ejoe explains Microsoft Cloud and academic research. “Cloud computing power from Microsoft Azure is enabling cutting-edge academic research in addition to assistive technology. With Azure, you can speed up insights and discoveries by doing complex computations on huge datasets, which are useful for data analytics, HPC, and machine learning.”
He continues, “Thanks to Azure’s open and adaptable design, researchers all over the world can access the cloud resources they require, regardless of their physical location. Valuable intellectual property and sensitive data are also protected by its enterprise-grade security.”
As a community leader contributing to technology-driven support solutions, he shares his vision for the future. ”Both Azure for Research and the AI Guide Dog demonstrate Microsoft’s dedication to inclusive innovation that breaks down barriers and opens up new possibilities. Using the scalability of the cloud, Microsoft hopes to build tools that help every person and every community succeed.”
Technologies like AI and Azure cannot achieve something on their own. Technologies are tools to be utilized in creating a better society, as envisioned by users. Technology is essential for creating innovative solutions that address the diverse needs of people worldwide. Therefore, everyone should learn about technology and identify the specific support required by different groups.
All of you have the potential to generate outstanding solutions by understanding the needs of those around them, learning the necessary technologies, and applying them effectively. This story shows how Ejoe created an amazing accessible solution. We hope it motivates you to start your own accessibility projects.
Microsoft Tech Community – Latest Blogs –Read More
RECORDING TEST SCENARIOS IN JMETER
Hey there, performance testers! Tired of handcrafting your JMeter scripts? Well, buckle up, because JMeter has a sweet trick up its sleeve called script recording. Skip the manual coding and let JMeter capture your app clicks like a digital detective. It translates these clicks into a script filled with all the JMeter elements you need. Record your scenario in JMeter and upload it on Azure load Testing for analysing your application’s performance.
Ready to see how it works? Let’s dive in!
STEPS TO PERFORM JMETER RECORDING
For the purpose of our demonstration, we will be load testing our web application, an online shopping application called Contoso Traders. Let’s go.
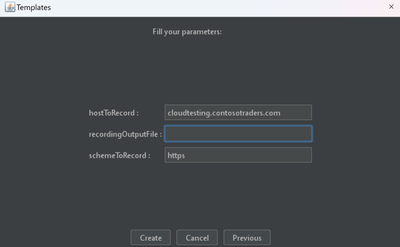
CREATE A JMETER TEMPLATE
Open the JMeter GUI in your local PC. Navigate to Templates and select the ‘Recording’ template. Enter the URL of your web application as shown below.
Go to HTTP(S) Test Script Record. Under Target Controller, select the target destination of the recorded samplers in your test script. In this demonstration, we would be choosing our destination as ‘Use Recording Controller’.
Under HTTP Sampler Settings, check ‘Follow Redirects’ if it’s not already checked. The “Follow Redirects” option checks if a server’s response is a redirection and redirects to the URL if it is. Give a Transaction Name of your choice.
In the tab ‘Requests Filtering’, you can exclude URL Patterns which you don’t want JMeter to record. In the demonstration, we wanted to exclude images of .svg extension. So under the ‘URL Patterns to Exclude’, we replaced
(?i).*.(bmp|css|js|gif|ico|jpe?g|png|swf|eot|otf|ttf|mp4|woff|woff2)
with
(?i).*.(bmp|css|js|gif|ico|jpe?g|png|swf|eot|otf|ttf|mp4|woff|woff2|svg)
INSTALL JMETER CA CERTIFICATE
Once you click on Start, a JMeter proxy server is started, which is used to intercept the browser requests. A file called ApacheJMeterTemporaryRootCA.crt will be generated in JMETER_HOME/bin folder. You need to install this certificate by following the steps mentioned here – Installing the JMeter CA certificate for HTTPS recording.
Since we are using Chrome browser for recording, we have installed the certificate by opening ApacheJMeterTemporaryRootCA.crt stored in JMETER_HOME/bin. Click on the “Details” tab and check that the certificate details agree with the ones displayed by the JMeter Test Script Recorder. If OK, go back to the “General” tab, and click on “Install Certificate …” and follow the Wizard prompts.
CONFIGURE YOUR BROWSER TO USE THE JMETER PROXY
If you are recording on Firefox, you can follow these steps.
For Chrome or Edge, you can follow these steps-
Go to Proxy Setting in your system settings.
Under Manual Proxy settings, click on ‘Set up’ button against ‘Use a proxy server’.
Toggle the ‘Use a proxy server’ button, with IP and port number as shown below. Click on Save.
RECORD YOUR NAVIGATION
Go to your HTTP(S) Test Script Recorder in your JMX Script. Click on Start.
Navigate to your browser (Chrome for this demo) and perform the user scenario that you intend to load test.
After you are done, go to ‘Recording Controller’ to view your JMX script.
Voila! Your test script is effortlessly generated from the sequence of user actions performed.
UPLOAD ON AZURE LOAD TESTING
You can run your script on our fully-managed service – Azure Load Testing. The service ensures that you can scale effortlessly, integrate testing in your CI/CD pipelines and consume your test results to improve your system performance. Just follow these steps to upload and run your script.
Happy testing!
Microsoft Tech Community – Latest Blogs –Read More

Create Tasks Repository in Microsoft Sentinel
One of the most important factors in running your security operations (SecOps) effectively and efficiently is the standardization of processes. SecOps analysts are expected to perform a list of steps, or tasks, in the process of triaging, investigating, or remediating an incident. Standardizing and formalizing the list of tasks can help keep your SOC running smoothly, ensuring the same requirements apply to all analysts. This way, regardless of who is on-shift, an incident will always get the same treatment and SLAs. Analysts don’t need to spend time thinking about what to do, or worry about missing a critical step. Those steps are defined by the SOC manager or senior analysts (tier 2/3) based on common security knowledge (such as NIST), their experience with past incidents, or recommendations provided by the security vendor that detected the incident.
In Microsoft Sentinel, you can utilize Tasks functionality for this purpose. Tasks can be added manually to the incident after the creation or using automation rules and/or playbooks automatically on incident creation.
We’re happy to announce that Microsoft Sentinel Tasks feature is now generally available (GA)!
But what if we have tasks for dozen incidents that are not the same? Or even few dozen? Creating and managing many automation rules for each incident or creating many conditions in playbooks can lead to complications and it would be really hard to manage.
In this blog, we will demonstrate how utilization of watchlists, automation rules, and playbooks can be used as tasks repository that will assign tasks based on incident title on incident creation. We should deploy Tasks Repository in this order:
Watchlist – Permission needed to deploy: Microsoft Sentinel Contributor
Playbook – Permission needed to deploy: Logic App Contributor; Permission needed to assign RBAC to managed identity: User Access Administrator or Owner on Resource Group where Microsoft Sentinel is
Automation rule – Permission needed to create: Microsoft Sentinel Responder
STEP 1
First step is to deploy the watchlist that will be used to store tasks. We can use sample watchlist and deploy it to our environment by clicking on Deploy to Azure.
Watchlist contains Incident title column that is also mapped to SearchKey, and additional 20 columns for tasks.
If there is a need for more then 20 tasks, please use CSV file to add additional columns, and create watchlist manually. Important note, when creating watchlist manually, use TasksRepository for alias, or this field will need to be updated in the playbook after deploying it. Also, map SearchKey to IncidentTitle column as playbook is using it as well.
IncidentTitle field doesn’t need to contain full incident title, as we are using contains to compare IncidentTitle field from watchlist with actual title when the incident is created. This is used so that you can utilize dynamic values feature when creating Analytic rules in Microsoft Sentinel.
Watchlist contain one row sample data, that can be deleted after adding tasks that will be used in production. Please note that if you delete sample value before adding any other rows in the watchlist, you will need to re-deploy the watchlist. Watchlist cannot be empty.
When adding additional tasks, there is a format that should be used so that playbook can map tasks title and description field. Each tasks filed should look like Tasks title, unique separator |^|, followed by Tasks description. Unique separator |^| is used in playbook to separate title and description of the tasks into its appropriate fields. In watchlist example, in column Task01 we can see example – Task 1|^|Task description.
Some additional recommendations around tasks:
Maximum number of tasks per incident is 100.
Task title length must not exceed 150 characters.
Task description length must not exceed 3000 characters.
You can use HTML elements like bold/italic/underlined, headings, hyperlinks, indenting.
When using hyperlinks, use target=’_blank’ to open in new tab as link cannot be opened in task itself – example
<a target=’_blank’ href=’https://www.microsoft.com/en-us/’>Microsoft Homepage</a>
STEP 2
Second step in the process is to deploy sample playbook that will extract task title and description based on the incident title and write it into the incident tasks.
After deploying the playbook, we will need to assign these permissions to Logic App managed identity:
Microsoft Sentinel Responder
Next, open Edit mode of the playbook, and add managed identity to Azure Monitor Logs action:
Select Create New to save our API connection, and then Save the playbook.
Also, important step is to make sure that For each loop in playbook has correct settings for parallelism so that tasks are added one by one, in order we define it in the watchlist.
In playbook, access Menu for action For each – task, and make sure that field Degree of Parallelism is set to 1.
STEP 3
Final step is to create an automation rule that will run on incident creation on all incidents, and as an action will run playbook. You can also add it to any existing automation rule you have that is being run on incident creation.
Title: Tasks repository
Trigger: When incident is created
Actions: Run playbook -> TasksRepository
After deploying watchlist, playbook, and automation rule, repository for tasks is ready. Add your tasks per incident to watchlist and make sure to update it regularly to remove any old information in the tasks! More information on how to manage watchlist can be found on Microsoft Sentinel docs.
Learn more about tasks:
Use tasks to manage incidents in Microsoft Sentinel | Microsoft Learn
Work with incident tasks in Microsoft Sentinel | Microsoft Learn
Audit and track changes to incident tasks in Microsoft Sentinel | Microsoft Learn
Tasks Workbook – Part of Sentinel SOAR Essentials solution
Please share feedback and what else you would like to see in Tasks Repository solution using Watchlists and Automation in Microsoft Sentinel!
Microsoft Tech Community – Latest Blogs –Read More
GenAI Solutions: Elevating Production Apps Performance Through Latency Optimization
As the influence of GenAI-based applications continues to expand, the critical need to enhance their performance becomes ever more apparent. In the realm of production applications, responses are expected within a range of milliseconds to seconds. The integration of Large Language Models (LLMs) has the potential to extend response times of such applications to few more seconds. This blog intricately explores diverse strategies aimed at optimizing response times in applications that harness Large Language Models on the Azure platform. In broad context, the subsequent methodologies can be employed to optimize the responsiveness of Generative Artificial Intelligence (GenAI) applications:
Response Optimization of LLM models
Designing an Efficient Workflow orchestration
Improving Latency in Ancillary AI Services
Response Optimization of LLM models
The inherent complexity and size of Language Model (LLM) architectures contribute substantially to the latency observed in any application upon their integration. Therefore, prioritizing the optimization of LLM responsiveness becomes imperative. Let’s now explore various strategies aimed at enhancing the responsiveness of LLM applications, placing particular emphasis on the optimization of the Large Language Model itself.
Key factors influencing the latency of LLMs are
Prompt Size and Output token count
A token is a unit of text that the model processes. It can be as short as one character or as long as one word, depending on the model’s architecture. For example, in the sentence “ChatGPT is amazing,” there are five tokens: [“Chat”, “G”, “PT”, ” is”, ” amazing”]. Each word or sub-word is considered a token, and the model analyses and generates text based on these units. A helpful rule of thumb is that one token corresponds to ~4 characters of text for common English text. This translates to ¾ of a word (so 100 tokens ~= 75 words).
A deployment of the GPT-3.5-turbo instance on Azure comes with a rate limit of around 120,000 tokens per minute, equivalent to approximately 2,000 tokens per second ( Details of TPM limits of each Azure OpenAI model are given here . It is evident that the quantity of output tokens has a direct impact on the response of Large Language Models (LLMs), consequently influencing the application’s responsiveness. To Optimize application response times, it is recommended to minimize the number of output tokens generated. Set an appropriate value for the max_tokens parameter to limit the response length. This can help in controlling the length of the generated output.
The latency of LLMs is influenced not only by the output tokens but also by the input prompts. Input prompts can be categorized into two main types:
Instructions, which serve as guidelines for LLMs to follow, and
Information, providing a summary or context for the grounded data to be processed by LLMs.
While instructions are typically of standard lengths and crucial for prompt construction, but the inclusion of multiple tasks may lead to varied instructions, and ultimately increasing the overall prompt size. It is advisable to limit prompts to a maximum of one or two tasks to manage prompt size effectively. Additionally, the information or content can be condensed or summarized to optimize the overall prompt length.
Model size
The size of the LLMs is typically measured in terms of its parameters. A simple neural network with just one hidden layer has a parameter for each connection between nodes (neurons) across layers and for each node’s bias. The more layers and nodes a model have, the more parameters it will contain. A larger parameter size usually translates into a more complex model that can capture intricate patterns in the data.
Applications frequently utilize Large Language Models (LLMs) for various tasks such as classification, keyword extraction, reasoning, and summarization. It is crucial to choose the appropriate model for the specific task at hand. Smaller models like Davinci are well-suited for tasks like classification or key value extraction, offering enhanced accuracy and speed compared to larger models. On the other hand, large models are more suitable for complex use cases like summarization, reasoning and chat conversations. Selecting the right model tailored to the task optimizes both efficiency and performance.
Leverage Azure-hosted LLM Models
Azure AI Studio provides customers with cutting-edge language models like OpenAI’s GPT-4, GPT-3, Codex, DALL-E, and Whisper models, and other open-source models all backed by the security, scalability, and enterprise assurances of Microsoft Azure. The OpenAI models are co-developed by Azure OpenAI and OpenAI, ensuring seamless compatibility and a smooth transition between the different models.
By opting for Azure OpenAI, customers not only benefit from the security features inherent to Microsoft Azure but also run on the same models employed by OpenAI. This service offers additional advantages such as private networking, regional availability, scalability, and responsible AI content filtering, enhancing the overall experience and reliability of language AI applications.
If anyone is using GenAI models from creators, the transition to Azure-hosted version of these Models has yielded notable enhancements in the response time of the models. This shift to Azure infrastructure has led to improved efficiency and performance, resulting in more responsive and timely outputs from the models.
Rate Limiting, Batching, Parallelize API calls
Large language models are subject to rate limits, such as RPM (requests per minute) and TPM (tokens per minute), which depend on the chosen model and platform. It is important to recognize that rate limiting can introduce latency into the application. To accommodate high traffic requirements, it is recommended to select the maximum value for the max_token parameter to prevent any occurrence of a 429 error, which can lead to subsequent latency issues. Additionally, it is advisable to implement retry logic in your application to further enhance its resilience.
Effectively managing the balance between RPM and TPM allows for enhanced latency through strategies like batching or parallelizing API calls.
When you find yourself reaching the upper limit of RPM but remain comfortably within TPM bounds, consolidating multiple requests into a single batch can optimize your response times. This batching approach enables more efficient utilization of the model’s token capacity without violating rate limits.
Moreover, if your application involves multiple calls to the LLMs API, you can achieve a notable speed boost by adopting an asynchronous programming approach that allows requests to be made in parallel. This concurrent execution minimizes idle time, enhancing overall responsiveness and making the most of available resources.
If the parameters are already optimized and the application requires additional support for higher traffic and a more scalable approach, consider implementing a load balancing solution through Azure API Management layer.
Stream output and use stop sequence
Every LLM endpoint has a particular throughput capacity. As discussed, earlier GPT-3.5-turbo instance on Azure comes with a rate limit of 120,000 tokens per minute, equivalent to approximately 2 tokens per milliseconds. So, to get an output paragraph with 2000 tokens it takes 1 second and the time taken to get the output response increases as the number of tokens increase. The time taken for the output response (Latency) can be measured as the sum of time taken for the first token generation and the time taken per token from the first token onwards. That is
Latency = (Time to first token + (Time taken per token * Total tokens))
So, to improve latency we can stream the output as every token gets generated instead of waiting for the entire paragraph to finish. Both the completions and chat Azure OpenAI APIs support a stream parameter, which when set to true, streams the response back from the model via Server Sevent Events (SSE). We can use Azure Functions with FastAPI to stream the output of OpenAI models in Azure as shown in the blog here.
Designing an Efficient Workflow orchestration
Incorporating GenAI solutions into applications requires the utilization of specialized frameworks like LangChain or Semantic Kernel. These frameworks play a crucial role in orchestrating multiple Large Language Model (LLM) based tasks and grounding these models on custom datasets. However, it’s essential to address the latency introduced by these frameworks in the overall application response. To minimize the impact on application latency, a strategic approach is imperative. A highly effective strategy involves optimizing LLM usage through workflow consolidation, either by minimizing the frequency of calls to LLM APIs or simplifying the overall workflow steps. By streamlining the process, you not only enhance the overall efficiency but also ensure a smoother user experience.
For example, when the requirement is to identify the intention of the user query and based on its context get response by grounding on data from multiple sources. Most times such requirements are executed as a 3-step process –
the first step is to identify the intent using a LLM
and the next step is to get the prompt content from the knowledge base relevant to the intent
and then with the prompt content get the output derived from the LLMs.
One simple approach could be to leverage data engineering and building a consolidated knowledge base with data from all sources and using the input user text directly as the prompt to the grounded data in knowledge base to get the final LLM response in almost a single step.
Improving Latency in Ancillary AI Services
The supporting AI services like Vector DB, Azure AI Search, data pipelines, and others that complement a Language Model (LLM)-based application within the overall Retrieval-Augmented Generation (RAG) pattern are often referred to as “ancillary AI services.” These services play a crucial role in enhancing different aspects of the application, such as data ingestion, searching, and processing, to create a comprehensive and efficient AI ecosystem. For instance, in scenarios where data ingestion plays a substantial role, optimizing the ingestion process becomes paramount to minimize latency in the application.
Similarly lets look at the improvement of few other such services –
Azure AI search
Here are some tips for better performance in Azure AI Search:
Index size and schema: Queries run faster on smaller indexes. One best practice is to periodically revisit index composition, both schema and documents, to look for content reduction opportunities. Schema complexity can also adversely affect indexing and query performance. Excessive field attribution builds in limitations and processing requirements.
Query design: Query composition and complexity are one of the most important factors for performance, and query optimization can drastically improve performance.
Service capacity: A service is overburdened when queries take too long or when the service starts dropping requests. To avoid this, you can increase capacity by adding replicas or upgrading the service tier.
For more information on the optimizations of Azure AI Search index please refer here .
For optimizing third-party vector databases, consider exploring techniques such as vector indexing, Approximate Nearest Neighbor (ANN) search (instead of KNN), optimizing data distribution, implementing parallel processing, and incorporating load balancing strategies. These approaches enhance scalability and improve overall performance significantly.
Conclusion
In conclusion, these strategies contribute significantly to mitigating latency and enhancing response in large language models. However, given the inherent complexity of these models, the optimal response time can fluctuate between milliseconds and 3-4 seconds. It is crucial to recognize that comparing the response expectations of large language models to those of traditional applications, which typically operate in milliseconds, may not be entirely equitable.
Microsoft Tech Community – Latest Blogs –Read More
GenAI Solutions: Elevating Production Apps Performance Through Latency Optimization
As the influence of GenAI-based applications continues to expand, the critical need to enhance their performance becomes ever more apparent. In the realm of production applications, responses are expected within a range of milliseconds to seconds. The integration of Large Language Models (LLMs) has the potential to extend response times of such applications to few more seconds. This blog intricately explores diverse strategies aimed at optimizing response times in applications that harness Large Language Models on the Azure platform. In broad context, the subsequent methodologies can be employed to optimize the responsiveness of Generative Artificial Intelligence (GenAI) applications:
Response Optimization of LLM models
Designing an Efficient Workflow orchestration
Improving Latency in Ancillary AI Services
Response Optimization of LLM models
The inherent complexity and size of Language Model (LLM) architectures contribute substantially to the latency observed in any application upon their integration. Therefore, prioritizing the optimization of LLM responsiveness becomes imperative. Let’s now explore various strategies aimed at enhancing the responsiveness of LLM applications, placing particular emphasis on the optimization of the Large Language Model itself.
Key factors influencing the latency of LLMs are
Prompt Size and Output token count
A token is a unit of text that the model processes. It can be as short as one character or as long as one word, depending on the model’s architecture. For example, in the sentence “ChatGPT is amazing,” there are five tokens: [“Chat”, “G”, “PT”, ” is”, ” amazing”]. Each word or sub-word is considered a token, and the model analyses and generates text based on these units. A helpful rule of thumb is that one token corresponds to ~4 characters of text for common English text. This translates to ¾ of a word (so 100 tokens ~= 75 words).
A deployment of the GPT-3.5-turbo instance on Azure comes with a rate limit of around 120,000 tokens per minute, equivalent to approximately 2,000 tokens per second ( Details of TPM limits of each Azure OpenAI model are given here . It is evident that the quantity of output tokens has a direct impact on the response of Large Language Models (LLMs), consequently influencing the application’s responsiveness. To Optimize application response times, it is recommended to minimize the number of output tokens generated. Set an appropriate value for the max_tokens parameter to limit the response length. This can help in controlling the length of the generated output.
The latency of LLMs is influenced not only by the output tokens but also by the input prompts. Input prompts can be categorized into two main types:
Instructions, which serve as guidelines for LLMs to follow, and
Information, providing a summary or context for the grounded data to be processed by LLMs.
While instructions are typically of standard lengths and crucial for prompt construction, but the inclusion of multiple tasks may lead to varied instructions, and ultimately increasing the overall prompt size. It is advisable to limit prompts to a maximum of one or two tasks to manage prompt size effectively. Additionally, the information or content can be condensed or summarized to optimize the overall prompt length.
Model size
The size of the LLMs is typically measured in terms of its parameters. A simple neural network with just one hidden layer has a parameter for each connection between nodes (neurons) across layers and for each node’s bias. The more layers and nodes a model have, the more parameters it will contain. A larger parameter size usually translates into a more complex model that can capture intricate patterns in the data.
Applications frequently utilize Large Language Models (LLMs) for various tasks such as classification, keyword extraction, reasoning, and summarization. It is crucial to choose the appropriate model for the specific task at hand. Smaller models like Davinci are well-suited for tasks like classification or key value extraction, offering enhanced accuracy and speed compared to larger models. On the other hand, large models are more suitable for complex use cases like summarization, reasoning and chat conversations. Selecting the right model tailored to the task optimizes both efficiency and performance.
Leverage Azure-hosted LLM Models
Azure AI Studio provides customers with cutting-edge language models like OpenAI’s GPT-4, GPT-3, Codex, DALL-E, and Whisper models, and other open-source models all backed by the security, scalability, and enterprise assurances of Microsoft Azure. The OpenAI models are co-developed by Azure OpenAI and OpenAI, ensuring seamless compatibility and a smooth transition between the different models.
By opting for Azure OpenAI, customers not only benefit from the security features inherent to Microsoft Azure but also run on the same models employed by OpenAI. This service offers additional advantages such as private networking, regional availability, scalability, and responsible AI content filtering, enhancing the overall experience and reliability of language AI applications.
If anyone is using GenAI models from creators, the transition to Azure-hosted version of these Models has yielded notable enhancements in the response time of the models. This shift to Azure infrastructure has led to improved efficiency and performance, resulting in more responsive and timely outputs from the models.
Rate Limiting, Batching, Parallelize API calls
Large language models are subject to rate limits, such as RPM (requests per minute) and TPM (tokens per minute), which depend on the chosen model and platform. It is important to recognize that rate limiting can introduce latency into the application. To accommodate high traffic requirements, it is recommended to select the maximum value for the max_token parameter to prevent any occurrence of a 429 error, which can lead to subsequent latency issues. Additionally, it is advisable to implement retry logic in your application to further enhance its resilience.
Effectively managing the balance between RPM and TPM allows for enhanced latency through strategies like batching or parallelizing API calls.
When you find yourself reaching the upper limit of RPM but remain comfortably within TPM bounds, consolidating multiple requests into a single batch can optimize your response times. This batching approach enables more efficient utilization of the model’s token capacity without violating rate limits.
Moreover, if your application involves multiple calls to the LLMs API, you can achieve a notable speed boost by adopting an asynchronous programming approach that allows requests to be made in parallel. This concurrent execution minimizes idle time, enhancing overall responsiveness and making the most of available resources.
If the parameters are already optimized and the application requires additional support for higher traffic and a more scalable approach, consider implementing a load balancing solution through Azure API Management layer.
Stream output and use stop sequence
Every LLM endpoint has a particular throughput capacity. As discussed, earlier GPT-3.5-turbo instance on Azure comes with a rate limit of 120,000 tokens per minute, equivalent to approximately 2 tokens per milliseconds. So, to get an output paragraph with 2000 tokens it takes 1 second and the time taken to get the output response increases as the number of tokens increase. The time taken for the output response (Latency) can be measured as the sum of time taken for the first token generation and the time taken per token from the first token onwards. That is
Latency = (Time to first token + (Time taken per token * Total tokens))
So, to improve latency we can stream the output as every token gets generated instead of waiting for the entire paragraph to finish. Both the completions and chat Azure OpenAI APIs support a stream parameter, which when set to true, streams the response back from the model via Server Sevent Events (SSE). We can use Azure Functions with FastAPI to stream the output of OpenAI models in Azure as shown in the blog here.
Designing an Efficient Workflow orchestration
Incorporating GenAI solutions into applications requires the utilization of specialized frameworks like LangChain or Semantic Kernel. These frameworks play a crucial role in orchestrating multiple Large Language Model (LLM) based tasks and grounding these models on custom datasets. However, it’s essential to address the latency introduced by these frameworks in the overall application response. To minimize the impact on application latency, a strategic approach is imperative. A highly effective strategy involves optimizing LLM usage through workflow consolidation, either by minimizing the frequency of calls to LLM APIs or simplifying the overall workflow steps. By streamlining the process, you not only enhance the overall efficiency but also ensure a smoother user experience.
For example, when the requirement is to identify the intention of the user query and based on its context get response by grounding on data from multiple sources. Most times such requirements are executed as a 3-step process –
the first step is to identify the intent using a LLM
and the next step is to get the prompt content from the knowledge base relevant to the intent
and then with the prompt content get the output derived from the LLMs.
One simple approach could be to leverage data engineering and building a consolidated knowledge base with data from all sources and using the input user text directly as the prompt to the grounded data in knowledge base to get the final LLM response in almost a single step.
Improving Latency in Ancillary AI Services
The supporting AI services like Vector DB, Azure AI Search, data pipelines, and others that complement a Language Model (LLM)-based application within the overall Retrieval-Augmented Generation (RAG) pattern are often referred to as “ancillary AI services.” These services play a crucial role in enhancing different aspects of the application, such as data ingestion, searching, and processing, to create a comprehensive and efficient AI ecosystem. For instance, in scenarios where data ingestion plays a substantial role, optimizing the ingestion process becomes paramount to minimize latency in the application.
Similarly lets look at the improvement of few other such services –
Azure AI search
Here are some tips for better performance in Azure AI Search:
Index size and schema: Queries run faster on smaller indexes. One best practice is to periodically revisit index composition, both schema and documents, to look for content reduction opportunities. Schema complexity can also adversely affect indexing and query performance. Excessive field attribution builds in limitations and processing requirements.
Query design: Query composition and complexity are one of the most important factors for performance, and query optimization can drastically improve performance.
Service capacity: A service is overburdened when queries take too long or when the service starts dropping requests. To avoid this, you can increase capacity by adding replicas or upgrading the service tier.
For more information on the optimizations of Azure AI Search index please refer here .
For optimizing third-party vector databases, consider exploring techniques such as vector indexing, Approximate Nearest Neighbor (ANN) search (instead of KNN), optimizing data distribution, implementing parallel processing, and incorporating load balancing strategies. These approaches enhance scalability and improve overall performance significantly.
Conclusion
In conclusion, these strategies contribute significantly to mitigating latency and enhancing response in large language models. However, given the inherent complexity of these models, the optimal response time can fluctuate between milliseconds and 3-4 seconds. It is crucial to recognize that comparing the response expectations of large language models to those of traditional applications, which typically operate in milliseconds, may not be entirely equitable.
Microsoft Tech Community – Latest Blogs –Read More







