

Category: Microsoft
Category Archives: Microsoft
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
The Publisher failed to allocate a new set of identity ranges for the subscription
Problem:
===========
Assume that you have tables with Identity columns declared as datatype INT and you are using Auto Identity management for those articles in a Merge Publication.
This Publication has one or more subscribers and you tried to re-initialize one subscriber using a new Snapshot.
Merge agent fails with this error:
>>
Source: Merge Replication Provider
Number: -2147199417
Message: The Publisher failed to allocate a new set of identity ranges for the subscription. This can occur when a Publisher or a republishing Subscriber has run out of identity ranges to allocate to its own Subscribers or when an identity column data type does not support an additional identity range allocation. If a republishing Subscriber has run out of identity ranges, synchronize the republishing Subscriber to obtain more identity ranges before restarting the synchronization. If a Publisher runs out of identit
Cause:
============
Identity range Merge agent is trying to allocate, exceeds maximum value an INT datatype can have.
Resolution
=================
Assume that publisher database has only one Merge publication with 2 subscribers, and your merge articles have this definition:
>>>
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity’, @source_owner = N’dbo’, @source_object = N’tblCity’, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
exec sp_addmergearticle @publication = N’MergeRepl_ReproDB’, @article = N’tblCity1′, @source_owner = N’dbo’, @source_object = N’tblCity1′, @type = N’table’, @description = N”, @creation_script = N”, @pre_creation_cmd = N’drop’, @schema_option = 0x000000004C034FD1, @identityrangemanagementoption = N’auto’, @pub_identity_range = 1000, @identity_range = 1000, @threshold = 90, @destination_owner = N’dbo’, @force_reinit_subscription = 1, @column_tracking = N’false’, @subset_filterclause = N”, @vertical_partition = N’false’, @verify_resolver_signature = 1, @allow_interactive_resolver = N’false’, @fast_multicol_updateproc = N’true’, @check_permissions = 0, @subscriber_upload_options = 0, @delete_tracking = N’true’, @compensate_for_errors = N’false’, @stream_blob_columns = N’false’, @partition_options = 0
You can run this query against the Published database to see what articles range is full or have very few values left:
>>>
select a.name,
max_used=max_used,
diff_pub_range_end_max_used=range_end – max_used, –this tells how many values are left
pub_range_begin=range_begin,
pub_range_end=range_end
from dbo.MSmerge_identity_range b ,
sysmergearticles a
where
a.artid = b.artid
and is_pub_range=1
order by max_used desc
name max_used diff_pub_range_end_max_used pub_range_begin pub_range_end
————– ————————————— ————————————— ————————————— ————-
tblCity 2147483647 0 2147477647 2147483647
tblCity1 6001 2147477646 1 2147483647
As you see from above diff_pub_range_end_max_used column is zero for tblCity.
When Merge agent runs depending on how many servers are involved it has to allocate 2 ranges for each.
In the example above we have Publisher and 2 subscribers and @identity_range is 1000. So, we will have to allocate range for 3 servers i.e., 3 * (2*1000) = 6000
Our diff_pub_range_end_max_used should be greater than 6000, only then we will be able to allocate a new range for all the servers.
To resolve the issue.
Remove tblCity table from publication.
Change the datatype from int to bigint and add this table back to publication.
Then generate a new snapshot. It will generate snapshots for all articles, but only this 1 table will be added back to the existing Subscribers.
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
How to estimate pricing for WordPress on App Service
Estimating pricing is a crucial step for your business. It helps you plan your budget, forecast your expenses, compare different options, and optimize your cloud usage.
However, estimating pricing for WordPress on App Service can be challenging.
WordPress on App Service is not a standalone Azure product. It is a combination of multiple Azure resources that provide you with the best WordPress experience. These resources include:
– App Service (Linux): A fully managed web hosting platform that runs your WordPress web app.
– DB for MySQL flexible server: A fully managed database service that stores your WordPress data.
– CDN or Front Door: A content delivery network or a global load balancer that improves the speed and reliability of your WordPress site.
– Blob Storage: A scalable storage service that stores your WordPress media and static files.
– ACS Email: A communication service that handles your WordPress email notifications.
– Other integrations: You can also integrate your WordPress site with other Azure services, such as Azure cache for Redis, Azure Monitor, Azure Key Vault, Azure Active Directory, and more.
In this article, we will show you how to estimate the monthly cost for a WordPress site on App Service (Standard hosting plan) with the following configuration:
Azure Product
Link for pricing
SKU or Usage
App Service (Linux)
P1V2 – Pay as you go.
DB for MySQL flexible server
Pricing | MySQL flexible server
B2S – Pay as you go.
CDN
Microsoft – 5GB across all regions.
Front Door
No usage since we are using CDN.
Blob Storage
Standard performance – 5GB capacity.
ACS Email
Pricing | Communication Services
5000 emails. 0.2 MB per email.
Please note that App Service and MySQL charges depend on the region as well. We will take ‘East US’ as the region for this article.
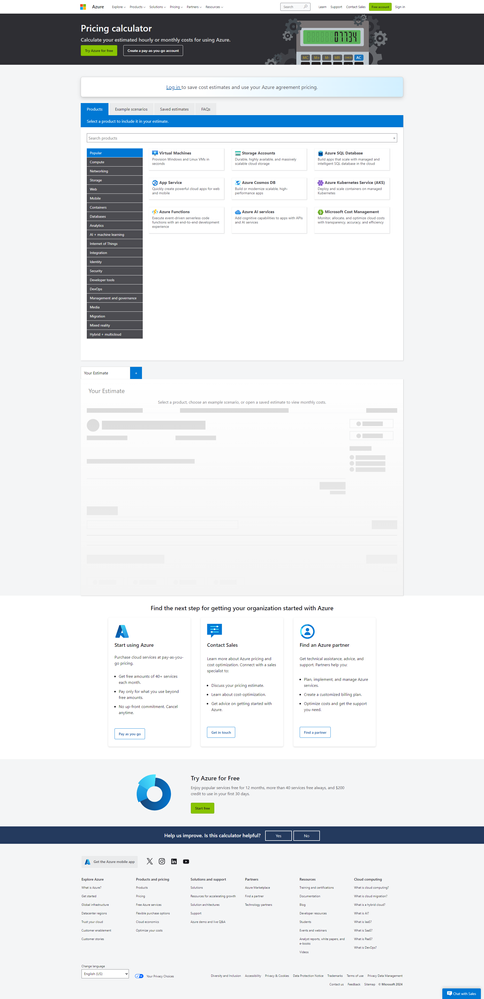
Step 1: Go to Azure Pricing Calculator. Pricing Calculator | Microsoft Azure
Step 2: Go to Web > App Service. This will add App Service to the list of resources. Select region as ‘East US’, Operating System as ‘Linux’, Tier as ‘Premium V2’ and instance as ‘P1V2’.
Step 3: Go to Databases > Azure Database for MySQL. This will add MySQL to the list of resources. Select region as ‘East US’, Deployment option as ‘Flexible Server’, Tier as ‘Burstable’, Compute as ‘B2S’.
Now you can see the total price for App Service and MySQL Database combined.
Step 4: Repeat this for Azure CDN, Blob Storage, and ACS Email.
Now you can see the entire price for the selected resources. You can export, save, and share this estimate. To check this estimate in Azure Pricing calculator, use this link: https://azure.com/e/acffd03d19ba44259e05b97098442de4
To learn more about the pricing calculator, refer to Estimate costs with the Azure pricing calculator – Microsoft Cost Management | Microsoft Learn
To learn more about cost optimization, refer to Optimize your Azure costs to help meet your financial objectives | Microsoft Azure Blog
Support and Feedback
In case you need any support, you can open a support request at New support request – Microsoft Azure.
If you have any ideas about how we can make WordPress on Azure App Service better, please post your ideas at Post idea · Community (azure.com)
or you could email us at wordpressonazure@microsoft.com to start a conversation.
Microsoft Tech Community – Latest Blogs –Read More
Business Continuity with ABCC: Part 4: optimize security configuration
Credits: This blog post has been reviewed by Utsav Raghuvanshi.
Hello everyone! This is Daya Patil here, continuing our series on business continuity with ABCC. In our previous session, we explored the concept of understanding the inventory of protected items in ABCC through Business Continuity with ABCC: Part 3: understand your protected items inventory – Microsoft Community Hub. Today, we’re going deeper into exploring the security optimization of protected items within ABCC.
Tailwind Traders case study
The escalating ransomware threats are a pressing issue for Tailwind Traders. They are persistently concerned about being adequately prepared and leveraging all essential security features to guarantee data recovery. In this section, we’ll delve into how John, Tailwind’s BCDR admin, can fulfill his upcoming objectives:
Review security configurations for protected items
Investigate best practices
Enhance security setups for protected items.
View security level for protected items
John understands the security capabilities provided by Azure Backup at the vault level, ensuring the protection of stored backup data. These measures encompass the settings linked to the Azure Backup solution for the vault and extend to the protected data sources within it. However, he has often pondered: is it necessary to configure all these settings? Which settings are indispensable for critical resources? Among them, which one can effectively meet their organization’s security requirements?
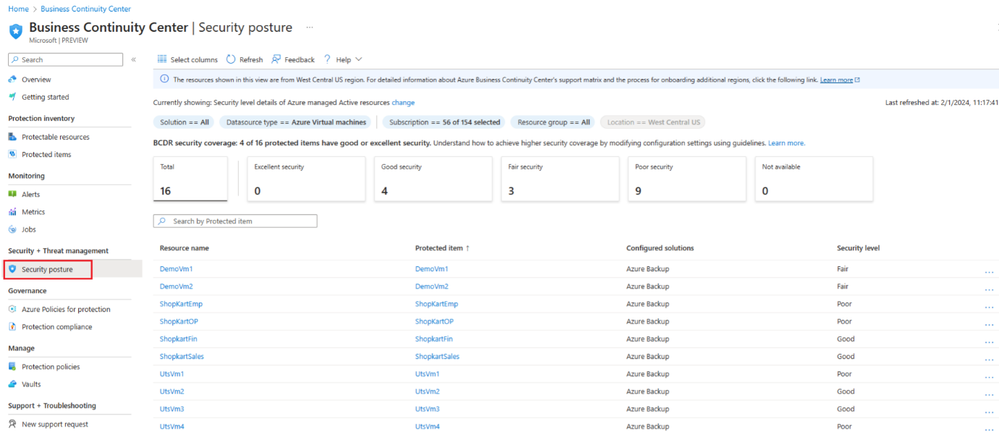
Caught in that uncertainty, John navigates towards the Security Posture view within ABCC. Alternatively, he can access this view by simply clicking on the “BCDR security coverage” tile situated on the ABCC overview page.
In the Security Posture blade, John notices a column called ‘security level’ which depicts a high-level summary of how well each item is protected using different security capabilities. He also notices that some of his items are identified as having ‘good’ or ‘excellent’ security levels. He wants to understand how these security levels are determined.
To find out more about security levels, he clicks the “learn more” link, which throw light on the significance of these security levels and how adjusting different security settings can enable him to attain varying levels of security. He also notes that security properties of a vault, and hence security levels, apply to all items protected in the vault.
Security levels for vaults used for Azure Backup and the protected data sources are categorized as follows:
Maximum (Excellent): This level represents the utmost security, ensuring comprehensive protection. It is achieved when all backup data is safeguarded from accidental deletions and defends against ransomware attacks. To achieve this high level of security, the following conditions must be met:
Immutability or soft-delete vault setting must be enabled and irreversible (locked/always-on).
Multi-user authorization (MUA) must be enabled on the vault.
Adequate (Good): Signifies a robust security level, ensuring dependable data protection. It shields existing backups from unintended removal and enhances the potential for data recovery. To attain this level of security, one must enable either immutability with a lock or soft-delete.
Minimum (Fair): Represents a basic level of security, appropriate for standard protection requirements. Essential backup operations benefit from an extra layer of safeguarding. To attain minimal security, Multi-user Authorization (MUA) must be enabled on the vault.
None (Poor): Indicates a deficiency in security measures, rendering it less suitable for data protection. Neither advanced protective features nor solely reversible capabilities are in place. The None level security only offers protection primarily against accidental deletions.
Not available: For resources safeguarded by solutions other than Azure Backup, the security level is labelled as Not available.
John can also see security level for each vault from ‘Vaults’ view in ABCC:
What a relief! Having received answers to all his inquiries, John is now completely clear. Moreover, within the view, he notices the count of resources categorized under each security detail using the Summary cards. These cards dynamically update based on applied filters at the top of the view, allowing further filtering and exploration of protected items with specific security levels simply by clicking on them.
Note: Currently security levels are applicable only for items protected by Azure Backup.
Customize the view
John notices similar options on the page to customize view like:
Filters: John utilizes filters to tailor the displayed information to your specific requirements. Available filters include – solution, datasource type, subscription, resource group, location etc.
Scope: John also notices the new scope feature in ABCC that enhances visibility into protection landscape across various platforms such as Azure and Hybrid environments. Clicking on “Currently showing: Security level details of Azure managed Active resources change” he discovers a range of available options, including:
Resource status: Active, deprovisioned resources
Search: John could also search by specific item name to get information specific to it.
Select columns: Use Select columns from the menu available at the top of the views to add or remove columns.
Modify security level
John realizes that some protected items require a higher security level than their current settings. To address this, on the Security posture view under Security + Threat management, John clicks on the ‘Protected item’. John can select the more icon … > View details action menu to navigate and view further details for an item.
Within the item details page, John can easily observe the security level. Clicking on it provides him with insights into the security settings employed to achieve that level, along with their current values.
John also pinpoints the vault used for protecting the item. Clicking on the vault’s name redirects him to the properties page of the vault.
On the vault properties page, John makes adjustments to the security settings following the previous guidance. Upon returning to ABCC, he observes that the security levels are now appropriately displayed for those items.
Note: When you modify the security setting for a vault, it gets applied to all the protected datasources by Azure Backup in that vault.
Learn about the view
Similar to other views, John notices the presence of built-in assistance within ABCC under the “Help” menu. Clicking on it reveals two valuable sections:
Business Continuity Center: Presents a succinct overview of ABCC, outlining its different views and their respective objectives.
The current view: Offers in-depth details about the current view, including information on filters, tiles, scope, columns, values, and more.
Having accomplished his goal of optimizing the security configurations, John utilizes the security posture views in ABCC. In the upcoming article, we’ll explore John’s journey of monitoring protection using ABCC.
Stay tuned………………
Microsoft Tech Community – Latest Blogs –Read More
With the geo-replica, Web PubSub resources are fault tolerant and can communicate across regions
TL; DR
Azure Web Pub announces the GA status of the geo-replia feature. Having a failover strategy in place is a must for enterprise-grade applications. What used to take much effort and time can now be configured quicky with a few clicks. Plus, end users from geographically distant locations can benefit from low latency they expect from a real-time system.
Set up multi-instance for disaster recovery
Step-by-step guide to quickly configure geo-replia
Context
While it is perfectly normal for companies to have one Azure Web PubSub resource serving all its real-time message delivery, for enterprise-grade applications replying on just one resource does not cut it for two important reasons.
The single resource could experience downtime which disrupts the availability of the application.
For most applications using Web PubSub, it can be disastrous. As a stateful communication channel, Web PubSub usually powers critical data exchanges between the server and the web clients. Although Web PubSub already has outstanding uptime guarantee (99.9 for standard tier and 99.95 for the premium tier), architects are not comfortable with the fact that there’s a glaring single point of failure for an important real-time communication channel.
Latency issue of a globally distributed user base
These days it is not uncommon for applications to have a user base across the globe. Having only one Web PubSub resource makes the latency for some users significantly longer than others. When you create a Web PubSub resource, each resource is bound to an Azure region. For our explanation, let’s say the resource is created in East US. End users in the east coast of the US will relish in the speed of connecting with your application, but not the users in the UK or Australia. The round-trip time for a message for users outside the US will suffer due to the greater physical distance between continents.
Typical approach: multi-resource setup
Developers using Web PubSub have long recognized the need for a more resilient and low-latency solution for all users. The preferred approach has been creating a Web PubSub resource in a few carefully selected Azure regions and using Azure Traffic Manager to route clients to the geographically nearest resource. Following our example above, they would set up a resource in the US, one in the UK and one in Australia. Developers would need to have a way to notify Azure Traffic Manager when say the Web PubSub resource in the US becomes unavailable so that Azure Traffic Manager does not route clients to that region. The outcome is that latency for the users in the US increases while the affected resource recovers, but the application is up and running.
If all that’s needed is to proactively push a message from server to web clients or in other words to broadcast message, the application server simply invokes an API on each Web PubSub resource. However, the business requirements developers need to work with are seldom this simple. Often the communication is not just from server-to-web clients, but also from web-clients to server, in other words it’s bi-directional. When a client sends a message to your application and your application needs to send to a subset of users, the crude and simple way is to send an API on all Web PubSub resources. It is, however, without problems. You can refer to this documentation to learn more about the considerations when setting up multi-instance failover strategy.
With the new geo-replica feature, what used to be weeks if not months of development work can be saved, giving the development team more time to focus on unique business requirements rather than worrying about the infrastructure.
Fully managed geo-replication
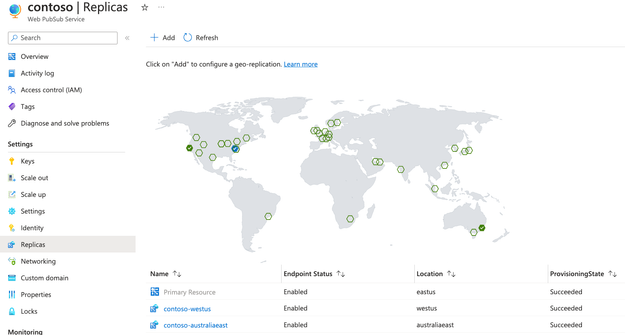
Geo-replication is generally available and setting up replicas is as easy as a few clicks on Azure Portal.
DNS-based routing
After enabling geo-replications, a DNS router (Azure Traffic Manager) is put in front of your Web PubSub resource. Both your clients and server will be routed to the closest Web PubSub replicas. Health checks are done periodically by the traffic manager. An automatic DNS failover will happen within 3 minutes if a replica becomes unavailable. So, the most disruption to your application is limited to a maximum of 3 minutes.
Cross-region communication between replicas
Sending messages to clients in the same region will be extremely fast (usually < 10ms). When sending messages to a group of clients that are connected to different replicas, messages between replicas go through the Azure network backbone which has improved speed and reliability.
Enable geo-replication without any code change
You can enable geo-replication either through Azure Portal or through Bicep template. Refer to this article for a step-by-step guide.
Resources and references
Set up multi-instance for disaster recovery
Step-by-step guide to quickly configure geo-replia
Feedback
If you have any feedback regarding the article or the features mentioned, please reach out to awps@microsoft.com
Microsoft Tech Community – Latest Blogs –Read More

Python & Azure Cosmos DB Integration: Create an E-Commerce DB Management Tool
Creating an effective Python command-line tool to manage an e-commerce product catalog with Azure Cosmos DB can streamline operations significantly. This tutorial will guide you through creating a Python command-line tool that interfaces with Azure Cosmos DB to manage an e-commerce product catalog. The tool simplifies CRUD operations, making it accessible for non-technical staff to maintain up-to-date product listings.
Prerequisites
– Python 3.x installed
– Azure account and Azure Cosmos DB setup
– Basic knowledge of Python and command-line operations
– Git and GitHub account for version control
Step 1: Setting Up Azure Cosmos DB
Log in to Azure Portal: Access your Azure account and navigate to the Azure portal.
Create a New Cosmos DB Account:
– Click on “Create a resource”.
– Search for and select “Azure Cosmos DB”.
– Select an API, such as Core (SQL) for document storage.
– Click “Create” and fill in the details like subscription, resource group, and account name.
– Review and create your Cosmos DB account.
Acquire Connection Strings:
– Once the account is set up, go to the “Keys” section under “Settings”.
– Copy the Primary Connection String, which will be used in your tool to access the database.
Step 2: Preparing the Database and Container
1. Create a Database:
– Inside your Cosmos DB account, click on “Data Explorer”.
– Click on the “New Container” button.
– You will be prompted to create a new database. Enter a unique name for your database. (Include the relevant image here)
Create a Container:
– After specifying the database name, you will be prompted to create a container.
– Enter a unique name for your container.
– Choose a partition key. For simplicity, you can use `/id` as the partition key for this guide.
Step 3: Designing the Command-Line Tool
Initialize Your Project:
– Create a new directory for your project on your local machine.
– Initialize a Git repository and connect it to a new GitHub repository.
Write Your Python Script:
– Create a `main.py` script where you’ll write functions to interact with Cosmos DB using the `azure-cosmos` Python package.
– Define functions like `add_product`, `update_product`, `get_product`, and `delete_product`.
Step 4: Implementing CRUD Operations
Create Product:
– Implement a function that takes product details in JSON format and adds them to the Cosmos DB.
Read Product:
– Create a function to retrieve product details by their unique ID.
Update Product:
– Write code to modify existing product details, such as price or stock levels.
Delete Product:
– Allow for the removal of product listings from the database.
Step 5: Interfacing with Cosmos DB
– Use the `azure-cosmos` Python package to establish a connection to your Cosmos DB instance using the connection string.
– Implement your CRUD operations using the Cosmos DB SDK methods like `upsert_item` for adding or updating and `delete_item` for removing entries.
Step 6: Packaging and Distribution
Create a `requirements.txt` File:
– List all the dependencies your tool requires, including `azure-cosmos`.
Setup.py:
– Write a `setup.py` file for packaging your tool. Include metadata like name, version, and entry points for your command-line interface.
Step 7: Testing Your Tool
– Test each function individually to ensure it interacts with Cosmos DB correctly.
– Perform end-to-end tests simulating real-world scenarios, like adding a new product catalog or updating stock levels.
Step 8: Deploying Your Tool
– Push your final code to your GitHub repository.
– Use `pip` to install your command-line tool on the machines of end-users.
– Provide documentation on how to use the tool, including example commands and expected outputs.
Step 9: Verifying Deployment in Azure
– Navigate to your resource group in the Azure portal.
– Click on the “Deployments” section.
– Look for the deployment named ‘Microsoft.Azure.CosmosDB’ followed by a timestamp.
– Confirm that the status is “Succeeded” which indicates your Cosmos DB setup was successful.
Conclusion
By following this guide, you can create a Python command-line tool that enables efficient management of an e-commerce product catalog using Azure Cosmos DB. This tool will allow your product management team to perform database operations with ease, improving productivity and ensuring data accuracy. Start building your Python command-line tool today to take advantage of the powerful features offered by Azure Cosmos DB, and revolutionize the way your e-commerce platform handles product management.
Microsoft Tech Community – Latest Blogs –Read More

Active geo-replication with ledger automatic digest management
Active geo-replication is a feature in Azure SQL Database and Azure SQL Managed Instance that lets you create a continuously synchronized readable secondary database for a primary database. Geo-replication is configured per database, and only supports manual failover. The failover groups feature allows you to manage the replication and failover of some or all databases on a logical server to a logical server in another region.
Combining active geo-replication and ledger automatic digest management requires some specific considerations. Database digests can be generated either automatically by the system or manually by the user. You can use them later to verify the integrity of the database. In this blog post, I will explain how it works and potential issues to look out for.
How it works
Replication across geographic regions is asynchronous for performance reasons and, therefore, the secondary database is slightly behind the primary. Ledger will only issue database digests for data that is replicated to geographic secondaries to guarantee that digests will never reference data that might be lost in case of a geographic failover. This only applies for automatic generation and storage of database digests.
Setup
In this example I have created 2 logical SQL Servers.
Ledgerdemoserver in North Europe region – primary
Ledgerdemoserverdr in East US region – secondary
On the primary server I have created a database, ContosoHR, with automatic digest configuration to a storage account.
Create failover group and perform a failover
In this step I’m going to create a failover group between the 2 servers for the ContosoHR database. As you can see in the picture below, my ledgerdemoserver is my primary server and ledgerdemoserverdr is my secondary server.
In a failover group, both primary and secondary databases will have the same digest path. Even when you perform a failover, the digest path doesn’t change for both primary and secondary database. Primary and secondary are both writing to the same digest path.
Make sure that the secondary replica has sufficient RBAC permissions to write digests by adding it to the Storage Blob Data Contributor role. This permission is automatically set when you configure the storage path on the primary but needs to be done manually for the secondary replica.
When I perform a failover, meaning that ledgerdemoserverdr becomes my new primary, notice that digests are written under the original primary server name. There is no new folder for the secondary server created on the storage account. This is important otherwise we would have 2 locations to store the digests.
To verify this, execute the query below on the new primary replica, in my case ledgerdemoserverdr.
DECLARE @digest_locations NVARCHAR(MAX) = (SELECT * FROM sys.database_ledger_digest_locations FOR JSON AUTO, INCLUDE_NULL_VALUES);
SELECT @digest_locations as digest_locations;
The result set should show the path to the primary server even though you are connected to the secondary replica.
[{“path”:”https://ledgerdemdrstg.blob.core.windows.net/sqldbledgerdigests/ledgerdemoserver/ContosoHR/2024-01-10T14:27:14.7830000″,”last_digest_block_id”:2,”is_current”:true}]
Remove failover group or drop link
Now that we know the ledger digest management behavior when your database is part of a failover group or geo-replication, let’s have a look at what happens when we drop the link between the databases or remove the failover group.
Let’s switch back to the original situation where my ledgerdemoserver is the primary replica and my ledgerdemoserverdr is the secondary replica. Once the failback is done, I will remove the ContosoHR database from the failover group.
Removing a database from a failover group doesn’t stop replication, and it doesn’t delete the replicated database. You’ll need to manually stop geo-replication. This is one of the limitations of a failover group. At this point, nothing changed for the ledger digest management for both primary and secondary replica.
To stop the geo-replication, in the Azure portal, go to the database, click on Replicas in the left ribbon, select the 3 dots of the secondary replica and click Stop Replication.
Both databases will now behave as primary databases. At that point the digest path of the previous secondary database will change. A new folder with the name of the secondary replica is created and we will add a folder RemovedSecondaryReplica to the path (see picture below).
Running the same query to fetch the digest location will now return 2 digest locations, which is expected.
DECLARE @digest_locations NVARCHAR(MAX) = (SELECT * FROM sys.database_ledger_digest_locations FOR JSON AUTO, INCLUDE_NULL_VALUES);
SELECT @digest_locations as digest_locations;
[{“path”:”https://ledgerdemdrstg.blob.core.windows.net/sqldbledgerdigests/ledgerdemoserver/ContosoHR/2024-01-10T14:27:14.7830000″,”last_digest_block_id”:2,”is_current”:false},{“path”:”https://ledgerdemdrstg.blob.core.windows.net/sqldbledgerdigests/ledgerdemoserverdr/ContosoHR/RemovedSecondaryReplica/2024-01-11T09:34:58.0000000″,”last_digest_block_id”:3,”is_current”:true}]
Tip: Always verify the digest locations before running the ledger verification process.
Conclusion
The digest path for both primary and secondary databases will point to the same location. Make sure that your secondary replica has the correct permissions on the storage account by adding it to the Storage Blob Data Contributor role. If the failover group is deleted or you drop the link, both databases will behave as primary databases. At that point the digest path of the previous secondary database will change, and we will add a folder RemovedSecondaryReplica to the path. As you can see ledger digest management in combination with geo-replication or failover groups requires a bit more attention but not too hard to handle.
Learn More
Active geo-replication and Always On availability groups
Microsoft Tech Community – Latest Blogs –Read More

Your Video Insights, Promptly Extracted: Azure AI Video Indexer’s Preview of Prompt-Ready API
Have you ever watched an online course and wished you could ask questions on the entire course, or have a comprehensive summary of a video? This can all now be achieved with Azure AI Video Indexer and LLMs (Large Language Model) – powering each other.
LLMs are powerful language models that can capture the essence of text, allow natural language question-answering and much more. In Azure AI Video Indexer, we understand videos – video content is more than just words, and a single shot can contain a wealth of insights that are critical for its understanding. Coupling these two powerful tools can lead to great results in video understanding and downstream tasks in natural language.
Our new API extracts and processes all the multi-modality insights of a video into prompt-ready format, that can be easily used with LLMs.
This API can be used on already-indexed videos in Azure AI Video Indexer, so there is no need to index videos again to create the prompt-ready format of the videos.
Prompt Content for Video Understanding
Azure AI Video Indexer has a new algorithm that translates the multi-modality content understanding into an LLM’s prompt-ready format, capturing the important details and insights in the video, which then can be used as-is to create LLM prompts for various tasks, including video summarization or search.
Figure 1– Our algorithm flow. Starting by capturing the important details and insights in the video using Azure AI Video Indexer (A, B), then splitting the video and its insights into coherent chapters based on visual context (C), and further splitting the sections based on other insights given the LLM prompt’s limitations (D).
Our new algorithm is based on advanced AI models developed in Azure AI Video Indexer. It effectively integrates all three modalities – visual, audio and text – based on the main insights from Azure AI Video Indexer, processes them and transforms them into an LLM’s prompt-ready format. The method consists of the following steps:
Extracting multi-modal insights: As shown in Figure 1, steps A+B create the insights of the video and allow for a full video understanding. However, having all the insights of the video and its transcript as a prompt for an LLM is problematic. First, because of the prompt size. Second, it’s just too much information, and we need to provide the main insights and separations to the LLM in order to get good results. Therefore, we extract the essence from each insight. For example, we eliminate small OCR, filter visual labels, and more.
Insights’ “tags”: In order to give more context to the LLM that will ease its video understanding and combining all the insights, we create “tags” that guide the LLM on the insights’ roles within the content. These tags include labels such as [OCR], [Transcript], [Audio effects] and more. An example of a section content with several “tags” is shown in Figure 2.
Chaptering to sections: We split the video and its insights into coherent chapters, that fit both the essence of the video and the prompt size. We use scene segmentation, which is based on visual content (Figure 1C). However, we don’t stop there – we also use the other modalities, such as audio and text, to divide the scenes further smartly into smaller sections to work within the limitations of LLMs. Each section fits to a prompt size and contains the content of the video at that time – including the transcript, audio events (such as clapping, dog barking etc.), and visual content (objects in the video, celebrities, and more). Each part in the video is consolidated, and the matching insights are used to create each section (Figure 1D). We determine the length of the sections, ensuring they are not too long for using them as prompts, and not too short for effective and meaningful content.
The final output is shown in Figure 3, and we call it the Prompt Content Json file.
Overall, our method combines most of all modalities to provide an effective approach to analyze videos’ content with LLMs. We show examples of two use-cases: Video-to-text summarization and searching within the video content. To exemplify the abilities of combining our prompt content with an LLM, we use videos from AKS Edge Essentials tutorials series.
Figure 2 – An example of a section’s content, created with our new algorithm and shown in the output Json file from our new API (Figure 3).
Figure 3 – An example of the output Json file from our new API.
Figure 4 – The flow from video to downstream tasks, starting with a video, extracting its insights with Azure AI Video Indexer and creating prompt content with our new algorithm. The prompt content can be used with any LLM, such as GPT, for tasks such as summarization and question-answering.
Video to Text Summarization
Video is more than just words. Today’s methods for video summarization rely mostly on the audio part of videos (transcript). Our approach enriches this information with visual and audio data. By combining these three modalities we can gain a better understanding of the video’s content, hence the potential for a better summarization that captures the essence of the video. We use a simple iterative algorithm for summarization that enables us to summarize long videos with rich content. First, we use our Prompt Content for chaptering and creating prompt-ready sections of the video, where each section includes its matching textual, audio and visual insights (as explained above). Then, at each iteration, we summarize the current section and the cumulative summary of the previous sections (given as additional information in the prompt). We can also control the summary “flavor” – whether we want to create an informative summary, a teaser and much more, by enhancing only the prompt of the final section summary.
Figure 5 – The video summarization flow. We start by using our new API to create the prompt content, that is divided into sections. Then, we use a simple iterative method for summarization using LLM.
For the summarization example, we will use a video that describes the storage architecture of AKS Edge Essentials. It also demonstrates how to create storage classes with local path and NFS, how to create a PVC, and how to test them on Linux.
Informative summary example – made with our prompt content and Chat GPT
In this video from AKS Edge Essentials, Lior and a guest demonstrate how to use local path and NFS storage classes with AKS Edge Essentials. The guest demonstrates how to create a Persistent Volume Claim (PVC) using the kubectl apply command and tests it with the kubectl exec command. He also shows how to use the Invoke-AksEdgeNodeCommand feature to interact with the node’s operating system and create a local-path-pvc. They explain the use case for using the NFS storage provisioner for multi-node clusters and how to mount the PVC using the deployment YAML file to store data. In conclusion, they explain how to use the volume-test command to view the PVC and demonstrate how to use it for application development.
As video is more than just words, and specifically in this video, an important part is the live demo showing useful commands. The highlighted sentences came from the visual only.
Teaser summary example – made with our prompt content and Chat GPT
Check out the latest AKS Edge Essentials video with Lior to learn how to deploy an NFS storage class and use it to store data. Follow along as they demonstrate how to set up persistent storage for applications using persistent volumes, persistent volume claims, and storage classes. Don’t miss this informative and educational video!
Searching within a Video Archive with Natural Language
Video archives can be huge and not easy to search. We aim to simplify video archive searching and allow question-answering by combining our Prompt Content file with a document archive search technique. This technique typically involves an embedding model, vector store, search engine, and NLP generative model. For video archive, instead of searched “documents”, we search through sections of the videos, created using our Prompt Content algorithm. Here is how we do it for video archives:
Section creation: We create sections from videos using the Prompt Content algorithm, that are based on multi-modality insights of the videos. These sections are used as the searched “documents”.
Embedding model: For each section we create embeddings using OpenAI’s ada-002 embedding model.
Storage: Cognitive Search is employed to store the sections’ content and their corresponding embeddings (vectors).
Search method: Given a query, we use OpenAI’s ada-002 to create its embeddings, and then we search the N most relevant sections by cosine similarity metric between the vectors.
Answer generation: Finally, with the top N sections, we utilize OpenAI’s Chat-GPT 3.5 Turbo model to generate a natural language answer.
This approach simplifies the process of searching within video archive and finding answers by leveraging well-established techniques from document searching and LLMs.
Figure 6 – The search flow, using Azure AI Video Indexer to create the prompt content, Cognitive Search for the search process and LLMs for embeddings and generating a textual answer based on the top search results.
Question-answering examples – AKS Edge Essentials video archive
Question: What is the PowerShell command to create a JSON template for AKS edge deployment?
Answer: The command is ‘New-AksEdgeConfig -DeploymentType ScalableCluster -NodeType LinuxAndWindows’ 1.
Citations: 1. AKS Edge Essentials scheme and Azure Arc (0:03:30)
Question: Please summarize the difference between single and multi-machine cluster?
Answer: Single machine cluster uses internal virtual switch network architecture and all the IP addresses are defined 12. Scalable cluster uses external virtual switch network architecture and all the IP addresses need to be set up as part of the deployment 12. When using single machine cluster, NAT is used, whereas scalable cluster connects directly to a physical network 2. The DNS and proxy settings are the same for both 2. Multi-machine cluster is used for industrial scenarios where one device can be used as a backup if another device goes down 3. Couldn’t find an answer to that question in this video library.
Citations: 1. AKS Edge Essentials network architecture (0:08:31) 2. AKS Edge Essentials network architecture (0:10:30) 3. AKS Edge Essentials Multi Node (0:05:40)
Video Summarization and Question-Answering Demonstrations
Check out our demonstrations for the downstream tasks using our new algorithm and API:
Question-answering demo
Summarization demo
Want to explore Video Indexer and stay up to date on all releases? Here are some helpful resources:
Use Azure Video Indexer website to access product website and get a free trial experience.
Visit Azure Video Indexer Developer Portal to learn about our APIs.
Search the Azure Video Indexer GitHub repository
Review our product documentation.
Get to know the recent features using Azure Video Indexer release notes.
Use Stack overflow community for technical questions.
To report an issue with Azure Video Indexer (paid account customers) Go to Azure portal Help + support. Create a new support request. Your request will be tracked within SLA.
Read our recent blogs in Azure Tech Community.
Microsoft Tech Community – Latest Blogs –Read More

Azure Spring Apps feature updates in Q4 2023
The following updates are now available in the Enterprise plan:
Spring Cloud Gateway supports a response cache: The response cache enables services and clients to efficiently store and reuse responses to HTTP requests. You can configure the memory size and the time-to-live of the cache and apply settings at the route-level or globally. For more information, see the Configure the response cache section of Configure VMware Spring Cloud Gateway.
API Portal supports enable/disable of the try-out option: The try-out feature enables you to try out APIs through the centric view of API Portal. You can now easily turn this feature off if there’s any security concern. For more information, see the Try out APIs in API portal section of Use API portal for VMware Tanzu.
Service connector supports application-level settings: This update enables you to efficiently configure common settings across deployments within one application. For more information, see the following articles:
Connect an Azure Cosmos DB database to your application in Azure Spring Apps
Connect Azure Cache for Redis to your application in Azure Spring Apps
Connect an Azure Database for MySQL instance to your application in Azure Spring Apps
Bind an Azure Database for PostgreSQL to your application in Azure Spring Apps
Richer information in the build history: To help you better troubleshoot build-related issues for your apps, the build history now presents richer information for all builds. For more information, see the Build history section of Use Tanzu Build Service.
The following update is now available in the Enterprise and Basic/Standard plans:
Planned maintenance (public preview): Azure Spring Apps regularly patches server-side components that your applications depend on to make sure they are secure and up to date. These components include the JDK, Spring Cloud middleware, APM, base OS image, and runtime infrastructure. For such patches to take effect, you need to restart your applications. With planned maintenance, you can schedule a time on a specific day for such mandatory restarts. For more information, see How to configure planned maintenance (preview).
Auto sync of certificates: Some Azure Spring Apps features secure your applications with certificates of your choice. With auto sync of certificates, you can now rotate your certificates in Azure Key Vault and they automatically sync to Azure Spring Apps. This enhancement makes it easier for you to manage features such as custom domain and TLS/SSL settings. For more information, see the Auto sync certificate section of Map an existing custom domain to Azure Spring Apps.
Email Us
AzureSpringCloud-Talk@service.microsoft.com
Additional Resources
Learn using an MS Learn module or self-paced workshop on GitHub.
Deploy your first Spring app to Azure!
Deploy the demo Fitness Store Spring Boot app to Azure.
Deploy the demo Animal Rescue Spring Boot app to Azure.
Learn more about implementing solutions on Azure Spring Apps.
Deploy Spring Boot apps by leveraging enterprise best practices – Azure Spring Apps Reference Architecture.
Migrate your Spring Boot, Spring Cloud, and Tomcat applications to Azure Spring Apps.
Wire Spring applications to interact with Azure services.
For feedback and questions, please raise your issues on our GitHub.
Microsoft Tech Community – Latest Blogs –Read More
ConfigMgr CMG Least Privilege Setup Approach
Hi, Jonas here!
Or as we say in the north of Germany: “Moin Moin!”
I’m a Microsoft Cloud Solution Architect and this blog post is meant as a guide to setup a ConfigMgr Cloud Management Gateway (CMG) without the need for a Global Admin to use the ConfigMgr console.
I will also briefly explain what a CMG is and how the setup looks like in Azure. This part is a mix of the official documentation and of my own view on the product.
If you are just looking for the setup guide, you can directly jump to section Least privilege approach
Feel free to check out my other articles at: https://aka.ms/JonasOhmsenBlogs
Cloud Management Gateway (CMG) overview
The Cloud Management Gateway (CMG) provides a simple way to manage Configuration Manager clients over the internet. You deploy CMG as a cloud service in Microsoft Azure. Then without more on-premises infrastructure, you can manage clients that roam on the internet or are in branch offices across the WAN. You also don’t need to expose your on-premises infrastructure to the internet.
Data flow overview
The following diagram is a simplified view of the CMG data flow.
Simplified CMG data flow overview diagram
( 1 ) The ConfigMgr service connection point connects to Azure over HTTPS port 443.
It authenticates using Microsoft Entra ID. The service connection point deploys the CMG in Azure and carries out maintenance and updates the service if required.
( 2 ) The ConfigMgr CMG connection point connects to the CMG in Azure over HTTPS. It holds the connection open and builds the channel for future two-way communication. ( 2 / 4 )
If the CMG consists of more than one virtual machine the first VM will be contacted via port 443 TCP and all other VMs will be contacted via port 10124-10139 TCP
( 3 ) A ConfigMgr client connects to the CMG over port 443. It can authenticate using Microsoft Entra ID, a PKI client authentication certificate or via ConfigMgr site-issued token.
( 4 ) The CMG forwards the client communication over the existing connection to the on-premises CMG connection point. You don’t need to open any inbound firewall ports.
( 5 ) The CMG connection point forwards the client communication to the on-premises Management Point and Software Update Point.
( 6 ) If the ConfigMgr client needs to download content in order to install an application for example, the clients will receive a necessary access token first and then downloads the content from a storage account.
( 7 ) A client can also be redirected to Microsoft Update to download updates directly from the Update CDN.
Azure resources
The main CMG components are a VM Scale Set with Load Balancer, Public IP, Virtual Network, and Network Security Group as shown in the diagram below.
The network security group has two ports open to support the load balancer. Port 443 for single instance use and port 8443 for multi-instance use. (The ports 10124-10139 described in Data flow overview are mapped to 8443 of each instance)
NOTE: The VMs use a web server certificate defined/requested by the ConfigMgr administrator (Either PKI or public certificate)
A Key Vault is used to safely store certificates and secrets used by the CMG to function correctly.
A Storage Account is used as a temporary storage for some CMG functions, but mainly as ConfigMgr content storage.
Each content will be encrypted by the on-premises ConfigMgr infrastructure and afterwards send to the Storage Account. Clients can then request an access token to download the content from the Storage Account directly. (Read more about it here)
(The content will be decrypted locally with a decryption token)
All resources together result in the CMG functionality, and they function as a PaaS solution managed by Microsoft. Read more about it here
Diagram of CMG Azure resources
App Registration ConfigMgr Server App
The server app in the above diagram is used to facilitate authentication and authorization from managed clients, users, and the CMG connection point to the Azure-based CMG components. This communication includes traffic to on-premises management points and software update points (client to CMG connections), initial CMG provisioning in Azure (CMG setup), and Microsoft Entra ID discovery.
App permissions
The server app has a client secret configured and ConfigMgr stores the client secret in the ConfigMgr database to use that for authentication.
The server app will have the Contributor role assigned for the chosen Azure Resource Group. The role grants ConfigMgr the necessary permissions to maintain the CMG Azure service. (For example all the items shown in the diagram above within the resource group)
The server app has the Entra ID Graph API permission Directory.Read.All set.
To allow ConfigMgr to read User, Group or Device resources, depending on the Entra ID discovery settings in ConfigMgr.
In addition a scope is defined to allow access on behalf of the signed-in user or device using the Client App.
The scope is therefore used to access the server app from the client app to get a token. That token is then used to authenticate a client or user via the CMG.
App Registration ConfigMgr Client App
The client app represents managed clients and users that connect to the CMG.
App permissions
ConfigMgr clients use the client app to request an Entra ID token via delegated permissions on the server app IF ConfigMgr Client detects a client in Entra ID join state.
The app is configured with delegated User.Read permission and permissions to impersonate the user against the server app.
In summary, the server app is used by the ConfigMgr infrastructure for Entra ID discovery and CMG maintenance and for client authentication requests coming from the client app.
While the client app is only used by ConfigMgr clients.
NOTE: It is also possible to onboard additional Entra ID tenants and therefore allow ConfigMgr to authenticate clients of those other tenants as well to access a CMG.
(Each added tenant will use a client and server app for authentication)
While there are other methods for client authentication like with a certificate or ConfigMgr token, this blog is focused on Entra ID authentication.
Simplified auth flow diagram
The following diagram shows a very simplified view of the authentication flow with the app registrations.
The ConfigMgr infrastructure will use the Server app for Entra ID discovery and CMG setup and maintenance (green arrows)
The client app is used to authenticate clients so that they can connect to the CMG (purple arrows)
Simplified CMG auth flow diagram
Installation permission requirements
The CMG installation has different requirements like a web server certificate for the CMG webservice in Azure or the specific ULRs for outbound traffic from ConfigMgr to Azure.
This section covers just the required permissions.
The CMG setup works in two steps:
Step 1: A new Azure service needs to be created in ConfigMgr.
The setup wizard asks for Global Administrator credentials to register the Server and Client App in Entra ID for the new Azure service in ConfigMgr.
Those apps can also be created manually and later imported into ConfigMgr without the need for a Global Admin to login during the setup phase. See Least privilege approach
This step is done once per Tenant/EntraID
Existing app registrations are visible in ConfigMgr as a “Tenants” and each tenant has its own app registrations.
Step 2: The second step is to create the Azure resources shown under Azure resources
The CMG wizard then asks for Subscription Owner credentials to be able to create the required resources and to be able to set Contributor permissions for the Server app as described under App Registration ConfigMgr Server App
The subscription owner permission is only required once for the initial setup. After that, ConfigMgr will use the Server app for CMG maintenance tasks.
Least privilege approach
Using the ConfigMgr wizard requires Global Administrator privileges to create the app registrations and set up a Resource Group in Azure for the CMG deployment.
A Global Administrator can also prepare the app registrations and necessary permissions before the CMG setup to avoid the need for any Global Admin login during CMG setup.
The following section describes that process.
Use a global administrator for the following actions or any other user with sufficient permissions.
Select or create a subscription for CMG deployment
Make sure that all required resources as well as VM sizes are available in the subscription and not blocked by any Azure policy for example
Register the following resource providers
Microsoft.KeyVault
Microsoft.Storage
Microsoft.Network
Microsoft.Compute
Select or create a new Resource Group in the selected subscription for CMG deployment
Keep in mind that the server app will have contributor permissions on the Resource Group
Create Entra ID ConfigMgr app registrations and make note of the required IDs as described here
Go back to the selected Resource Group and assign the Contributor role for the ConfigMgr server app you created earlier:
Go to: “Access control (IAM)”
Click on “+ Add” and “add role assignment”
Select “Privileged administrator roles” and select “Contributor”
Click “Next” and “+ select members”
Type the name of the ConfigMgr server app you just created, select the app in the list and click “Select”
Click “Review + assign”
Share all gathered data with the ConfigMgr Full-Admin
Tenant name
Tenant ID
Subscription ID
App names and IDs of both registered apps
App ID URI or server app
The server app secret and expiration date
The resource group name and Azure region
A ConfigMgr Full-Administrator can now import the app registrations into ConfigMgr and start the CMG setup process.
It is important to use the PowerShell cmdlet shown below and not the wizard to avoid the need for global admin permissions at this point in the setup process.
Start the ConfigMgr console as a ConfigMgr full administrator
Import the app registrations into ConfigMgr as described here
Request a service certificate for the CMG as described here
Add all the gathered data to the following script
Adjust or add any of the parameters as needed
Run it in ConfigMgr context and monitor CloudMgr.log for installation details:
# Password for the CMG service certificate
$ServiceCertPassword = ConvertTo-SecureString -AsPlainText ‘PASSWORD-STRING’ -Force
$paramSplatting = @{
GroupName = ‘NAME’ # Azure resource group name
ServerAppClientId = ‘ID’ # ID of ConfigMgr server app
ServiceCertPath = “C:Tempcmg.pfx” # Path to CMG service certificate
ServiceCertPassword = $ServiceCertPassword
SubscriptionId = ‘ID’ # SubscriptionId
TenantId = ‘ID’ # TenantId
VMSSVMSize = ‘StandardB2S’ # Choose VM Size
VMInstanceCount = 1 # Count of VM instances
EnableCloudDPFunction = $True
CheckClientCertRevocation = $false
EnforceProtocol = $True
Region = ‘WestEurope’ # Set region. SEE NOTE BELOW
}
# Actual install command
New-CMCloudManagementGateway @paramSplatting
# Read more about the Cmdlet here:
# https://learn.microsoft.com/en-us/powershell/module/configurationmanager/new-cmcloudmanagementgateway?view=sccm-ps
<#
NOTE: New-CMCloudManagementGateway in version 2309 only accepts EastUS, SouthCentralUS, WestEurope, SoutheastAsia, WestUS2 and WestCentralUS as values for the region parameter at the moment, even though more regions can be chosen.
#>
This two-step process does not require any extra permissions for the ConfigMgr administrator in Azure.
However, the ConfigMgr administrator should have at least read permissions on the resource group hosting the CMG to be able to check the service if required.
NOTE: When using the ConfigMgr CMG setup wizard you might see a permission request as shown below:
Permission request screenshot
Those permissions are only required for the duration of the setup and can be deleted after CMG setup is done.
I hope you enjoyed reading this blog post. Stay safe!
Jonas Ohmsen
Microsoft Tech Community – Latest Blogs –Read More

How Kusto graph semantics can help solve a classic graph problem: the Seven Bridges of Königsberg
Introduction: The Seven Bridges of Königsberg
Graph theory is a branch of mathematics that studies the properties of graphs, which are mathematical structures composed of nodes (or vertices) and edges (or links) that connect them. Graphs can be used to model many real-world phenomena, such as social networks, the structure of the internet, the spread of diseases, or the flow of traffic.
Graph theory was started by Leonhard Euler in 1736 when he tried to solve a famous problem, called the Seven Bridges of Königsberg. The problem is based on the city of Königsberg (now Kaliningrad, Russia), which had four areas (two islands and two mainland parts) connected by seven bridges, as shown in the figure below.
The problem is to devise a walk through the city that would cross each of those bridges once and only once. Such a walk is now called an Eulerian path, in honor of Euler. Euler suggested to model the problem as a graph – with areas described as nodes, and bridges as edges between nodes. Euler proved that such a path is impossible for the Königsberg bridges by calculating degree – the total number of edges connected to a node.
Any node with an odd degree has to be a start or an end of the path. For example, for a node with a degree of three, a path can enter it, leave it and then enter it again. The same is correct for any odd number. In the Königsberg graph, all four nodes have odd degrees: three, three, three, and five. This means that there are no possible Eulerian paths, since we would have to start and end at all four nodes, which is impossible for a single path. This is a general criterion: an Eulerian path exists in a graph if and only if the number of nodes with an odd degree is zero or two.
In the following sections we are going to discuss how the bridges problem can be solved empirically using Kusto graph operators – starting with a quick recap of Kusto capabilities.
Exploring graph problems with Kusto graph operators
Kusto is a powerful Engine that enables us to analyze large-scale data. The Kusto Query Language (KQL) also supports graph operators, which allow us to perform complex graph operations on tabular data, such as finding paths, cycles or subgraphs. Graph operators can help us gain insights into the structure and behavior of various kinds of networks, such as web graphs, social networks, network security or connected industrial assets. They are available in every Microsoft offering that provides access to KQL.
Fabric Real-Time Analytics (KQL Databases)
Azure Data Explorer
Free cluster
Azure Monitor
Microsoft Sentinel
One of the graph operators in Kusto is graph-match, which allows us to find patterns in a graph based on a specified pattern expression. For example, we can use graph-match to find all the paths of a certain length between two nodes, or all the cycles that include a certain edge. Graph-match also supports various parameters that control how the patterns are matched, such as the direction of the edges, the uniqueness of the nodes and edges, and the maximum number of hops.
We can use Kusto graph operators to validate Euler’s solution to the Königsberg problem empirically using different parameters. To do so, we first need to create two tables: one for the nodes and one for the edges of the graph. The nodes table contains the name and the type of each node (mainland or island), while the edges table contains the source, the target, the name, and the type of each edge (bridge). Here is an example using a datatable operator in KQL:
let nodes = datatable(nodeName:string, nodeType:string)
[
“north”, “mainland”,
“east”, “island”,
“south”, “mainland”,
“west”, “island”
];
let edges = datatable(source:string, target:string, edgeName:string, edgeType:string)
[
“north”, “east”, “b1”, “bridge”,
“north”, “west”, “b2”, “bridge”,
“north”, “west”, “b3”, “bridge”,
“east”, “west”, “b4”, “bridge”,
“east”, “south”, “b5”, “bridge”,
“west”, “south”, “b6”, “bridge”,
“west”, “south”, “b7”, “bridge”
];
Next, we can use the make-graph operator to create a graph object from the tables, using the nodeName column as the node identifier and the source and target columns as the edge endpoints. The execution creates a graph object:
edges
| make-graph source –> target with nodes on nodeName
Now we can use the graph-match operator to find different patterns in the graph, such as paths and cycles. The graph-match operator takes a graph object and a pattern expression as inputs and returns a tabular expression matches. The pattern expression consists of node and edge variables, connected by edge operators (–, ->, or <-). For example, the pattern expression (s)-[e]->(t) represents a directed edge from node s to node t, with edge e. The pattern expression (s)-[e]-(t) represents an undirected edge between node s and node t, with edge e. The pattern expression (s)-[e*1..8]-(t) represents a path of length 1 to 8 between node s and node t, with edge e as a wildcard. We chose the names s, e and t to represent source, edge and target respectively, but any variable names can be used.
The graph-match operator also supports a parameter to handle cycles. The possible values are:
unique_edges (default): allows repeated visits to nodes, but not repeated visits to edges. This is equivalent to finding Eulerian paths or cycles in the graph.
none: does not allow any repetitions of nodes or edges. This is equivalent to finding simple paths in the graph.
all: allows any repetitions of nodes and edges. This is equivalent to finding all possible paths or cycles in the graph.
We can use different combinations of pattern expressions and parameters to explore the Königsberg graph and see how they affect the number and length of the matches. For example:
edges
| make-graph source –> target with nodes on nodeName
| graph-match cycles = unique_edges (s)-[e*1..8]-(t)
project source = s.nodeName
, target = t.nodeName
, usedEdges = todynamic(e.edgeName)
| extend countEdges = array_length(usedEdges)
| summarize countPaths = count(), maxEdges = max(countEdges)
Here are some examples of using the graph-match operator with different parameter values, along with the number of paths, the maximum number of used edges, and a brief description of the results:
Graph-match pattern
Number of paths
Max number of edges
Description
| graph-match
(s)-[e]->(t)
7
1
This recreates the edges table, since each bridge is travelled in the direction provided in edges table, and we limit the paths to one hop.
| graph-match
(s)-[e]-(t)
14
1
Each bridge can be travelled in any direction, so it appears twice (as a->b and b->a).
| graph-match
cycles = none
(s)-[e*1..8]-(t)
76
3
In this case, no repetitions are possible (neither edges nor nodes).
The result is a list all the options to visit any area not more than once using any connecting bridge not more than once.
| graph-match
(s)-[e*1..8]-(t)
or
| graph-match
cycles = unique_edges (s)-[e*1..8]-(t)
820
6
The default parameter value is cycles = unique_edges, in which case repeated visits to nodes are allowed, but not repeated visits to edges. This recreates the conditions of the problem: we can use each bridge only once. Since maximum number of edges is 6, we can see that we can’t get to all the 7 bridges in this way. This validates the proposed solution.
| graph-match
cycles = all
(s)-[e*1..8]-(t)
163792
8
This allows to repeat usage of both nodes and edges, thus listing all possible combinations of paths, including cycles of different lengths.
As you can see, even small data can generate complex patterns and huge number of paths. Using Kusto graph semantics you can easily model and explore such patterns to gain insights from your data.
The Kusto Detective Agency is a great way to experience the usefulness of Kusto Graph Semantics. Help rescuing Prof. Smoke using the power of graphs.
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More







