

Category: Microsoft
Category Archives: Microsoft
ConfigMgr CMG Least Privilege Setup Approach
Hi, Jonas here!
Or as we say in the north of Germany: “Moin Moin!”
I’m a Microsoft Cloud Solution Architect and this blog post is meant as a guide to setup a ConfigMgr Cloud Management Gateway (CMG) without the need for a Global Admin to use the ConfigMgr console.
I will also briefly explain what a CMG is and how the setup looks like in Azure. This part is a mix of the official documentation and of my own view on the product.
If you are just looking for the setup guide, you can directly jump to section Least privilege approach
Feel free to check out my other articles at: https://aka.ms/JonasOhmsenBlogs
Cloud Management Gateway (CMG) overview
The Cloud Management Gateway (CMG) provides a simple way to manage Configuration Manager clients over the internet. You deploy CMG as a cloud service in Microsoft Azure. Then without more on-premises infrastructure, you can manage clients that roam on the internet or are in branch offices across the WAN. You also don’t need to expose your on-premises infrastructure to the internet.
Data flow overview
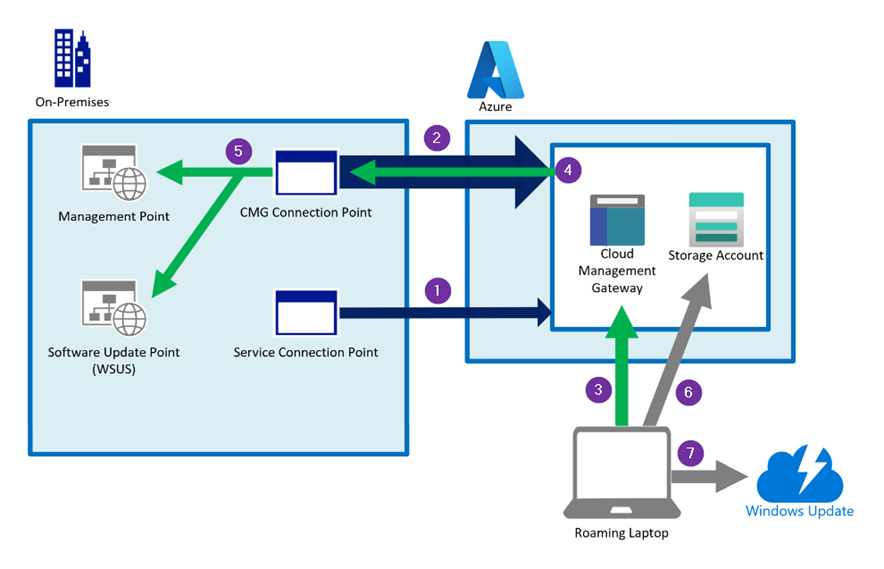
The following diagram is a simplified view of the CMG data flow.
Simplified CMG data flow overview diagram
( 1 ) The ConfigMgr service connection point connects to Azure over HTTPS port 443.
It authenticates using Microsoft Entra ID. The service connection point deploys the CMG in Azure and carries out maintenance and updates the service if required.
( 2 ) The ConfigMgr CMG connection point connects to the CMG in Azure over HTTPS. It holds the connection open and builds the channel for future two-way communication. ( 2 / 4 )
If the CMG consists of more than one virtual machine the first VM will be contacted via port 443 TCP and all other VMs will be contacted via port 10124-10139 TCP
( 3 ) A ConfigMgr client connects to the CMG over port 443. It can authenticate using Microsoft Entra ID, a PKI client authentication certificate or via ConfigMgr site-issued token.
( 4 ) The CMG forwards the client communication over the existing connection to the on-premises CMG connection point. You don’t need to open any inbound firewall ports.
( 5 ) The CMG connection point forwards the client communication to the on-premises Management Point and Software Update Point.
( 6 ) If the ConfigMgr client needs to download content in order to install an application for example, the clients will receive a necessary access token first and then downloads the content from a storage account.
( 7 ) A client can also be redirected to Microsoft Update to download updates directly from the Update CDN.
Azure resources
The main CMG components are a VM Scale Set with Load Balancer, Public IP, Virtual Network, and Network Security Group as shown in the diagram below.
The network security group has two ports open to support the load balancer. Port 443 for single instance use and port 8443 for multi-instance use. (The ports 10124-10139 described in Data flow overview are mapped to 8443 of each instance)
NOTE: The VMs use a web server certificate defined/requested by the ConfigMgr administrator (Either PKI or public certificate)
A Key Vault is used to safely store certificates and secrets used by the CMG to function correctly.
A Storage Account is used as a temporary storage for some CMG functions, but mainly as ConfigMgr content storage.
Each content will be encrypted by the on-premises ConfigMgr infrastructure and afterwards send to the Storage Account. Clients can then request an access token to download the content from the Storage Account directly. (Read more about it here)
(The content will be decrypted locally with a decryption token)
All resources together result in the CMG functionality, and they function as a PaaS solution managed by Microsoft. Read more about it here
Diagram of CMG Azure resources
App Registration ConfigMgr Server App
The server app in the above diagram is used to facilitate authentication and authorization from managed clients, users, and the CMG connection point to the Azure-based CMG components. This communication includes traffic to on-premises management points and software update points (client to CMG connections), initial CMG provisioning in Azure (CMG setup), and Microsoft Entra ID discovery.
App permissions
The server app has a client secret configured and ConfigMgr stores the client secret in the ConfigMgr database to use that for authentication.
The server app will have the Contributor role assigned for the chosen Azure Resource Group. The role grants ConfigMgr the necessary permissions to maintain the CMG Azure service. (For example all the items shown in the diagram above within the resource group)
The server app has the Entra ID Graph API permission Directory.Read.All set.
To allow ConfigMgr to read User, Group or Device resources, depending on the Entra ID discovery settings in ConfigMgr.
In addition a scope is defined to allow access on behalf of the signed-in user or device using the Client App.
The scope is therefore used to access the server app from the client app to get a token. That token is then used to authenticate a client or user via the CMG.
App Registration ConfigMgr Client App
The client app represents managed clients and users that connect to the CMG.
App permissions
ConfigMgr clients use the client app to request an Entra ID token via delegated permissions on the server app IF ConfigMgr Client detects a client in Entra ID join state.
The app is configured with delegated User.Read permission and permissions to impersonate the user against the server app.
In summary, the server app is used by the ConfigMgr infrastructure for Entra ID discovery and CMG maintenance and for client authentication requests coming from the client app.
While the client app is only used by ConfigMgr clients.
NOTE: It is also possible to onboard additional Entra ID tenants and therefore allow ConfigMgr to authenticate clients of those other tenants as well to access a CMG.
(Each added tenant will use a client and server app for authentication)
While there are other methods for client authentication like with a certificate or ConfigMgr token, this blog is focused on Entra ID authentication.
Simplified auth flow diagram
The following diagram shows a very simplified view of the authentication flow with the app registrations.
The ConfigMgr infrastructure will use the Server app for Entra ID discovery and CMG setup and maintenance (green arrows)
The client app is used to authenticate clients so that they can connect to the CMG (purple arrows)
Simplified CMG auth flow diagram
Installation permission requirements
The CMG installation has different requirements like a web server certificate for the CMG webservice in Azure or the specific ULRs for outbound traffic from ConfigMgr to Azure.
This section covers just the required permissions.
The CMG setup works in two steps:
Step 1: A new Azure service needs to be created in ConfigMgr.
The setup wizard asks for Global Administrator credentials to register the Server and Client App in Entra ID for the new Azure service in ConfigMgr.
Those apps can also be created manually and later imported into ConfigMgr without the need for a Global Admin to login during the setup phase. See Least privilege approach
This step is done once per Tenant/EntraID
Existing app registrations are visible in ConfigMgr as a “Tenants” and each tenant has its own app registrations.
Step 2: The second step is to create the Azure resources shown under Azure resources
The CMG wizard then asks for Subscription Owner credentials to be able to create the required resources and to be able to set Contributor permissions for the Server app as described under App Registration ConfigMgr Server App
The subscription owner permission is only required once for the initial setup. After that, ConfigMgr will use the Server app for CMG maintenance tasks.
Least privilege approach
Using the ConfigMgr wizard requires Global Administrator privileges to create the app registrations and set up a Resource Group in Azure for the CMG deployment.
A Global Administrator can also prepare the app registrations and necessary permissions before the CMG setup to avoid the need for any Global Admin login during CMG setup.
The following section describes that process.
Use a global administrator for the following actions or any other user with sufficient permissions.
Select or create a subscription for CMG deployment
Make sure that all required resources as well as VM sizes are available in the subscription and not blocked by any Azure policy for example
Register the following resource providers
Microsoft.KeyVault
Microsoft.Storage
Microsoft.Network
Microsoft.Compute
Select or create a new Resource Group in the selected subscription for CMG deployment
Keep in mind that the server app will have contributor permissions on the Resource Group
Create Entra ID ConfigMgr app registrations and make note of the required IDs as described here
Go back to the selected Resource Group and assign the Contributor role for the ConfigMgr server app you created earlier:
Go to: “Access control (IAM)”
Click on “+ Add” and “add role assignment”
Select “Privileged administrator roles” and select “Contributor”
Click “Next” and “+ select members”
Type the name of the ConfigMgr server app you just created, select the app in the list and click “Select”
Click “Review + assign”
Share all gathered data with the ConfigMgr Full-Admin
Tenant name
Tenant ID
Subscription ID
App names and IDs of both registered apps
App ID URI or server app
The server app secret and expiration date
The resource group name and Azure region
A ConfigMgr Full-Administrator can now import the app registrations into ConfigMgr and start the CMG setup process.
It is important to use the PowerShell cmdlet shown below and not the wizard to avoid the need for global admin permissions at this point in the setup process.
Start the ConfigMgr console as a ConfigMgr full administrator
Import the app registrations into ConfigMgr as described here
Request a service certificate for the CMG as described here
Add all the gathered data to the following script
Adjust or add any of the parameters as needed
Run it in ConfigMgr context and monitor CloudMgr.log for installation details:
# Password for the CMG service certificate
$ServiceCertPassword = ConvertTo-SecureString -AsPlainText ‘PASSWORD-STRING’ -Force
$paramSplatting = @{
GroupName = ‘NAME’ # Azure resource group name
ServerAppClientId = ‘ID’ # ID of ConfigMgr server app
ServiceCertPath = “C:Tempcmg.pfx” # Path to CMG service certificate
ServiceCertPassword = $ServiceCertPassword
SubscriptionId = ‘ID’ # SubscriptionId
TenantId = ‘ID’ # TenantId
VMSSVMSize = ‘StandardB2S’ # Choose VM Size
VMInstanceCount = 1 # Count of VM instances
EnableCloudDPFunction = $True
CheckClientCertRevocation = $false
EnforceProtocol = $True
Region = ‘WestEurope’ # Set region. SEE NOTE BELOW
}
# Actual install command
New-CMCloudManagementGateway @paramSplatting
# Read more about the Cmdlet here:
# https://learn.microsoft.com/en-us/powershell/module/configurationmanager/new-cmcloudmanagementgateway?view=sccm-ps
<#
NOTE: New-CMCloudManagementGateway in version 2309 only accepts EastUS, SouthCentralUS, WestEurope, SoutheastAsia, WestUS2 and WestCentralUS as values for the region parameter at the moment, even though more regions can be chosen.
#>
This two-step process does not require any extra permissions for the ConfigMgr administrator in Azure.
However, the ConfigMgr administrator should have at least read permissions on the resource group hosting the CMG to be able to check the service if required.
NOTE: When using the ConfigMgr CMG setup wizard you might see a permission request as shown below:
Permission request screenshot
Those permissions are only required for the duration of the setup and can be deleted after CMG setup is done.
I hope you enjoyed reading this blog post. Stay safe!
Jonas Ohmsen
Microsoft Tech Community – Latest Blogs –Read More

How Kusto graph semantics can help solve a classic graph problem: the Seven Bridges of Königsberg
Introduction: The Seven Bridges of Königsberg
Graph theory is a branch of mathematics that studies the properties of graphs, which are mathematical structures composed of nodes (or vertices) and edges (or links) that connect them. Graphs can be used to model many real-world phenomena, such as social networks, the structure of the internet, the spread of diseases, or the flow of traffic.
Graph theory was started by Leonhard Euler in 1736 when he tried to solve a famous problem, called the Seven Bridges of Königsberg. The problem is based on the city of Königsberg (now Kaliningrad, Russia), which had four areas (two islands and two mainland parts) connected by seven bridges, as shown in the figure below.
The problem is to devise a walk through the city that would cross each of those bridges once and only once. Such a walk is now called an Eulerian path, in honor of Euler. Euler suggested to model the problem as a graph – with areas described as nodes, and bridges as edges between nodes. Euler proved that such a path is impossible for the Königsberg bridges by calculating degree – the total number of edges connected to a node.
Any node with an odd degree has to be a start or an end of the path. For example, for a node with a degree of three, a path can enter it, leave it and then enter it again. The same is correct for any odd number. In the Königsberg graph, all four nodes have odd degrees: three, three, three, and five. This means that there are no possible Eulerian paths, since we would have to start and end at all four nodes, which is impossible for a single path. This is a general criterion: an Eulerian path exists in a graph if and only if the number of nodes with an odd degree is zero or two.
In the following sections we are going to discuss how the bridges problem can be solved empirically using Kusto graph operators – starting with a quick recap of Kusto capabilities.
Exploring graph problems with Kusto graph operators
Kusto is a powerful Engine that enables us to analyze large-scale data. The Kusto Query Language (KQL) also supports graph operators, which allow us to perform complex graph operations on tabular data, such as finding paths, cycles or subgraphs. Graph operators can help us gain insights into the structure and behavior of various kinds of networks, such as web graphs, social networks, network security or connected industrial assets. They are available in every Microsoft offering that provides access to KQL.
Fabric Real-Time Analytics (KQL Databases)
Azure Data Explorer
Free cluster
Azure Monitor
Microsoft Sentinel
One of the graph operators in Kusto is graph-match, which allows us to find patterns in a graph based on a specified pattern expression. For example, we can use graph-match to find all the paths of a certain length between two nodes, or all the cycles that include a certain edge. Graph-match also supports various parameters that control how the patterns are matched, such as the direction of the edges, the uniqueness of the nodes and edges, and the maximum number of hops.
We can use Kusto graph operators to validate Euler’s solution to the Königsberg problem empirically using different parameters. To do so, we first need to create two tables: one for the nodes and one for the edges of the graph. The nodes table contains the name and the type of each node (mainland or island), while the edges table contains the source, the target, the name, and the type of each edge (bridge). Here is an example using a datatable operator in KQL:
let nodes = datatable(nodeName:string, nodeType:string)
[
“north”, “mainland”,
“east”, “island”,
“south”, “mainland”,
“west”, “island”
];
let edges = datatable(source:string, target:string, edgeName:string, edgeType:string)
[
“north”, “east”, “b1”, “bridge”,
“north”, “west”, “b2”, “bridge”,
“north”, “west”, “b3”, “bridge”,
“east”, “west”, “b4”, “bridge”,
“east”, “south”, “b5”, “bridge”,
“west”, “south”, “b6”, “bridge”,
“west”, “south”, “b7”, “bridge”
];
Next, we can use the make-graph operator to create a graph object from the tables, using the nodeName column as the node identifier and the source and target columns as the edge endpoints. The execution creates a graph object:
edges
| make-graph source –> target with nodes on nodeName
Now we can use the graph-match operator to find different patterns in the graph, such as paths and cycles. The graph-match operator takes a graph object and a pattern expression as inputs and returns a tabular expression matches. The pattern expression consists of node and edge variables, connected by edge operators (–, ->, or <-). For example, the pattern expression (s)-[e]->(t) represents a directed edge from node s to node t, with edge e. The pattern expression (s)-[e]-(t) represents an undirected edge between node s and node t, with edge e. The pattern expression (s)-[e*1..8]-(t) represents a path of length 1 to 8 between node s and node t, with edge e as a wildcard. We chose the names s, e and t to represent source, edge and target respectively, but any variable names can be used.
The graph-match operator also supports a parameter to handle cycles. The possible values are:
unique_edges (default): allows repeated visits to nodes, but not repeated visits to edges. This is equivalent to finding Eulerian paths or cycles in the graph.
none: does not allow any repetitions of nodes or edges. This is equivalent to finding simple paths in the graph.
all: allows any repetitions of nodes and edges. This is equivalent to finding all possible paths or cycles in the graph.
We can use different combinations of pattern expressions and parameters to explore the Königsberg graph and see how they affect the number and length of the matches. For example:
edges
| make-graph source –> target with nodes on nodeName
| graph-match cycles = unique_edges (s)-[e*1..8]-(t)
project source = s.nodeName
, target = t.nodeName
, usedEdges = todynamic(e.edgeName)
| extend countEdges = array_length(usedEdges)
| summarize countPaths = count(), maxEdges = max(countEdges)
Here are some examples of using the graph-match operator with different parameter values, along with the number of paths, the maximum number of used edges, and a brief description of the results:
Graph-match pattern
Number of paths
Max number of edges
Description
| graph-match
(s)-[e]->(t)
7
1
This recreates the edges table, since each bridge is travelled in the direction provided in edges table, and we limit the paths to one hop.
| graph-match
(s)-[e]-(t)
14
1
Each bridge can be travelled in any direction, so it appears twice (as a->b and b->a).
| graph-match
cycles = none
(s)-[e*1..8]-(t)
76
3
In this case, no repetitions are possible (neither edges nor nodes).
The result is a list all the options to visit any area not more than once using any connecting bridge not more than once.
| graph-match
(s)-[e*1..8]-(t)
or
| graph-match
cycles = unique_edges (s)-[e*1..8]-(t)
820
6
The default parameter value is cycles = unique_edges, in which case repeated visits to nodes are allowed, but not repeated visits to edges. This recreates the conditions of the problem: we can use each bridge only once. Since maximum number of edges is 6, we can see that we can’t get to all the 7 bridges in this way. This validates the proposed solution.
| graph-match
cycles = all
(s)-[e*1..8]-(t)
163792
8
This allows to repeat usage of both nodes and edges, thus listing all possible combinations of paths, including cycles of different lengths.
As you can see, even small data can generate complex patterns and huge number of paths. Using Kusto graph semantics you can easily model and explore such patterns to gain insights from your data.
The Kusto Detective Agency is a great way to experience the usefulness of Kusto Graph Semantics. Help rescuing Prof. Smoke using the power of graphs.
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More
Future-Proofing AI: Strategies for Effective Model Upgrades in Azure OpenAI
TL;DR: This post navigates the intricate world of AI model upgrades, with a spotlight on Azure OpenAI’s embedding models like text-embedding-ada-002. We emphasize the critical importance of consistent model versioning ensuring accuracy and validity in AI applications. The post also addresses the challenges and strategies essential for effectively managing model upgrades, focusing on compatibility and performance testing.
Introduction
What are Embeddings?
Embeddings in machine learning are more than just data transformations. They are the cornerstone of how AI interprets the nuances of language, context, and semantics. By converting text into numerical vectors, embeddings allow AI models to measure similarities and differences in meaning, paving the way for advanced applications in various fields.
Importance of Embeddings
In the complex world of data science and machine learning, embeddings are crucial for handling intricate data types like natural language and images. They transform these data into structured, vectorized forms, making them more manageable for computational analysis. This transformation isn’t just about simplifying data; it’s about retaining and emphasizing the essential features and relationships in the original data, which are vital for precise analysis and decision-making.
Embeddings significantly enhance data processing efficiency. They allow algorithms to swiftly navigate through large datasets, identifying patterns and nuances that are difficult to detect in raw data. This is particularly transformative in natural language processing, where comprehending context, sentiment, and semantic meaning is complex. By streamlining these tasks, embeddings enable deeper, more sophisticated analysis, thus boosting the effectiveness of machine learning models.
Implications of Model Version Mismatches in Embeddings
Lets discuss the potential impacts and challenges that arise when different versions of embedding models are used within the same domain, specifically focusing on Azure OpenAI embeddings. When embeddings generated by one version of a model are applied or compared with data processed by a different version, various issues can arise. These issues are not only technical but also have practical implications on the efficiency, accuracy, and overall performance of AI-driven applications.
Compatibility and Consistency Issues
Vector Space Misalignment: Different versions of embedding models might organize their vector spaces differently. This misalignment can lead to inaccurate comparisons or analyses when embeddings from different model versions are used together.
Semantic Drift: Over time, models might be trained on new data or with updated techniques, causing shifts in how they interpret and represent language (semantic drift). This drift can cause inconsistencies when integrating new embeddings with those generated by older versions.
Impact on Performance
Reduced Accuracy: Inaccuracies in semantic understanding or context interpretation can occur when different model versions process the same text, leading to reduced accuracy in tasks like search, recommendation, or sentiment analysis.
Inefficiency in Data Processing: Mismatches in model versions can require additional computational resources to reconcile or adjust the differing embeddings, leading to inefficiencies in data processing and increased operational costs.
Best Practices for Upgrading Embedding Models
Upgrading Embedding – Overview
Now lets move to the process of upgrading an embedding model, focusing on the steps you should take before making a change, important questions to consider, and key areas for testing.
Pre-Upgrade Considerations
Assessing the Need for Upgrade:
Why is the upgrade necessary?
What specific improvements or new features does the new model version offer?
How will these changes impact the current system or process?
Understanding Model Changes:
What are the major differences between the current and new model versions?
How might these differences affect data processing and results?
Data Backup and Version Control:
Ensure that current data and model versions are backed up.
Implement version control to maintain a record of changes.
Questions to Ask Before Upgrading
Compatibility with Existing Systems:
Is the new model version compatible with existing data formats and infrastructure?
What adjustments, if any, will be needed to integrate the new model?
Cost-Benefit Analysis:
What are the anticipated costs (monetary, time, resources) of the upgrade?
How do these costs compare to the expected benefits?
Long-Term Support and Updates:
Does the new model version have a roadmap for future updates and support?
How will these future changes impact the system?
Key Areas for Testing
Performance Testing:
Test the new model version for performance improvements or regressions.
Compare accuracy, speed, and resource usage against the current version.
Compatibility Testing:
Ensure that the new model works seamlessly with existing data and systems.
Test for any integration issues or data format mismatches.
Fallback Strategies:
Develop and test fallback strategies in case the new model does not perform as expected.
Ensure the ability to revert to the previous model version if necessary.
Post-Upgrade Best Practices
Monitoring and Evaluation:
Continuously monitor the system’s performance post-upgrade.
Evaluate whether the upgrade meets the anticipated goals and objectives.
Feedback Loop:
Establish a feedback loop to collect user and system performance data.
Use this data to make informed decisions about future upgrades or changes.
Upgrading Embedding – Conclusion
Upgrading an embedding model involves careful consideration, planning, and testing. By following these guidelines, customers can ensure a smooth transition to the new model version, minimizing potential risks and maximizing the benefits of the upgrade.
Use Cases in Azure OpenAI and Beyond
Embedding can significantly enhance the performance of various AI applications by enabling more efficient data handling and processing. Here’s a list of use cases where embeddings can be effectively utilized:
Enhanced Document Retrieval and Analysis: By first performing embeddings on paragraphs or sections of documents, you can store these vector representations in a vector database. This allows for rapid retrieval of semantically similar sections, streamlining the process of analyzing large volumes of text. When integrated with models like GPT, this method can reduce the computational load and improve the efficiency of generating relevant responses or insights.
Semantic Search in Large Datasets: Embeddings can transform vast datasets into searchable vector spaces. In applications like eCommerce or content platforms, this can significantly improve search functionality, allowing users to find products or content based not just on keywords, but on the underlying semantic meaning of their queries.
Recommendation Systems: In recommendation engines, embeddings can be used to understand user preferences and content characteristics. By embedding user profiles and product or content descriptions, systems can more accurately match users with recommendations that are relevant to their interests and past behavior.
Sentiment Analysis and Customer Feedback Interpretation: Embeddings can process customer reviews or feedback by capturing the sentiment and nuanced meanings within the text. This provides businesses with deeper insights into customer sentiment, enabling them to tailor their services or products more effectively.
Language Translation and Localization: Embeddings can enhance machine translation services by understanding the context and nuances of different languages. This is particularly useful in translating idiomatic expressions or culturally specific references, thereby improving the accuracy and relevancy of translations.
Automated Content Moderation: By using embeddings to understand the context and nuance of user-generated content, AI models can more effectively identify and filter out inappropriate or harmful content, maintaining a safe and positive environment on digital platforms.
Personalized Chatbots and Virtual Assistants: Embeddings can be used to improve the understanding of user queries by virtual assistants or chatbots, leading to more accurate and contextually appropriate responses, thus enhancing user experience. With similar logic they could help route natural language to specific APIs. See CompactVectorSearch repository, as an example.
Predictive Analytics in Healthcare: In healthcare data analysis, embeddings can help in interpreting patient data, medical notes, and research papers to predict trends, treatment outcomes, and patient needs more accurately.
In all these use cases, the key advantage of using embeddings is their ability to process and interpret large and complex datasets more efficiently. This not only improves the performance of AI applications but also reduces the computational resources required, especially for high-cost models like GPT. This approach can lead to significant improvements in both the effectiveness and efficiency of AI-driven systems.
Specific Considerations for Azure OpenAI
Model Update Frequency: Understanding how frequently Azure OpenAI updates its models and the nature of these updates (e.g., major vs. minor changes) is crucial.
Backward Compatibility: Assessing whether newer versions of Azure OpenAI’s embedding models maintain backward compatibility with previous versions is key to managing version mismatches.
Version-Specific Features: Identifying features or improvements specific to certain versions of the model helps in understanding the potential impact of using mixed-version embeddings.
Strategies for Mitigation
Version Control in Data Storage: Implementing strict version control for stored embeddings ensures that data remains consistent and compatible with the model version used for its generation.
Compatibility Layers: Developing compatibility layers or conversion tools to adapt older embeddings to newer model formats can help mitigate the effects of version differences.
Baseline Tests: Create few simple baseline tests, that would identify any drift of the embeddings.
Azure OpenAI Model Versioning: Understanding the Process
Azure OpenAI provides a systematic approach to model versioning, applicable to models like text-embedding-ada-002:
Regular Model Releases:
New models are released periodically with improvements and new features.
More on model releases.
Version Update Policies:
Options for auto-updating to new versions or deploying specific versions.
Customizable update policies for flexibility.
Details on update options.
Notifications and Version Maintenance:
Advance notifications for new default versions.
Previous major versions maintained until retirement.
Information on version notifications.
Upgrade Preparation:
Recommendations to read the latest documentation and test applications with new versions.
Importance of updating code and configurations for new features.
Preparing for version upgrades.
Conclusion
Model version mismatches in embeddings, particularly in the context of Azure OpenAI, pose significant challenges that can impact the effectiveness of AI applications. Understanding these challenges and implementing strategies to mitigate their effects is crucial for maintaining the integrity and efficiency of AI-driven systems.
References
“Learn about Azure OpenAI Model Version Upgrades.” Microsoft Tech Community. Link
“OpenAI Unveils New Embedding Model.” InfoQ. Link
“Word2Vec Explained.” Guru99. Link
“GloVe: Global Vectors for Word Representation.” Stanford NLP. Link
Microsoft Tech Community – Latest Blogs –Read More







