

Category: Microsoft
Category Archives: Microsoft
Search/Find
How to delete a group of numbers next to names in a list (where the numerals can be from one to nine) e.g.
000000000|The First Time Group
000000000|The Second Time Group
000000000|The Third Time Group
000000000|The Fourth Time Group
How to delete a group of numbers next to names in a list (where the numerals can be from one to nine) e.g. 000000000|The First Time Group000000000|The Second Time Group000000000|The Third Time Group000000000|The Fourth Time Group Read More
Trusted Signing is in Public Preview
Trusted Signing has launched into Public Preview! The Trusted Signing service (formerly Azure Code Signing) is a Microsoft fully managed end-to-end signing solution for developers.
What is the Trusted Signing service?
Trusted Signing is a complete code signing service with an intuitive experience for developers and IT professionals, backed by a Microsoft managed certification authority. The service supports both public and private trust signing scenarios and includes a timestamping service. With Trusted Signing, users enjoy a productive, performant, and delightful experience on Windows with modern security protection features enabled such as Smart App Control and SmartScreen.
The service offers several key features that make signing easy:
We manage the full certificate lifecycle – generation, renewal, issuance – and key storage that is FIPS 140-2 Level 3 HSMs. The certificates are short lived certificates, which helps reduce the impact on your customers in abuse or misuse scenarios.
We have integrated into popular developer toolsets such as SignTool.exe and GitHub and Visual Studio experiences for CI/CD pipelines enabling signing to easily integrate into application build workflows. For Private Trust, there is also PowerShell cmdlets for IT Pros to sign WDAC policy and future integrations with IT endpoint management solutions.
Signing is digest signing, meaning it is fast and confidential – your files never leave your endpoint.
We have support for different certificate profile types including Public Trust, Private Trust, and Test with more coming soon!
Trusted Signing enables easy resource management and access control for all signing resources with Azure role-based access control as an Azure native resource.
To learn more about the service go to: https://learn.microsoft.com/azure/trusted-signing.
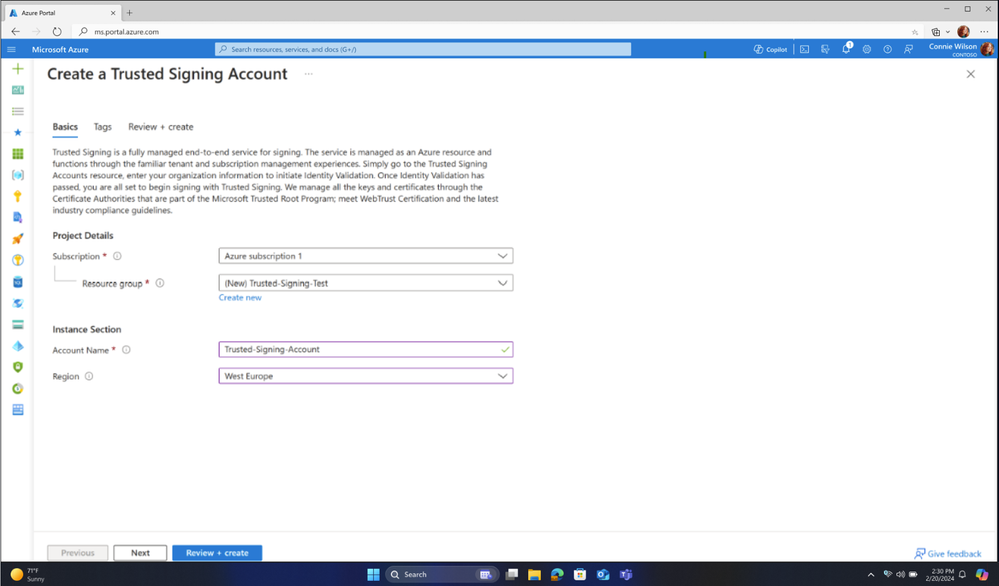
Figure 1: Creating a Trusted Signing Account
Trusted Signing Pricing
We want to make this affordable for ISVs and developers in a way that allows the community of all demographics to be able to sign. While we have two pricing SKUs, basic and premium accounts, the initial Public Preview release is free until June 2024. The details of each SKU are outlined below:
Model type
Basic
Premium
Base price (monthly)
$9.99
$99.99
Quota (signatures / month)
5,000
100,000
Price after quota is reached
$0.005 / signature
$0.005 / signature
Includes
Public and Private Signing
1 of each Certificate Profile type
Public and Private Signing
10 of each Certificate Profile Type
Try out Trusted Signing today by visiting the Azure portal.
Microsoft Tech Community – Latest Blogs –Read More
Data Discovery: The First Step to AI Readiness
Artificial intelligence (AI) is transforming the way businesses operate, innovate, and compete. AI can help enterprises improve efficiency, accuracy, and customer satisfaction, as well as create new products and services. However, AI also comes with challenges and risks, especially when it comes to data. Data is the fuel for AI, and without proper data management, enterprises may face legal, ethical, and operational issues that can undermine their AI initiatives.
Before end users start using AI, enterprises need to ensure that their data is ready for AI. This means that data is accurate, complete, relevant, and secure. It also means that data is compliant with the applicable laws and regulations, as well as the ethical and social norms of the stakeholders. To achieve this, enterprises need to follow a series of steps that can help them assess, improve, and monitor their data quality and governance. In this blog series, we will explore these steps and provide recommendations for enterprises to prepare their data for AI.
The first step is data discovery. Data discovery is the process of identifying, locating, and understanding the data sources and assets that are available for AI. Data discovery helps enterprises answer questions such as: What data do we have? Where is it stored? How is it structured? What does it contain? Who has access to it? How is it used? Data discovery is essential for enterprises to gain a comprehensive and accurate view of their data landscape and to identify the potential opportunities and risks for AI.
Key Areas of Consideration for Data Discovery
Data discovery is not a one-time activity, but a continuous and iterative process that requires collaboration and coordination across different teams and roles. Data discovery involves both technical and business aspects, and it should align with the enterprise’s strategic goals and priorities for AI. To conduct effective data discovery, enterprises should consider the following key areas:
Permissions: Enterprises should have a clear and consistent policy for data access and sharing, both internally and externally. Data permission should be based on the principle of least privilege, meaning that only the authorized users and applications should have access to the data they need for their specific purposes. Data permissions should also be documented and audited regularly, to ensure compliance and accountability.
Sensitive data: Enterprises should identify and classify the data that is sensitive or confidential, such as personal data, financial data, health data, trade secrets, or intellectual property. Sensitive data should be protected with appropriate security measures, such as encryption, masking, or anonymization. Sensitive data should also be subject to stricter data governance rules, such as retention, deletion, or consent policies.
Personally identifiable data: Enterprises should identify and classify the data that can be used to identify or link to an individual, such as name, email, phone number, address, or social security number. Personally identifiable data is a subset of sensitive data, and it may have specific legal and ethical implications, depending on the jurisdiction and the context. Enterprises should comply with the relevant data protection laws and regulations, such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA) and respect the rights and preferences of the data subjects.
Data over exposure: Enterprises should assess and monitor the level of exposure or visibility of their data, both internally and externally. Data over exposure occurs when data is accessible or visible to more users or applications than necessary, or when data is exposed to unauthorized or malicious parties. Data over exposure can lead to data breaches, data leaks, or data misuse, which can damage the enterprise’s reputation, trust, and competitiveness. Enterprises should implement data security controls, such as firewalls, access control lists, or encryption keys, to prevent or limit data over exposure.
Data oversharing: Enterprises should evaluate and control the amount and frequency of data sharing, both internally and externally. Data oversharing occurs when data is shared or transferred more than necessary, or when data is shared or transferred without proper justification or consent. Data oversharing can result in data duplication, data inconsistency, or data loss, which can affect the data quality and integrity. Enterprises should establish data sharing agreements, protocols, or standards, to ensure that data sharing is done in a secure, compliant, and efficient manner.
Microsoft solutions for data discovery
Data discovery can be a challenging and time-consuming process, especially for large and complex enterprises with multiple data sources and platforms. Microsoft offers several solutions that can help enterprises discover, catalog, classify, and protect their data assets, such as:
– Microsoft Information Protection: Microsoft Information Protection is a suite of solutions that helps enterprises protect their sensitive data across devices, apps, cloud services, and on-premises systems. Microsoft Information Protection allows enterprises to discover, classify, label, and encrypt their data, based on predefined or custom policies. Microsoft Information Protection also helps enterprises monitor and audit their data activities, and to detect and respond to data breaches or leaks. Microsoft Information Protection integrates with Microsoft 365, Azure, and Windows, as well as third-party applications and platforms. This set of capabilities is what will have the largest impact on end users and the enterprise when deploying security protections to data. To learn more about Microsoft Information Protection: Implement Information Protection in Microsoft 365 – Training
– Microsoft Purview (Previously Azure Purview): Microsoft Purview is a unified data governance service that helps enterprises manage and govern their on-premises, multicloud, and software-as-a-service (SaaS) data. Microsoft Purview provides a holistic and up-to-date view of the enterprise’s data landscape, enabling data discovery, data lineage, data cataloging, data classification, and data sensitivity analysis. Most enterprises that use Microsoft Purview do so to help comply with data privacy and security regulations, such as GDPR and CCPA, by identifying and labeling sensitive data, and applying fine-grained access policies. This solution is also available to the Defense Industrial Base within Azure Government and can help with the protection of Controlled Unclassified Information (CUI) or International Traffic in Arms Regulations (ITAR) data. To learn more visit: Unified Data Governance with Microsoft Purview | Microsoft Azure.
– Microsoft Purview Data Catalog: Data Catalog is a fully managed cloud service that helps enterprises discover, understand, and consume their data sources. Data Catalog allows data producers to register and annotate their data sources, and data consumers to search and browse the data catalog using natural language queries. Data Catalog also enables data collaboration and sharing, by allowing users to rate, review, and tag data sources, and to request access to data sets. To learn more visit: Data Catalog – Learn about Business Glossaries
Using Microsoft Information Protection for Data Discovery
One of the benefits of Microsoft Information Protection is that it can help enterprises run data discovery across their heterogeneous and distributed data environments. Data discovery is the process of finding, cataloging, and classifying data sources, and understanding their content, structure, quality, and sensitivity. Data discovery can help enterprises prepare their data for AI, as well as comply with data regulations and policies.
Microsoft Information Protection allows enterprises to use predefined or custom labels to classify and protect their data sources based on their sensitivity and business value. For example, an enterprise can use labels such as “Public”, “Internal”, “Confidential”, or “Highly Confidential” to mark their data sources according to their access requirements and risk levels. Labels can also include sub-labels for specific data types, such as “Personal Data”, “Financial Data”, “Health Data”, “CUI” or “Legal Data”. Labels can be applied manually by users, automatically by policies, or suggested by machine learning algorithms.
By applying labels to data sources, enterprises can use Microsoft Information Protection to discover and inventory their data assets and liabilities, and to understand their data distribution and exposure. For example, an enterprise can use Microsoft Information Protection to answer questions such as:
What types of data sources do we have, and where are they located?
How much of our data is sensitive, and what kind of sensitivity does it have?
Who has access to our data, and what level of protection does it have?
How often is our data accessed, modified, or shared?
Are there any anomalies or risks in our data activities or behaviors?
Microsoft Information Protection is part of Microsoft Purview and can provide a comprehensive and unified data governance solution. Microsoft Purview can leverage the labels from Microsoft Information Protection to enrich its data catalog and lineage, and to enable granular and dynamic data access policies. Microsoft Purview can also use its own scanning and classification capabilities to complement and validate the labels from Microsoft Information Protection, and to discover additional data attributes and insights. Together, Microsoft Information Protection and Microsoft Purview can help enterprises achieve data discovery at scale, and to optimize their data quality and security for AI readiness.
For defense industrial base customers that sensitive data like CUI, ITAR or Export Control (EC), they should ensure they are using the correct version of information protection for that data set. For more information about our different clouds: Understanding Compliance Between Commercial, Government and DoD Offerings – September 2023 Update – Microsoft Community Hub
Conclusion
Data discovery is the first step to AI readiness, and it can help enterprises understand their data assets and liabilities, as well as their data opportunities and risks. Data discovery can enable enterprises to select the most suitable and valuable data sources for AI, and to ensure that their data is compliant, ethical, and secure. Data discovery can also help enterprises optimize their data management and governance practices, and to foster a data-driven and AI-enabled culture. In the next blog, we will discuss the second step to AI readiness: Data Access.
Resources:
Data, Privacy, and Security for Microsoft Copilot for Microsoft 365 | Microsoft Learn
Copilot for Microsoft 365 – Microsoft Adoption
Microsoft Purview data security and compliance protections for Microsoft Copilot | Microsoft Learn
Embrace responsible AI principles and practices – Training | Microsoft Learn
Responsible AI Principles and Approach | Microsoft AI
Microsoft Responsible AI Standard v2 General Requirements
Guidelines for Human-AI Interaction – Microsoft HAX Toolkit
Microsoft Tech Community – Latest Blogs –Read More
A Heuristic Method of Merging Cross-Page Tables based on Document Intelligence Layout Model
Introduction
Tables contain valuable structured information for businesses to manage, share and analyze data, make informed decisions, and increase efficiency. Cross-page tables are common especially in lengthy or dense documents. Azure AI Document Intelligence Layout model extracts tables within each page, effectively parsing the table may require reconstituting the extracted tables into a single table. This is specifically a challenge when automating document processing with large language models (LLMs) to ensure high relevance or accuracy with automation tasks. This blog provides a heuristic approach to identifying and merging tables, this process accounts for a few different variations including vertical or horizontal cross-page tables, tables with repeating headers or continuation cells. The output can then be fed into the LLM for improved context resulting in more relevant and accurate responses. In future updates the layout model will support cross-page tables.
Step-by-Step Guide
The sample notebook consists of several key components:
1. Preparation of your document
Start by preparing the document with cross-page tables that you want to analyze. This could be in various formats, such as PDFs, Word documents, HTMLs, or images.
2. Return basic information of tables
The get_table_page_numbers function returns a list of page numbers where tables appear in your given document. The get_table_span_offsets function calculates the minimum and maximum offsets of a table’s spans.
3. Find the merge table candidates
The get_merge_table_candidates_and_table_integral_span function finds the merge table candidates and calculates the integral span of each table based on the list of tables obtained in step 2 ahead.
The check_paragraph_presence function checks if there is a paragraph within a specified range that is not a page header, page footer, or page number. If this is the case, the table is not a merge table candidate.
def check_paragraph_presence(paragraphs, start, end):
“””
Checks if there is a paragraph within the specified range that is not a page header, page footer, or page number. If this were the case, the table would not be a merge table candidate.
Args:
paragraphs (list): List of paragraphs to check.
start (int): Start offset of the range.
end (int): End offset of the range.
Returns:
bool: True if a paragraph is found within the range that meets the conditions, False otherwise.
“””
for paragraph in paragraphs:
for span in paragraph.spans:
if span.offset > start and span.offset < end:
# The logic role of a parapgaph is used to idenfiy if it’s page header, page footer, page number, title, section heading, etc. Learn more: https://learn.microsoft.com/en-us/azure/ai-services/document-intelligence/concept-layout?view=doc-intel-4.0.0#document-layout-analysis
if not hasattr(paragraph, ‘role’):
return True
elif hasattr(paragraph, ‘role’) and paragraph.role not in [“pageHeader”, “pageFooter”, “pageNumber”]:
return True
return False
4. Determine whether it is a cross-page table
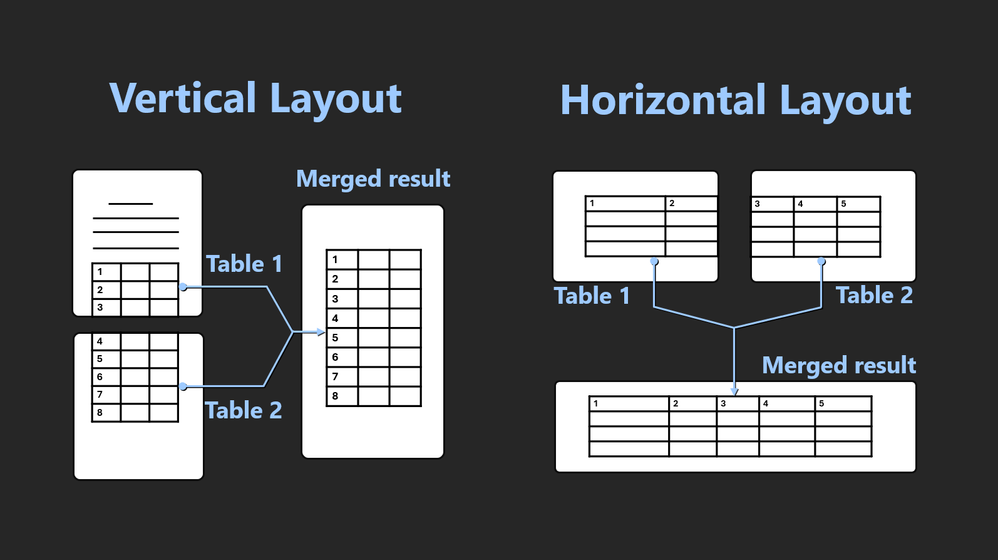
Vertical table: If there are two or more tables that emerge in successive pages, with only page headers, page footers, or page numbers lying between them, and these tables possess the identical number of columns, then these tables can be considered as one vertical table. This applies to both tables with headers on both pages and tables with headers only on the initial page.
Horizontal table: Where there are two or more tables that appear in consecutive pages, with the right side of the table being closely adjacent to the right edge of the current page, and the left side of the following table being proximate to the left edge of the succeeding page, and these tables sharing the same number of row counts, then these tables can be regarded as one horizontal table. The check_tables_are_ horizontal_distribution function identifies whether two consecutive pages are horizontally distributed.
5. Merge cross-page tables
Vertical table: If an actual table is distributed into two pages vertically. From analysis result, it will be generated as two tables in markdown format. To merge them into one table, the markdown table-header format string must be removed using the remove_header_from_markdown_table function. Then the merge_vertical_ tables function merges the two consecutive vertical markdown tables into one. When a cross-page table has headers on both pages, all header texts will be output, but the first one will be used as the header of the merged table.
def merge_vertical_tables(md_table_1, md_table_2) :
“””
Merge two consecutive vertical markdown tables into one markdown table.
Args:
md_table_1: markdown table 1
md_table_2: markdown table 2
Returns:
string: merged markdown table
“””
table2_without_header = remove_header_from_markdown_table(md_table_2)
rows1 = md_table_1.strip().splitlines()
rows2 = table2_without_header.strip().splitlines()
num_columns1 = len(rows1[0].split(BORDER_SYMBOL)) – 2
num_columns2 = len(rows2[0].split(BORDER_SYMBOL)) – 2
if num_columns1 != num_columns2:
raise ValueError(“Different count of columns”)
merged_rows = rows1 + rows2
merged_table = ‘n’.join(merged_rows)
return merged_table
Figure 1. Illustration of merging Vertical Layout
Horizontal table: If an actual table is distributed into two pages horizontally. From analysis result, it will be generated as two tables in markdown format. The merge_horizontal_tables function merges two consecutive horizontal markdown tables into one markdown table.
def merge_horizontal_tables(md_table_1, md_table_2):
“””
Merge two consecutive horizontal markdown tables into one markdown table.
Args:
md_table_1: markdown table 1
md_table_2: markdown table 2
Returns:
string: merged markdown table
“””
rows1 = md_table_1.strip().splitlines()
rows2 = md_table_2.strip().splitlines()
merged_rows = []
for row1, row2 in zip(rows1, rows2):
merged_row = (
(row1[:-1] if row1.endswith(BORDER_SYMBOL) else row1)
+ BORDER_SYMBOL
+ (row2[1:] if row2.startswith(BORDER_SYMBOL) else row2)
)
merged_rows.append(merged_row)
merged_table = “n”.join(merged_rows)
return merged_table
Figure 2. Illustration of merging Horizontal Layout
6. Merge multiple consecutive pages
The identify_and_merge_cross_page_tables function is the main function of the script. It takes an input file path as an argument and uses the Azure Document Intelligence service (involving the Layout model) to analyze the document and identify and merge tables that span across multiple pages. This solution can handle tables split over 3 or more pages. The function comprises four main steps:
Step1: Create an instance of the DocumentIntelligenceClient, specify the file path, and then use the begin_analyze_document method to analyze the document.
Step2: Get the merge tables candidates and the list of table integral span.
Step3: Make judgments and operations on table merging.
Step4: Generate optimized content based on the merged table list.
Advantages
This solution has the following benefits, allowing users to effortlessly handle cross-page tables in a wide variety of scenarios:
Preserves table semantics: By obtaining information such as the page number and span offset of the table, various advanced techniques are used to ensure that the merged tables keep the original semantics and structure of the data.
Enhances LLM table comprehension: Markdown format provides a simple way to create and format tables, making it easier for LLM to read and understand the data in the tables. This solution merges the tables in the markdown output, further enhancing LLM’s ability to handle tabular data.
Streamlines data processing: Whether you need to process many documents or have high requirements for data processing, through this solution, the process of analyzing and working with the data will be simplified.
Conclusion
This solution provides a flexible and customizable solution for identifying and merging cross-page tables. Users can tailor the rules to fit their specific scenario and requirements, making it a highly versatile tool for handling documents with multiple page tables.
Get started
Merging tables: This sample notebook demonstrates how to use the output of Layout model and some business rules to identify cross-page tables. You can also run this corresponding python file. Once identified, it will be processed to merge these tables and keep the semantics of a table.
Applying to RAG: You can further integrate the merged markdown table with LangChain’s MarkdownHeaderTextSplitter.
Step1: Store the markdown output of the fused table as a file in .md format.
Step2: Replace the ‘Load a document and split it into semantic chunks’ section with the following code snippet and replace <path to your file> with the path to the file you stored in step 1.
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
file_path = “<path to your file>”
with open(file_path, ‘r’, encoding=’utf-8′) as file:
markdown_text = file.read()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
(“#”, “Header 1”),
(“##”, “Header 2”),
(“###”, “Header 3”),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = markdown_text
splits = text_splitter.split_text(docs_string)
print(“Length of splits: ” + str(len(splits)))
This enriched output allows for a more detailed understanding of the data. When used in conjunction with the RAG sample notebook, the markdown output becomes an even more effective tool, enabling more accurate and informed document-based Q&A interactions. Give it a try and discover how it can improve your data processing experience.
Microsoft Tech Community – Latest Blogs –Read More

Controlling AKS egress using an HTTP Proxy
If you are more comfortable with video content type, I have created one for you. It is available on Youtube.
The source code and templates are available in this Github repository: https://github.com/HoussemDellai/docker-kubernetes-course/tree/main/67_egress_proxy
# (Specify the mitm domain as Common Name, e.g. *.google.com or for all: *)
openssl req -new -x509 -key cert.key -out mitmproxy-ca-cert.pem
cat cert.key mitmproxy-ca-cert.pem > mitmproxy-ca.pem
openssl pkcs12 -export -inkey cert.key -in mitmproxy-ca-cert.pem -out mitmproxy-ca-cert.p12
cat mitmproxy-ca-cert.pem | base64 -w0
# sample output
# LS0tLS1CRUdJTiB……..0VSVElGSUNBVEUtLS0tLQo=
#!/bin/bash
# 1. install MITM proxy from official package
wget https://downloads.mitmproxy.org/10.2.4/mitmproxy-10.2.4-linux-x86_64.tar.gz
tar -xvf mitmproxy-10.2.4-linux-x86_64.tar.gz
# [Other option] install MITM proxy using Python pip
# sudo apt install python3-pip -y
# pip3 install mitmproxy
# sudo apt install wget -y # install if not installed
# MITM proxy can create a certificate for us on starting, but we will use our own certificate
# 2. download the certificate files
wget ‘https://raw.githubusercontent.com/HoussemDellai/docker-kubernetes-course/main/_egress_proxy/certificate/mitmproxy-ca-cert.pem’
wget ‘https://raw.githubusercontent.com/HoussemDellai/docker-kubernetes-course/main/_egress_proxy/certificate/mitmproxy-ca.pem’
wget ‘https://raw.githubusercontent.com/HoussemDellai/docker-kubernetes-course/main/_egress_proxy/certificate/mitmproxy-ca-cert.p12’
# 3. start MITM proxy with the certificate and expose the web interface
./mitmweb –listen-port 8080 –web-host 0.0.0.0 –web-port 8081 –set block_global=false –certs *=./mitmproxy-ca.pem –set confdir=./
“httpProxy”: “http://20.73.245.90:8080/”,
“httpsProxy”: “https://20.73.245.90:8080/”,
“noProxy”: [ “localhost”, “127.0.0.1”, “docker.io”, “docker.com” ],
“trustedCA”: “LS0tLS1CRUdJTiBD……….Q0VSVElGSUNBVEUtLS0tLQo=”
}
terraform plan -out tfplan
terraform apply tfplan
kubectl exec -it nginx — env
# http_proxy=http://10.0.0.4:8080/
# HTTP_PROXY=http://10.0.0.4:8080/
# https_proxy=https://10.0.0.4:8080/
# HTTPS_PROXY=https://10.0.0.4:8080/
# no_proxy=localhost,aks-8v0n0swv.hcp.westeurope.azmk8s.io,10.10.0.0/24,10.0.0.0/16,169.254.169.254,docker.com,127.0.0.1,docker.io,konnectivity,10.10.0.0/16,168.63.129.16
# NO_PROXY=localhost,aks-8v0n0swv.hcp.westeurope.azmk8s.io,10.10.0.0/24,10.0.0.0/16,169.254.169.254,docker.com,127.0.0.1,docker.io,konnectivity,10.10.0.0/16,168.63.129.16
kubectl exec -it nginx — ‘curl ifconf.me’
# 20.134.24.9 # this is VM’s public IP used by Proxy
# NAME STATUS ROLES AGE VERSION
# aks-systempool-48300357-vmss000000 Ready <none> 11m v1.29.0
# aks-systempool-48300357-vmss000001 Ready <none> 11m v1.29.0
# aks-systempool-48300357-vmss000002 Ready <none> 11m v1.29.0
kubectl debug node/aks-systempool-48300357-vmss000000 -it –image=ubuntu
root@aks-systempool-48300357-vmss000000:/# chroot /host
env
# http_proxy=http://10.0.0.4:8080/
# HTTP_PROXY=http://10.0.0.4:8080/
# https_proxy=https://10.0.0.4:8080/
# HTTPS_PROXY=https://10.0.0.4:8080/
# no_proxy=localhost,aks-8v0n0swv.hcp.westeurope.azmk8s.io,10.10.0.0/24,10.0.0.0/16,169.254.169.254,docker.com,127.0.0.1,docker.io,konnectivity,10.10.0.0/16,168.63.129.16
# NO_PROXY=localhost,aks-8v0n0swv.hcp.westeurope.azmk8s.io,10.10.0.0/24,10.0.0.0/16,169.254.169.254,docker.com,127.0.0.1,docker.io,konnectivity,10.10.0.0/16,168.63.129.16
# … removed for brievety
kind: Pod
metadata:
name: nginx-noproxy
annotations:
“kubernetes.azure.com/no-http-proxy-vars”: “true”
spec:
containers:
– image: nginx
name: nginx
kubectl apply -f noproxy-pod.yaml
kubectl exec -it nginx-noproxy — env
# PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
# HOSTNAME=nginx-noproxy
# NGINX_VERSION=1.25.4
# NJS_VERSION=0.8.3
# PKG_RELEASE=1~bookworm
# KUBERNETES_PORT=tcp://10.0.0.1:443
# KUBERNETES_PORT_443_TCP=tcp://10.0.0.1:443
# KUBERNETES_PORT_443_TCP_PROTO=tcp
# KUBERNETES_PORT_443_TCP_PORT=443
# KUBERNETES_PORT_443_TCP_ADDR=10.0.0.1
# KUBERNETES_SERVICE_HOST=10.0.0.1
# KUBERNETES_SERVICE_PORT=443
# KUBERNETES_SERVICE_PORT_HTTPS=443
# TERM=xterm
# HOME=/root
kubectl exec -it nginx-noproxy — curl ifconf.me
# 4.245.123.106 # this is cluster LB
The sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
Microsoft Tech Community – Latest Blogs –Read More

odt Template editing
I have created an outlook template that we use to publicize our releases. It works well except for the fact that it inserts a second subheading that appears in the email preview. I cannot find a way to edit it through the UI, and if I use an external piece of software the file becomes corrupted.
Is there a way to edit an odt file saved in my templates directory to remove this item.
The image below shows how the email is displayed in the outlook list – I am happy with the sender name and email subject, but I cannot change the ‘subhead sentence here’ text.
I have created an outlook template that we use to publicize our releases. It works well except for the fact that it inserts a second subheading that appears in the email preview. I cannot find a way to edit it through the UI, and if I use an external piece of software the file becomes corrupted.Is there a way to edit an odt file saved in my templates directory to remove this item.The image below shows how the email is displayed in the outlook list – I am happy with the sender name and email subject, but I cannot change the ‘subhead sentence here’ text. Read More

MSSQL – Shrinking database to minimum available size doesn’t work
Hello Community,
Im having a really hard time getting the mssql database file shrinked to minimum available size that SSMS shows in GUI. I really need help and explanation because it’s not relevant on any tech forum I found about it.
My issue is that I want to shrink db data file and in GUI, the minimum size of the file is 2314MB.
I apply the shrink – it does nothing. The db file still remains the same and I can repeat the process forever and nothing will happen to file.
Im looking for a good explanation of this behaviour as tried lot of different methods found on the internet and I can’t make this shrink to happen.
Best regards, Paweł
Hello Community,Im having a really hard time getting the mssql database file shrinked to minimum available size that SSMS shows in GUI. I really need help and explanation because it’s not relevant on any tech forum I found about it.My issue is that I want to shrink db data file and in GUI, the minimum size of the file is 2314MB.I apply the shrink – it does nothing. The db file still remains the same and I can repeat the process forever and nothing will happen to file.Im looking for a good explanation of this behaviour as tried lot of different methods found on the internet and I can’t make this shrink to happen.Best regards, Paweł Read More
If MS can provide Japanese version’s Copilot Success Kit?
When I downloaded the Copilot Success Kit, I confirmed that it is in English.
We would also like to know if it is possible to download the data in Japanese and when it will be available for download. Thank you.
When I downloaded the Copilot Success Kit, I confirmed that it is in English.We would also like to know if it is possible to download the data in Japanese and when it will be available for download. Thank you. Read More
“The page you are looking for can’t be found” when trying to access Microsoft reflect results
I have successfully used Microsoft Reflect in the past within a browser, but recently I am receiving an error that states “The page you are looking for can’t be found”. I have updated my browser, cleared cache, and restarted, and still receiving the error. Any help is appreciated. Thanks!!
I have successfully used Microsoft Reflect in the past within a browser, but recently I am receiving an error that states “The page you are looking for can’t be found”. I have updated my browser, cleared cache, and restarted, and still receiving the error. Any help is appreciated. Thanks!! Read More
Exchange Outlook Mobile App “Unable to Login”
If you’re having issues with the app and your exchange email. More than likely you will have to delete/uninstall the app off of your mobile device. Make sure if you’re using iPhone, delete it off the device not just the home screen. Once deleted, reinstall it and try re-adding your account again.
My issue was that it seemed to cache something and the password I would try to update would not let me login. It would prompt me “Unable to login” check email and password and try again. I tried about all other trouble shooting attempts and this was the only solution that solved it.
Hope this helps some others as well!
TJ
If you’re having issues with the app and your exchange email. More than likely you will have to delete/uninstall the app off of your mobile device. Make sure if you’re using iPhone, delete it off the device not just the home screen. Once deleted, reinstall it and try re-adding your account again. My issue was that it seemed to cache something and the password I would try to update would not let me login. It would prompt me “Unable to login” check email and password and try again. I tried about all other trouble shooting attempts and this was the only solution that solved it. Hope this helps some others as well! TJ Read More
Image column url rest api
Experts,
I am unable to get the url of image column in rest api call, below is the response.
<?xml version=”1.0″ encoding=”utf-8″?><entry xml:base=”https://abc.sharepoint.com/sites/mysite/_api/” xmlns=”http://www.w3.org/2005/Atom” xmlns:d=”http://schemas.microsoft.com/ado/2007/08/dataservices” xmlns:m=”http://schemas.microsoft.com/ado/2007/08/dataservices/metadata” xmlns:georss=”http://www.georss.org/georss” xmlns:gml=”http://www.opengis.net/gml” m:etag=”"3"”><id>16788cd9-78cd-4e7e-b7fe-c38c692a64e7</id><category term=”SP.Data.ProductsListItem” scheme=”http://schemas.microsoft.com/ado/2007/08/dataservices/scheme” /><link rel=”edit” href=”Web/Lists(guid’494a9654-98df-49c4-9b00-78803319cdf7′)/Items(1)” /><title /><updated>2024-04-22T14:17:23Z</updated><author><name /></author><content type=”application/xml”><m:properties><d:Picture>{“fileName”:”Reserved_ImageAttachment_[7]_[Picture][17]_[103567_ikea_black][1]_[1].png”}</d:Picture></m:properties></content></entry>
Experts, I am unable to get the url of image column in rest api call, below is the response.<?xml version=”1.0″ encoding=”utf-8″?><entry xml:base=”https://abc.sharepoint.com/sites/mysite/_api/” xmlns=”http://www.w3.org/2005/Atom” xmlns:d=”http://schemas.microsoft.com/ado/2007/08/dataservices” xmlns:m=”http://schemas.microsoft.com/ado/2007/08/dataservices/metadata” xmlns:georss=”http://www.georss.org/georss” xmlns:gml=”http://www.opengis.net/gml” m:etag=”"3"”><id>16788cd9-78cd-4e7e-b7fe-c38c692a64e7</id><category term=”SP.Data.ProductsListItem” scheme=”http://schemas.microsoft.com/ado/2007/08/dataservices/scheme” /><link rel=”edit” href=”Web/Lists(guid’494a9654-98df-49c4-9b00-78803319cdf7′)/Items(1)” /><title /><updated>2024-04-22T14:17:23Z</updated><author><name /></author><content type=”application/xml”><m:properties><d:Picture>{“fileName”:”Reserved_ImageAttachment_[7]_[Picture][17]_[103567_ikea_black][1]_[1].png”}</d:Picture></m:properties></content></entry> Read More
Column totals, with exceptions and equal to current/next month
Hi
I have tried SUMIFS and SUMPRODUCTS but still cannot get this to work, and have tried MS community.
I have a report that contains annual finance data and i am trying to produce a dashboard. I have developed most of this, with the exception of it being able to extract for forecast for the current and next month.
I have added a table below, and fingers crossed this makes sense.
I want to be able to write formula that will extract the current months data, this month is in a cell. So it is currently April, i want to extract Apr and May into different cells on the dashboard. When it is May, i want to extract May and Jun into set cells in the dashboard.
The dashboard is broken down into Option A, B, C etc and the task codes also have 6 in total that i do not want to calculate so to only count the colum for the month, and sum the options, but exclude set tasks.
NameTaskAprMayJunOption A2.1£1.12£1.13£1.14Option A2.2£1.24£1.25£1.26Option A9.1
£1
£1£1Option B2.1
£1.32
£1.33£1.34Option B2.2£1.40£1.41£1.42Option B9.1
£1
£1£1Option C2.1£1.41£1.42£1.43Option C2.2£1.42£1.43£1.44Option C9.1
£1
£1£1
I hope this makes sense, thank you all
HiI have tried SUMIFS and SUMPRODUCTS but still cannot get this to work, and have tried MS community. I have a report that contains annual finance data and i am trying to produce a dashboard. I have developed most of this, with the exception of it being able to extract for forecast for the current and next month. I have added a table below, and fingers crossed this makes sense. I want to be able to write formula that will extract the current months data, this month is in a cell. So it is currently April, i want to extract Apr and May into different cells on the dashboard. When it is May, i want to extract May and Jun into set cells in the dashboard. The dashboard is broken down into Option A, B, C etc and the task codes also have 6 in total that i do not want to calculate so to only count the colum for the month, and sum the options, but exclude set tasks.NameTaskAprMayJunOption A2.1£1.12£1.13£1.14Option A2.2£1.24£1.25£1.26Option A9.1£1£1£1Option B2.1£1.32£1.33£1.34Option B2.2£1.40£1.41£1.42Option B9.1£1£1£1Option C2.1£1.41£1.42£1.43Option C2.2£1.42£1.43£1.44Option C9.1£1£1£1 I hope this makes sense, thank you all Read More

Formula Help
I need help writing a formula in column L. The calculation for L4 is simply the sum of J4=K4. My question is what formula can I use in L column that will only use the K4 result if J4 is blank? Then if J4 has a value, the L column would go back to the sum of J4 and K4. You can see that I couldn’t figure out how to sum the values in L5 and the result shows up as FALSE.
I need help writing a formula in column L. The calculation for L4 is simply the sum of J4=K4. My question is what formula can I use in L column that will only use the K4 result if J4 is blank? Then if J4 has a value, the L column would go back to the sum of J4 and K4. You can see that I couldn’t figure out how to sum the values in L5 and the result shows up as FALSE. Read More

EICAR file is not blocked by Defender for Endpoint on Linux
Hello,
we are testing Microsoft Defender for Endpoint on Linux Ubuntu devices.
I successfully onboarded machine, it is visible in Defender portal and I am able to generate incident using test https://aka.ms/LinuxDIY
However, I am not able to detect/block EICAR test file using suggested command:
curl -o ~/Downloads/eicar.com.txt https://www.eicar.org/download/eicar.com.txt
After it, eicar.com.txt file is in Downloads folder and nothing happens.
“mdatp health” output:
Configuration in mdatp_managed.json file:
Am I missing something?
Thanks
Hello,we are testing Microsoft Defender for Endpoint on Linux Ubuntu devices.I successfully onboarded machine, it is visible in Defender portal and I am able to generate incident using test https://aka.ms/LinuxDIY However, I am not able to detect/block EICAR test file using suggested command:curl -o ~/Downloads/eicar.com.txt https://www.eicar.org/download/eicar.com.txt After it, eicar.com.txt file is in Downloads folder and nothing happens. “mdatp health” output:Configuration in mdatp_managed.json file: Am I missing something? Thanks Read More

Display iFrame in Body of Sharepoint Form
Not sure if this is possible. If I have an iFrame embed code for a document in a sharepoint library, can I render that iframe in the body of Sharepoint list form? Is there an elmtype that would work? Code samples desperately welcome.
Not sure if this is possible. If I have an iFrame embed code for a document in a sharepoint library, can I render that iframe in the body of Sharepoint list form? Is there an elmtype that would work? Code samples desperately welcome. Read More
Microsoft Events RSAConference 2024
Join us at the Microsoft Security Leaders Lounge at RSAC
Are you gearing up for RSAC 2024? As the excitement builds for this year’s cybersecurity event in San Francisco, California, we at Microsoft have some exciting news to share! Whether you’re a seasoned veteran or a first-time attendee, make sure to mark your calendars and join us at the Microsoft Security Leaders Lounge. We have a lineup of compelling events planned, including an executive panel on threat intelligence, discussions on AI safety, insights into Zero Trust for AI learning, and much more. These are just a few of the topics we’ll explore at the Microsoft Security Hub @ the Palace Hotel. Don’t miss out on these opportunities to network, learn, and engage with industry experts.
Join us for various sessions from May 6th to May 8th and select the session that best fits your interests. You can find several sessions listed below and we look forward to seeing you there!
Threat intelligence trends and insights breakfast panel
Hear from our Microsoft Threat Intelligence panel of experts: Sherrod DeGrippo, Amy Hogan-Burney, Fanta Orr, and Jeremy Dallman as they share insights on the threats, they are seeing from analyzing 78 trillion signals daily and learn how to stay ahead of ransomware, social engineering, nation state attacks, and cyber influence operations.
(May 7th, 8:00AM – 9:15AM)
AI safety executive fireside chat luncheon
Join the fireside chat on AI safety with Sarah Bird, Chief Product Officer of Responsible AI and Bret Arsenault, Chief Cybersecurity Advisor where we’ll address CISOs top AI concerns, the importance of responsible AI, and Microsoft’s commitment to AI safety. Walk away with practical guidance on implementing AI safely in your organization.
(May 7th, 12:00PM – 1:30PM)
Zero Trust for AI learning session
Join our session tailored for security leaders to learn about how you can leverage Zero Trust principles for securing AI. This session will give you practical guidance and help you with your deployment of AI solutions in your organization. Stay afterwards to get a free copy of the Zero Trust Playbook signed by author and presenter Mark Simos.
(May 7th, 2:30PM-3:15PM)
Become the threat Workshop at RSAC 2024: Design your own attack leveraging social engineering
Gain insight into a threat actor’s mindset, crafting threat campaigns through social engineering and technical tactics, enhancing strategic cybersecurity understanding and defense strategies for executives. Join Sherrod DeGrippo for this exclusive session and walk away with your own threat campaign (but don’t use it).
(May 8th, 8:00AM – 9:30AM)
Learn more about these sessions and sign up for one or more
Microsoft Tech Community – Latest Blogs –Read More
The new Microsoft Planner: New task features for organizations with frontline workers
Earlier this month we announced that the new Microsoft Planner has begun rolling out to General Availability. As part of the new Planner, we’re enhancing task publishing, a feature designed to increase clarity for frontline workers about what work is required and increase visibility for the organization on how that work is going. More specifically, we’re releasing four new features based on the top requests we’ve received across frontline organizations. We’re happy to report that these new capabilities have started rolling out as part of the new Planner:
1. Assign training and policy tasks to frontline employees (task list for each team member)
2. Automatically send repeat tasks to frontline locations (task list recurrence)
3. Make it mandatory to provide input back to the org (form completion requirement)
4. Make it mandatory to get approval for work completed (approval completion requirement)
These features are being enabled for users who have the new Planner experience, so it is expected that not everyone will see them immediately. The approval completion requirement is coming soon to the new Planner, and the three other features are available today in the new Planner experience. You’ll find them within the task publishing experience.
Task publishing support for training and policy tasks
Task publishing allows central leaders to create a list of tasks, distribute those tasks to multiple locations, and monitor execution across locations.
One of the top requests has been the ability for organizations to publish tasks that each employee at a frontline location must complete – for example, to send training tasks or new policy acknowledgment tasks to all team members at designated frontline locations.
This feature will appear in task publishing as a new type of task list for each team member. When publishing a task list for each team member, you can select the locations that should receive the task list, as usual. Once you confirm the locations, a copy of each task in the list will be created for every employee at each of the chosen locations. When these tasks are created for each employee, they’ll be created in a plan for the specific employee rather than the plan for the team. Once the list has been published, you’ll have access to simple reporting to monitor completion.
Task publishing demo showing the menu for creating a new list, which now has two options: For each team and For each team member.
Task list recurrence
Another top feature request has been making it easier to manage recurring tasks across frontline locations, such as tasks for completion of regular site inspections and compliance walks.
With task list recurrence, you’ll be able to apply a recurrence pattern to a task list, with options for daily, weekly, monthly, or yearly intervals. Once you publish a recurring list, task publishing will take care of scheduling all future publications of those tasks, so the list automatically publishes at the specified cadence going forward. From a wide range of customer conversations, we know this will be a big timesaver for distributing repeat tasks across frontline locations. Once the recurring task list is scheduled to publish, central teams will have less to manage when distributing the tasks to frontline locations, making it easier for the org to ensure the right work is completed on time at the right places.
Demo of list recurrence choices for a list. We choose a monthly cadence for this list.
Form or survey completion requirement
We’re also introducing two new completion requirements, which enable your organization to ensure the right steps are taken before the task can be marked complete.
The first new completion requirement is the form completion requirement, an integration with Microsoft Forms. When you use task publishing to create a task, you’ll have an option to add a requirement for completion of a designated form. When you publish that task, each recipient team will be unable to mark the task complete until a form response is submitted by a member of that team.
As with any form you create via Microsoft Forms, you have a range of options on the types of questions you can include. You can ask for a text response or ask respondents to select from multiple choices. You can also require a file upload, so that each recipient team must share a photo of the completed work, if you so choose. What’s more, you can use conditional branching to make additional questions appear or not appear based on the answers provided. For example, if a user chooses an answer that indicates non-compliance with a company policy, you can ask the user follow-up questions to collect additional details. That’s one more way form completion requirements make it easier to get information back from your frontline teams.
Demo of the form completion requirement
Approval completion requirement
You’ll also soon have access to approval completion requirements, an integration with Microsoft Approvals. When you use task publishing to create a task, you’ll be able to designate that an approval is a prerequisite for a task to be marked complete. When you publish that task, each recipient team will be unable to mark the task complete until an approval is requested and subsequently granted.
A user on the recipient team who opens the task will be able to choose the appropriate person on the team to request their approval. The names of the requestor and the designated approver are reflected in the task details, so other members of the team can see the status and help facilitate the approval of the work. This will make it easier to heighten accountability of recipient teams for important tasks your org needs them to complete.
Demo of the approval completion requirement
Task publishing demo video
Watch the full video below to see an overview of task publishing as a whole, including other features we’ve previously rolled out, such as checklist completion requirements, text formatting in the notes fields, our new API capabilities for advanced reporting, and improved options for Teams activity feed notifications.
Video overview of task publishing, including these new features
Additional resources:
• Learn how to setup task publishing by creating a team hierarchy
• Read the blog post announcing that rollout of the new Planner to General Availability has begun
• Watch the new Planner demo videos for inspiration on how to get the most out of the new Planner app in Microsoft Teams.
Microsoft Tech Community – Latest Blogs –Read More
Public Preview of Edge Storage Accelerator
Release Summary
We are thrilled to announce the Limited Public Preview of Edge Storage Accelerator (ESA), a 1P storage system designed for Arc-connected Kubernetes clusters. ESA is a cloud-native persistent storage service that provides fault-tolerance and high availability for Kubernetes clusters hosting stateful applications such as Azure IoT Operations, homegrown apps, and other Arc Extensions. Use standard Kubernetes APIs to easily attach any containerized application handling file data to Azure Blob storage. Leverage the unlimited cloud storage capacity of Azure Blob for applications running at the edge. With flexible deployment options, simplicity in connection through a CSI driver, and platform neutrality validated across various Arc Kubernetes platforms, ESA transforms the landscape of edge storage solutions.
Highlights
Simple App Connection: Seamlessly connect your application pod to an ESA volume using our CSI driver to provision Persistent Volumes pointing at your Azure Blob Storage.
Easy to Integrate: The ESA integrates with Azure IoT Operations Data Processor using standard Kubernetes APIs, simplifying the uploading of edge-originating data to Azure.
Platform Flexibility: ESA is an Arc Kubernetes container-native storage solution compatible with any Arc Kubernetes-supported platform. Validation has been conducted for specific platforms including Ubuntu + CNCF K3s/K8s, Windows IoT + AKS-EE, and Azure Stack HCI + AKS-HCI.
File Synchronization to Azure: ESA automatically syncs files written at the edge to a storage account and container target, allowing automatic tiering to Azure Blob (block blob, ADLSgen-2) in the cloud.
“Local Latency” Operations: Experience local latency for read and write operations, ensuring an optimal experience for Arc services, including Azure IoT Operations.
Fault-Tolerance: ESA, when configured on a 3-node (or larger) cluster, ensures data replication between nodes (triplication), providing high availability and resiliency to single node failures.
Observable: ESA supports industry-standard Kubernetes monitoring logs and metrics facilities. ESA will also support Azure Monitor Agent, providing insights into system performance.
Impact of “Limited” on Public Preview
No Azure Update: There will be no official Azure Update post for the public announcement.
Publication of Microsoft Documents: Microsoft will publish the relevant documentation on its official channels. These documents are available today and can be found here.
Request to Access Preview: Because we still want to learn about customers use-cases and environments, we request that those that are interested complete this questionnaire prior to being allow-listed. Once your response has been submitted, one of the ESA PMs will get in touch with you!
ESA Jumpstart Scenario
Edge Storage Accelerator has collaborated with the Arc Jumpstart team to implement a scenario where a computer vision AI model detects defects in bolts by analyzing video from a supply line video feed streamed over RTSP. The identified defects are then stored in a container within a storage account using ESA.
In this automated setup, ESA is deployed on an AKS Edge Essentials single-node running in an Azure virtual machine. An ARM template is provided to create the necessary Azure resources and configure the LogonScript.ps1 custom script extension. This extension handles AKS Edge Essentials cluster creation, Azure Arc onboarding for the Azure VM and AKS Edge Essentials cluster, and Edge Storage Accelerator deployment. Once AKS Edge Essentials is deployed, ESA is installed as a Kubernetes service that exposes a CSI driven storage class for use by applications in the Edge Essentials Kubernetes cluster.
If you’re interested in learning more:
Visit the ESA Jumpstart documentation to try it yourself!
Check out the ESA Jumpstart Architecture Diagrams
Try Out ESA Today!
🧪 For access to the preview, please complete this questionnaire about your environment and use-case(s). We want to provide assurance that our customers will be successful in their testing! Once you have submitted your responses, one of the ESA PMs will get back to you with an update on your request! Please note that this preview is NOT to be used for production workloads/use-cases.
If you have already participated in the Edge Storage Accelerator Private Preview, you do not need to complete another questionnaire as you have already been allow-listed. Edge Storage Accelerator Public Preview documentation can be found here.
🪲 If you found a bug or have an issue, please complete the Edge Storage Accelerator Request Support Form.
Microsoft Tech Community – Latest Blogs –Read More

Unable to get compression on IIS
Hello, spend I am not sure how many hours on this one and was hoping to get some advice on what I may have missed. I follow the directions given to us by Microsoft which are https://learn.microsoft.com/en-us/iis/extensions/iis-compression/iis-compression-overview which has resulted still in no compression mention when performing API request on Web Services in Business Central.
I’ll add a few images to show the Dynamic Compression has been enabled. The two compression package specifically GZIP and BR from the documentation has been downloaded and added. I wonder if there is something that have been missed to allow approval for compression or any direction to truly check if it’s being compressed but possible fillers when returning is showing something different.
Thank you for all help on this matter or any point in direction
Hello, spend I am not sure how many hours on this one and was hoping to get some advice on what I may have missed. I follow the directions given to us by Microsoft which are https://learn.microsoft.com/en-us/iis/extensions/iis-compression/iis-compression-overview which has resulted still in no compression mention when performing API request on Web Services in Business Central. I’ll add a few images to show the Dynamic Compression has been enabled. The two compression package specifically GZIP and BR from the documentation has been downloaded and added. I wonder if there is something that have been missed to allow approval for compression or any direction to truly check if it’s being compressed but possible fillers when returning is showing something different. Thank you for all help on this matter or any point in direction Read More
Copy Activity from BLOB CSV to C4C OData Services failes on csrf token
HI There ,
1)when trying to get data from C4C to blob using adf we were able to extract data with out any issues .
2)when trying insert the downloaded file back to C4C connection ( sap/c4c/odata/v1/c4codataapi/) using copy Activity in ADF , confronting an issues with Csrf token not supported for the odata endpoint. can you please provide me how to resolve this conflict.
NOTE: the user has sufficient permissions to insert data
error LOG:
“errors”: [
{
“Code”: 23208,
“Message”: “ErrorCode=ODataCsrfTokenNotSupported,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Csrf token not supported for the odata endpoint.,Source=Microsoft.DataTransfer.Runtime.ODataConnector,‘”,
“EventType”: 0,
“Category”: 5,
“Data”: {},
“MsgId”: null,
“ExceptionType”: null,
“Source”: null,
“StackTrace”: null,
“InnerEventInfos”: []
}
HI There , 1)when trying to get data from C4C to blob using adf we were able to extract data with out any issues . 2)when trying insert the downloaded file back to C4C connection ( sap/c4c/odata/v1/c4codataapi/) using copy Activity in ADF , confronting an issues with Csrf token not supported for the odata endpoint. can you please provide me how to resolve this conflict. NOTE: the user has sufficient permissions to insert data error LOG:”errors”: [{“Code”: 23208,”Message”: “ErrorCode=ODataCsrfTokenNotSupported,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Csrf token not supported for the odata endpoint.,Source=Microsoft.DataTransfer.Runtime.ODataConnector,'”,”EventType”: 0,”Category”: 5,”Data”: {},”MsgId”: null,”ExceptionType”: null,”Source”: null,”StackTrace”: null,”InnerEventInfos”: []} Read More







