

Next-Gen Customer Service: Azure’s AI-Powered Speech, Translation and Summarization
Active Azure subscription. If you don’t have an Azure subscription, you can create one for free
Create a Speech resource in the Azure portal.
Create a Translator resource in the Azure portal.
Create a Language resource in the Azure portal
Create a Container Registry in the Azure portal.
Create Azure Web PubSub for Socket.IO resource using
NODE_ENV=’development’
PORT=3000
SOCKET_PORT=29011
SOCKET_ENDPOINT=https://<SOCKET_IO_SERVICE>.webpubsub.azure.com
SOCKET_CONNECTION_STRING=<SOCKET_IO_CONNECTION_STRING>
SPEECH_KEY=<SPEECH_KEY>
SPEECH_REGION=westeurope
LANGUAGE_KEY=<LANGUAGE_KEY>
LANGUAGE_REGION=westeurope
LANGUAGE_ENDPOINT=https://<LANGUAGE_SERVICE>.cognitiveservices.azure.com/
TRANSLATE_KEY=<TRANSLATE_KEY>
TRANSLATE_ENDPOINT=https://api.cognitive.microsofttranslator.com/
TRANSLATE_REGION=westeurope
LOCATION=westeurope
CONTAINER_APP_NAME=aiservices
CONTAINER_APP_IMAGE=<CONTAINER_REGISTRY>.azurecr.io/aiservices:latest
CONTAINER_APP_PORT=80
CONTAINER_REGISTRY_SERVER=<CONTAINER_REGISTRY>.azurecr.io
CONTAINER_REGISTRY_IDENTITY=system
CONTAINER_ENVIRONMENT_NAME=env-ai-services
LOGS_WORKSPACE_ID=<LOGS_WORKSPACE_ID>
LOGS_WORKSPACE_KEY=<LOGS_WORKSPACE_KEY>
SUBSCRIPTION_ID=<SUBSCRIPTION_ID>
“clientId”: “00000000-0000-0000-0000-000000000000”,
“clientSecret”: “00000000000000000000000000000000”,
“subscriptionId”: “00000000-0000-0000-0000-000000000000”,
“tenantId”: “00000000-0000-0000-0000-000000000000”,
“activeDirectoryEndpointUrl”: “https://login.microsoftonline.com”,
“resourceManagerEndpointUrl”: “https://management.azure.com/”,
“activeDirectoryGraphResourceId”: “https://graph.windows.net/”,
“sqlManagementEndpointUrl”: “https://management.core.windows.net:8443/”,
“galleryEndpointUrl”: “https://gallery.azure.com/”,
“managementEndpointUrl”: “https://management.core.windows.net/”
}
Set the CONTAINER_REGISTRY variable to the name of the Azure Container Registry.
Set the RESOURCE_GROUP variable for the resource group where you Container registry.
Set the CONTAINER_APP_NAME variable to the name of the Azure Container App.
npm install
npm run dev
./setup.sh
–name $CONTAINER_APP_NAME
–resource-group $RESOURCE_GROUP
–query properties.configuration.ingress.fqdn
Spoken language: Select the language of the speaker.
Translated language: Select the language to which the spoken language will be translated.
Listen: Start the speech-to-text transcription, this will use the Speech to text SDK for JavaScript package.
// intialize the speech recognizer
const speechConfig = speechsdk.SpeechConfig.fromAuthorizationToken(tokenObj.token, tokenObj.region);
const audioConfig = speechsdk.AudioConfig.fromDefaultMicrophoneInput();
recognizer = new speechsdk.SpeechRecognizer(speechConfig, audioConfig);
// register the event handlers
…
// listen and transcribe
recognizer.startContinuousRecognitionAsync();
// stop the speech recognizer
recognizer.stopContinuousRecognitionAsync();
…
const res = await axios.post(`${config.translateEndpoint}translate?api-version=3.0&from=${from}&to=${to}`, data, headers);
return res.data[0].translations[0].text;
const jobId = res.headers[‘operation-location’];
let completed = false
while (!completed) {
res = await axios.get(`${jobId}`, headers);
completed = res.data.tasks.completed > 0;
}
const conv = res.data.tasks.items[0].results.conversations[0].summaries.map(summary => {
return { aspect: summary.aspect, text: summary.text }
});
return conv;
// intialize the speech synthesizer
speechConfig.speechSynthesisVoiceName = speakLanguage;
const synthAudioConfig = speechsdk.AudioConfig.fromDefaultSpeakerOutput();
synthesizer = new speechsdk.SpeechSynthesizer(speechConfig, synthAudioConfig);
…
// speak the text
synthesizer.speakTextAsync(text,
function (result) {
if (result.reason === speechsdk.ResultReason.SynthesizingAudioCompleted) {
console.log(“synthesis finished.”);
} else {
console.error(“Speech synthesis canceled, ” + result.errorDetails +
“nDid you set the speech resource key and region values?”);
}
});
clearMessages = () =>
socket.emit(‘clear’);
syncMessages = () =>
socket.emit(‘sync’);
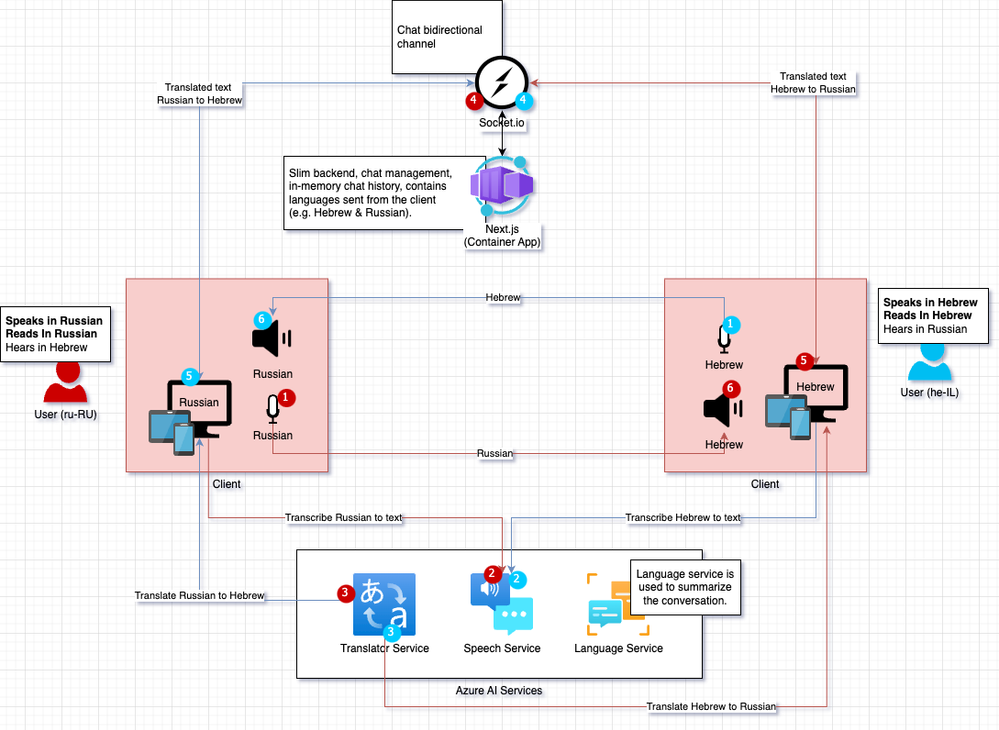
Container Registry: for the Next.js app container image.
Container App (& Container App Environment): for the Next.js app.
Language Service: for the conversation summarization.
Log Analytics Workspace: for the logs of the container app.
Web PubSub for Socket.IO: for the real-time, duplex communication between the client and the server.
Speech service: for the speech-to-text transcription capabilities.
Translator service: for the translation capabilities.
Create a project and choose a model. Use a Speech resource that you create in the Azure portal. If you train a custom model with audio data, choose a Speech resource region with dedicated hardware for training audio data. For more information, see footnotes in the regions table.
Upload test data. Upload test data to evaluate the speech to text offering for your applications, tools, and products.
Test recognition quality. Use the Speech Studio to play back uploaded audio and inspect the speech recognition quality of your test data.
Test model quantitatively. Evaluate and improve the accuracy of the speech to text model. The Speech service provides a quantitative word error rate (WER), which you can use to determine if more training is required.
Train a model. Provide written transcripts and related text, along with the corresponding audio data. Testing a model before and after training is optional but recommended.
Deploy a model. Once you’re satisfied with the test results, deploy the model to a custom endpoint. Except for batch transcription, you must deploy a custom endpoint to use a custom speech model.
Microsoft Tech Community – Latest Blogs –Read More







