

Category: News
How To Stop Ctrl + Shift + V From Periodically Recalculating All Data Tables
Hi all,
Loving the Ctrl + Shift + V keyboard shortcut; however, I can’t get it to stop recalculating the data tables in my open workbooks.
I have my calculation settings set to “Automatic Except For Data Tables” and ‘Recalculate workbook before saving unchecked.” Is there some setting that I am forgetting or a workaround?
I’ve included screenshots of what I think are the relevant settings.
Thanks!
Hi all, Loving the Ctrl + Shift + V keyboard shortcut; however, I can’t get it to stop recalculating the data tables in my open workbooks. I have my calculation settings set to “Automatic Except For Data Tables” and ‘Recalculate workbook before saving unchecked.” Is there some setting that I am forgetting or a workaround? I’ve included screenshots of what I think are the relevant settings. Thanks! Read More
M365 Adoption User Group – Answers in Viva Deep Dive
Do you have Answers?
I’m excited to have James Tyer (and engineers) from the Microsoft Viva team return to showcase Answers in Viva, including answers in communities and its intelligent importer. Nothing like having direct access to the source! The Microsoft Viva team will also showcase where they are headed with Answers and answer all your questions on both the journey and next steps.
Afterwards, stick around to hear all the latest on what’s new and coming to Microsoft 365 & the ACM space!
Online Teams Meeting Link: https://aka.ms/M365UG
DETAILS
AGENDA:
12:00 – 12:05 Welcome: Kirsty McGrath
12:05 – 12:45 Viva Answers with James Tyer, Microsoft
12:45 – 1:25 What’s New & Coming to Microsoft 365 & ACM
1:25 – 1:30 What’s Next & Close: Kirsty McGrath
BIO:
James is the Senior Program Manager on the Viva Engage & Answers Customer Experience team at Microsoft. He has previously helped launch Yammer & Viva Engage networks for companies such as Coca-Cola and Kellogg’s. James also advises interesting enterprise startups, such as www.soundbite.ai. He regularly presents at conferences and in 2021 had his first book published: Social by Design: How to create and scale a collaborative company
SOCIAL MEDIA:
LinkedIn: https://www.linkedin.com/in/jtyer/
LinkedIn: Kirsty McGrath
X: @M365Adoption, @KirstyMcGrath13,
Facebook: www.facebook.com/Microsoft365Adoption
YouTube: https://aka.ms/M365Adoption or @Microsoft365Adoption
#M365AdoptionUG #M365Adoption #MSFTAdoption #VivaEngage #VivaAnswers
Do you have Answers?
I’m excited to have James Tyer (and engineers) from the Microsoft Viva team return to showcase Answers in Viva, including answers in communities and its intelligent importer. Nothing like having direct access to the source! The Microsoft Viva team will also showcase where they are headed with Answers and answer all your questions on both the journey and next steps.
Afterwards, stick around to hear all the latest on what’s new and coming to Microsoft 365 & the ACM space!
Online Teams Meeting Link: https://aka.ms/M365UG
DETAILS
AGENDA:12:00 – 12:05 Welcome: Kirsty McGrath12:05 – 12:45 Viva Answers with James Tyer, Microsoft12:45 – 1:25 What’s New & Coming to Microsoft 365 & ACM1:25 – 1:30 What’s Next & Close: Kirsty McGrath
BIO:James is the Senior Program Manager on the Viva Engage & Answers Customer Experience team at Microsoft. He has previously helped launch Yammer & Viva Engage networks for companies such as Coca-Cola and Kellogg’s. James also advises interesting enterprise startups, such as www.soundbite.ai. He regularly presents at conferences and in 2021 had his first book published: Social by Design: How to create and scale a collaborative company
SOCIAL MEDIA:LinkedIn: https://www.linkedin.com/in/jtyer/
LinkedIn: Kirsty McGrathX: @M365Adoption, @KirstyMcGrath13,Facebook: www.facebook.com/Microsoft365AdoptionYouTube: https://aka.ms/M365Adoption or @Microsoft365Adoption#M365AdoptionUG #M365Adoption #MSFTAdoption #VivaEngage #VivaAnswers Read More
M365 Adoption User Group – How to run a successful intranet
SWOOP Analytics has analysed the behaviours of more than 177,000 intranet readers across 57,000+ intranet news pages and 37,000+ content pages over 20 organisations to produce its latest SharePoint intranet benchmarking report.
The findings from the report will show exactly how people are using and accessing company intranets. These findings are used to give achievable goals and benchmarks to get more colleagues reading and engaging on your intranet.
SWOOP Analytics’ benchmarking data will give you real-life insights into when people are reading the intranet, what they’re reading on the intranet, how they’re accessing the intranet and how you can best shape your content to get maximum engagement.
Here’s a sneak peek at some of SWOOP’s early findings:
Almost everyone accesses the intranet via their desktop computer, with less than 2% accessing the intranet via their phone and less than 0.2% via a tablet.
Employees spend, on average, almost 15 minutes a day reading the intranet.
However, only about a minute a day, on average, is spent reading intranet news pages.
Join the meetup to learn more from report authors Dr Laurence Lock Lee and Sharon Dawson.
Afterwards, stick around to hear all the latest on what’s new and coming to Microsoft 365 & the ACM space!
Online Teams Meeting Link: https://aka.ms/M365UG
DETAILS
AGENDA:
12:00 – 12:05 Welcome: Kirsty McGrath
12:05 – 12:45 How to run a successful intranet
12:45 – 1:25 What’s New & Coming to Microsoft 365 & ACM
1:25 – 1:30 What’s Next & Close: Kirsty McGrath
BIO:
Dr Laurence Lock Lee, SWOOP Analytics, Chief Data Scientist & Co-founder – Laurence is an experienced professional, with over 40 years’ experience as a researcher, technology leader, educator and management consultant. He is a leading practitioner in Social Network Analysis (SNA) for organisational change, having conducted more than 100 consulting assignments for clients around the world. At SWOOP he is responsible for the science that underpins the SWOOP dashboard measures. He holds a PhD on corporate social capital from the University of Sydney.
Sharon Dawson, SWOOP Analytics, Director, External Relations & Communications – With an impressive career as a journalist covering news, politics, sport and finance for Australian Associated Press and other news organisations, Sharon joined SWOOP to lead our external communication and relationship activities. She has a special talent for bringing to life our customers’ stories and a passion to help customers become better, more effective collaborators.
Emily O’Brien, SWOOP Analytics, Director, Global Operations & APAC – With a background in marketing and communication, Emily has experience in the community management space, previously implementing the internal communication strategy for a large company of 30,000+ field-based employees. Emily is enthusiastic about helping our customers unlock the full value of the collaboration insights available in SWOOP by facilitating training on leadership engagement, running effective groups and communication campaigns.
SOCIAL MEDIA:
Dr. Laurence Lock Lee | LinkedIn
Sharon Dawson (Mathieson) | LinkedIn
Emily O’Brien | LinkedIn
LinkedIn: Kirsty McGrath
X: @M365Adoption, @KirstyMcGrath13,
Facebook: www.facebook.com/Microsoft365Adoption
YouTube: https://aka.ms/M365Adoption or @Microsoft365Adoption
#M365AdoptionUG #M365Adoption #MSFTAdoption #SWOOPAnalytics #Intranet #SharePoint
SWOOP Analytics has analysed the behaviours of more than 177,000 intranet readers across 57,000+ intranet news pages and 37,000+ content pages over 20 organisations to produce its latest SharePoint intranet benchmarking report.The findings from the report will show exactly how people are using and accessing company intranets. These findings are used to give achievable goals and benchmarks to get more colleagues reading and engaging on your intranet.SWOOP Analytics’ benchmarking data will give you real-life insights into when people are reading the intranet, what they’re reading on the intranet, how they’re accessing the intranet and how you can best shape your content to get maximum engagement.Here’s a sneak peek at some of SWOOP’s early findings:
Almost everyone accesses the intranet via their desktop computer, with less than 2% accessing the intranet via their phone and less than 0.2% via a tablet.
Employees spend, on average, almost 15 minutes a day reading the intranet.
However, only about a minute a day, on average, is spent reading intranet news pages.
Join the meetup to learn more from report authors Dr Laurence Lock Lee and Sharon Dawson.
Afterwards, stick around to hear all the latest on what’s new and coming to Microsoft 365 & the ACM space!
Online Teams Meeting Link: https://aka.ms/M365UG
DETAILS
AGENDA:12:00 – 12:05 Welcome: Kirsty McGrath12:05 – 12:45 How to run a successful intranet12:45 – 1:25 What’s New & Coming to Microsoft 365 & ACM1:25 – 1:30 What’s Next & Close: Kirsty McGrath
BIO:Dr Laurence Lock Lee, SWOOP Analytics, Chief Data Scientist & Co-founder – Laurence is an experienced professional, with over 40 years’ experience as a researcher, technology leader, educator and management consultant. He is a leading practitioner in Social Network Analysis (SNA) for organisational change, having conducted more than 100 consulting assignments for clients around the world. At SWOOP he is responsible for the science that underpins the SWOOP dashboard measures. He holds a PhD on corporate social capital from the University of Sydney.
Sharon Dawson, SWOOP Analytics, Director, External Relations & Communications – With an impressive career as a journalist covering news, politics, sport and finance for Australian Associated Press and other news organisations, Sharon joined SWOOP to lead our external communication and relationship activities. She has a special talent for bringing to life our customers’ stories and a passion to help customers become better, more effective collaborators.
Emily O’Brien, SWOOP Analytics, Director, Global Operations & APAC – With a background in marketing and communication, Emily has experience in the community management space, previously implementing the internal communication strategy for a large company of 30,000+ field-based employees. Emily is enthusiastic about helping our customers unlock the full value of the collaboration insights available in SWOOP by facilitating training on leadership engagement, running effective groups and communication campaigns.
SOCIAL MEDIA:Dr. Laurence Lock Lee | LinkedInSharon Dawson (Mathieson) | LinkedInEmily O’Brien | LinkedInLinkedIn: Kirsty McGrathX: @M365Adoption, @KirstyMcGrath13,Facebook: www.facebook.com/Microsoft365AdoptionYouTube: https://aka.ms/M365Adoption or @Microsoft365Adoption#M365AdoptionUG #M365Adoption #MSFTAdoption #SWOOPAnalytics #Intranet #SharePoint Read More
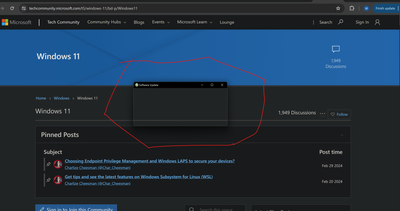
Cannot close “ghost” window, application killed
Please see the image. I had a popup for a software update, I tried to close the window but it turned see through. I cannot click x, I restarted explorer.exe, I killed the offending application, I’ve logged out, I’ve restarted my graphics driver but this window will not close. This window is stuck in the middle of my display and I cannot restart at the moment. Nothing I can find will get this box out of my way.
Thanks in advance.
Can someone help me navigate this issue? Windows 11 is really working hard at the WOAT OS title.
Please see the image. I had a popup for a software update, I tried to close the window but it turned see through. I cannot click x, I restarted explorer.exe, I killed the offending application, I’ve logged out, I’ve restarted my graphics driver but this window will not close. This window is stuck in the middle of my display and I cannot restart at the moment. Nothing I can find will get this box out of my way. Thanks in advance.Can someone help me navigate this issue? Windows 11 is really working hard at the WOAT OS title. Read More
Usability around retention labels
Some of our key stakeholders are complaining that the interface to assign a retention label is not very usable in that it displays just as one big dropdown and doesn’t provide any hierarchical grouping or search capability. Are there any workaround to this?
Some of our key stakeholders are complaining that the interface to assign a retention label is not very usable in that it displays just as one big dropdown and doesn’t provide any hierarchical grouping or search capability. Are there any workaround to this? Read More
Take a technical deep dive into Microsoft Fabric and prepare for your DP-600 certification!
FREE Microsoft Fabric Partner Workshop
May 6-9, 2024 | 8 am – 12 pm PST
Microsoft Fabric is an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence. Attend this course to learn more about this comprehensive suite of services, including data lake, data engineering, and data integration, all in one place. Learn how to implement this easy-to-use product that is designed to simplify analytics needs of enterprises.
This four-day virtual training experience includes two-to-four hours a day of:
Structured instructor-led training theory
Hands-on labs to help develop specialized skills
Live Q&A with technical experts
Learn more and register at https://aka.ms/partner/AzureVC
FREE Microsoft Fabric Partner Workshop
May 6-9, 2024 | 8 am – 12 pm PST
Microsoft Fabric is an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence. Attend this course to learn more about this comprehensive suite of services, including data lake, data engineering, and data integration, all in one place. Learn how to implement this easy-to-use product that is designed to simplify analytics needs of enterprises.
This four-day virtual training experience includes two-to-four hours a day of:
Structured instructor-led training theory
Hands-on labs to help develop specialized skills
Live Q&A with technical experts
Learn more and register at https://aka.ms/partner/AzureVC
Read More
Cód atreoraithe B I T G E T: qp29 (Bónas clárúcháin B I T G E T 1000 USDT)
Cód atreoraithe B I T G E T: qp29 (Bónas clárúcháin B I T G E T 1000 USDT) | Cód promo nua B I T G E T 2024
An bhfuil an cód atreoraithe B I T G E T á lorg agat? Is é an ceann deireanach do 2024 ná qp29. Leis an gcód seo gheobhaidh tú lascaine 30%. Ina theannta sin, is féidir le húsáideoirí nua B I T G E T a chláraíonn leis an gcód promo “qp29” duais tionscnaimh eisiach ar fiú suas le $1,000 a fháil.
Cad é an cód atreoraithe B I T G E T?
Feidhmíonn an cód “qp29” sa chlár BIT G E T mar chód atreoraithe. Tríd an gcód seo a chur isteach gheobhaidh tú laghdú buan ar tháillí trádála chomh maith le lascaine 30% ar do cheirdeanna. Má roinneann tú do chód atreoraithe le do chairde, beidh deis agat freisin bónas flaithiúil 50% a bhuachan. Trí úsáid a bhaint as an gcód seo tugtar deis luachmhar táillí a laghdú agus d’fhéadfadh do thuilleamh a mhéadú trí dhaoine eile a mhealladh chuig an ardán.
Cad é an cód atreoraithe B I T G E T 2024 is fearr?
Is é qp29 an cód atreoraithe B I T G E T a mholtar go mór. Má úsáideann tú an cód seo agus tú ag clárú gheobhaidh tú bónas flaithiúil $100. Má roinneann tú do chód le do chairde, tá an deis agat coimisiún ollmhór 50% a thuilleamh. Tugann sé seo go bunúsach an deis duit uasmhéid bónas clárúcháin suas le $1,000 a fháil mar luach saothair fáilte. Is bealach iontach é seo chun do thaithí trádála a leathnú le buntáistí breise agus daoine eile a spreagadh chun páirt a ghlacadh agus a luach saothair féin a thuilleamh.
Conas cód atreoraithe B I T G E T a úsáid
Tá an cód atreoraithe B I T G E T ar fáil d’úsáideoirí nua nach bhfuil cláraithe fós ar an malartán. Ar an drochuair, má tá cuntas agat cheana féin, ní bheidh tú in ann an cód atreoraithe a úsáid.
Mar sin féin, cuireann B I T G E T go leor bealaí eile ar fáil chun páirt a ghlacadh in arduithe céime agus luaíochtaí a thuilleamh. Breathnaímid ar na roghanna eile seo.
Maidir le daoine nua B I T G E T, seo treoracha céim ar chéim maidir le conas iarratas a dhéanamh ar chód atreoraithe:
Chun tús a chur leis, tabhair cuairt ar B I T G E T agus cliceáil ar an gcnaipe gorm “Sínigh Isteach”.
Cuir sonraí úsáideora cruinne ar fáil mar go seiceálfar iad le haghaidh comhlíonadh nósanna imeachta KYC agus AML.
Nuair a iarrtar ort do chód atreoraithe a fháil, cuir isteach qp29.
Críochnaigh an próiseas clárúcháin agus comhlánaigh aon fhíorú riachtanach.
Nuair a bheidh na coinníollacha go léir comhlíonta, is féidir leat an bónas fáilte a fháil láithreach.
Cinntíonn an cur chuige seo gur féidir le húsáideoirí nua an próiseas clárúcháin a chomhlánú go héasca fiú gan cód atreoraithe agus bónas fáilte a fháil tar éis dóibh na ceanglais atá leagtha síos a chomhlíonadh.
Cad é an cód atreoraithe molta do B I T G E T?
Cód atreoraithe B I T G E T – qp29. Chun 30% a bhaint as do choimisiún B I T G E T, níl le déanamh ach na céimeanna seo a leanúint:
Cláraigh cuntas nua le B I T G E T .
Bí cinnte go n-úsáideann tú an cód tagartha B I T G E T qp29.
Cé mhéad atá sa bhónas atreoraithe do B I T G E T?
Tabhair cuireadh do chairde a bheith páirteach i B I T G E T agus sciar den chomhthiomsú duaise atreoraithe a bhuachan le chéile! Is féidir le gach cara dá dtagraíonn tú $50 a thuilleamh, suas go huasmhéid $1,000 in aghaidh an úsáideora. Is féidir le húsáideoirí cuireadh a thabhairt do chairde clárú le B I T G E T. Má chomhlíonann siad na ceanglais go léir, gheobhaidh tú féin agus do chairde bónais trádála de $50 suas go dtí an uasteorainn.
Conas a gheobhaidh mé an bónas B I T G E T?
Pointí a thuilleamh gach lá agus iad a mhalartú le haghaidh USDT. Críochnaigh an dúshlán laistigh de sheacht lá chun gach luach saothair a dhíghlasáil. Cláraigh chun pacáiste fáilte dar luach $1,000 a fháil. Taisce ar a laghad $50 chun 200 pointe a thuilleamh. Déan do chéad trádáil ar fiú ar a laghad $50 agus 500 pointe a thuilleamh.
An gcuirtear lascainí coimisiúin trádála i bhfeidhm go huathoibríoch?
Cinnte. Nuair a chláraíonn tú lenár gcód atreoraithe eisiach B I T G E T qp29, cuirfear an lascaine 30% i bhfeidhm go huathoibríoch. Níl gá le gníomh breise. Léim isteach sa trádáil agus bain tairbhe as lascaine buan 30% ar gach coimisiún.
Cód atreoraithe B I T G E T: qp29 (Bónas clárúcháin B I T G E T 1000 USDT) | Cód promo nua B I T G E T 2024An bhfuil an cód atreoraithe B I T G E T á lorg agat? Is é an ceann deireanach do 2024 ná qp29. Leis an gcód seo gheobhaidh tú lascaine 30%. Ina theannta sin, is féidir le húsáideoirí nua B I T G E T a chláraíonn leis an gcód promo “qp29” duais tionscnaimh eisiach ar fiú suas le $1,000 a fháil.Cad é an cód atreoraithe B I T G E T?Feidhmíonn an cód “qp29” sa chlár BIT G E T mar chód atreoraithe. Tríd an gcód seo a chur isteach gheobhaidh tú laghdú buan ar tháillí trádála chomh maith le lascaine 30% ar do cheirdeanna. Má roinneann tú do chód atreoraithe le do chairde, beidh deis agat freisin bónas flaithiúil 50% a bhuachan. Trí úsáid a bhaint as an gcód seo tugtar deis luachmhar táillí a laghdú agus d’fhéadfadh do thuilleamh a mhéadú trí dhaoine eile a mhealladh chuig an ardán.Cad é an cód atreoraithe B I T G E T 2024 is fearr?Is é qp29 an cód atreoraithe B I T G E T a mholtar go mór. Má úsáideann tú an cód seo agus tú ag clárú gheobhaidh tú bónas flaithiúil $100. Má roinneann tú do chód le do chairde, tá an deis agat coimisiún ollmhór 50% a thuilleamh. Tugann sé seo go bunúsach an deis duit uasmhéid bónas clárúcháin suas le $1,000 a fháil mar luach saothair fáilte. Is bealach iontach é seo chun do thaithí trádála a leathnú le buntáistí breise agus daoine eile a spreagadh chun páirt a ghlacadh agus a luach saothair féin a thuilleamh.Conas cód atreoraithe B I T G E T a úsáidTá an cód atreoraithe B I T G E T ar fáil d’úsáideoirí nua nach bhfuil cláraithe fós ar an malartán. Ar an drochuair, má tá cuntas agat cheana féin, ní bheidh tú in ann an cód atreoraithe a úsáid.Mar sin féin, cuireann B I T G E T go leor bealaí eile ar fáil chun páirt a ghlacadh in arduithe céime agus luaíochtaí a thuilleamh. Breathnaímid ar na roghanna eile seo.Maidir le daoine nua B I T G E T, seo treoracha céim ar chéim maidir le conas iarratas a dhéanamh ar chód atreoraithe:Chun tús a chur leis, tabhair cuairt ar B I T G E T agus cliceáil ar an gcnaipe gorm “Sínigh Isteach”.Cuir sonraí úsáideora cruinne ar fáil mar go seiceálfar iad le haghaidh comhlíonadh nósanna imeachta KYC agus AML.Nuair a iarrtar ort do chód atreoraithe a fháil, cuir isteach qp29.Críochnaigh an próiseas clárúcháin agus comhlánaigh aon fhíorú riachtanach.Nuair a bheidh na coinníollacha go léir comhlíonta, is féidir leat an bónas fáilte a fháil láithreach.Cinntíonn an cur chuige seo gur féidir le húsáideoirí nua an próiseas clárúcháin a chomhlánú go héasca fiú gan cód atreoraithe agus bónas fáilte a fháil tar éis dóibh na ceanglais atá leagtha síos a chomhlíonadh.Cad é an cód atreoraithe molta do B I T G E T?Cód atreoraithe B I T G E T – qp29. Chun 30% a bhaint as do choimisiún B I T G E T, níl le déanamh ach na céimeanna seo a leanúint:Cláraigh cuntas nua le B I T G E T .Bí cinnte go n-úsáideann tú an cód tagartha B I T G E T qp29.Cé mhéad atá sa bhónas atreoraithe do B I T G E T?Tabhair cuireadh do chairde a bheith páirteach i B I T G E T agus sciar den chomhthiomsú duaise atreoraithe a bhuachan le chéile! Is féidir le gach cara dá dtagraíonn tú $50 a thuilleamh, suas go huasmhéid $1,000 in aghaidh an úsáideora. Is féidir le húsáideoirí cuireadh a thabhairt do chairde clárú le B I T G E T. Má chomhlíonann siad na ceanglais go léir, gheobhaidh tú féin agus do chairde bónais trádála de $50 suas go dtí an uasteorainn.Conas a gheobhaidh mé an bónas B I T G E T?Pointí a thuilleamh gach lá agus iad a mhalartú le haghaidh USDT. Críochnaigh an dúshlán laistigh de sheacht lá chun gach luach saothair a dhíghlasáil. Cláraigh chun pacáiste fáilte dar luach $1,000 a fháil. Taisce ar a laghad $50 chun 200 pointe a thuilleamh. Déan do chéad trádáil ar fiú ar a laghad $50 agus 500 pointe a thuilleamh.An gcuirtear lascainí coimisiúin trádála i bhfeidhm go huathoibríoch?Cinnte. Nuair a chláraíonn tú lenár gcód atreoraithe eisiach B I T G E T qp29, cuirfear an lascaine 30% i bhfeidhm go huathoibríoch. Níl gá le gníomh breise. Léim isteach sa trádáil agus bain tairbhe as lascaine buan 30% ar gach coimisiún. Read More
Henvisningskode B I T G E T: qp29 (B I T G E T 1000 USDT registreringsbonus)
Henvisningskode B I T G E T: qp29 (B I T G E T 1000 USDT registreringsbonus) | Ny kampagnekode B I T G E T
Henvisningskode B I T G E T: qp29 (B I T G E T 1000 USDT registreringsbonus) | Ny kampagnekode B I T G E T 2024
Leder du efter henvisningskoden B I T G E T? Den sidste for 2024 er qp29. Med denne kode får du 30% rabat. Derudover kan nye B I T G E T-brugere, der tilmelder sig med kampagnekoden “qp29”, modtage en eksklusiv kampagnebelønning til en værdi af op til $1.000.
Hvad er henvisningskoden B I T G E T?
Koden “qp29” i BIT G E T-programmet fungerer som en henvisningskode. Ved at indtaste denne kode vil du modtage en permanent reduktion i handelsgebyrer samt 30% rabat på dine handler. Hvis du deler din henvisningskode med dine venner, har du også en chance for at vinde en generøs 50% bonus. Brug af denne kode giver en værdifuld mulighed for at reducere gebyrer og potentielt øge din indtjening ved at tiltrække andre til platformen.
Hvad er den bedste B I T G E T 2024 henvisningskode?
Den stærkt anbefalede B I T G E T-henvisningskode er qp29. Hvis du bruger denne kode, når du tilmelder dig, vil du modtage en generøs $100 bonus. Hvis du deler din kode med dine venner, har du mulighed for at tjene en kæmpe kommission på 50%. Dette giver dig i bund og grund muligheden for at modtage en maksimal tilmeldingsbonus på op til $1.000 som en velkomstbelønning. Dette er en fantastisk måde at udvide din handelsoplevelse med yderligere fordele, mens du opmuntrer andre til at deltage og tjene deres egne belønninger.
Sådan bruger du henvisningskoden B I T G E T
Henvisningskoden B I T G E T er tilgængelig for nye brugere, som endnu ikke er registreret på børsen. Hvis du allerede har en konto, vil du desværre ikke kunne bruge henvisningskoden.
B I T G E T tilbyder dog flere andre måder at deltage i kampagner og optjene belønninger på. Lad os se på disse alternativer.
For B I T G E T nybegyndere er her trin-for-trin instruktioner om, hvordan man ansøger om en henvisningskode:
For at komme i gang skal du besøge B I T G E T og klikke på den blå “Log ind”-knap.
Angiv nøjagtige brugeroplysninger, da de vil blive kontrolleret for overholdelse af KYC- og AML-procedurer.
Når du bliver bedt om din henvisningskode, skal du indtaste qp29.
Fuldfør registreringsprocessen og fuldfør alle nødvendige bekræftelser.
Når alle betingelser er opfyldt, kan du straks modtage velkomstbonussen.
Denne tilgang sikrer, at nye brugere nemt kan gennemføre registreringsprocessen selv uden en henvisningskode og modtage en velkomstbonus efter at have opfyldt de fastsatte krav.
Hvad er den anbefalede henvisningskode for B I T G E T?
Henvisningskode B I T G E T – qp29. For at få 30 % rabat på din B I T G E T-kommission skal du blot følge disse trin:
Registrer en ny konto hos B I T G E T.
Sørg for at bruge referencekoden B I T G E T qp29.
Hvor meget er henvisningsbonussen for B I T G E T?
Inviter dine venner til at deltage i B I T G E T og vind en del af henvisningspræmiepuljen sammen! Hver ven, du henviser, kan tjene $50, op til et maksimum på $1.000 pr. bruger. Brugere kan invitere venner til at registrere sig hos B I T G E T. Hvis de opfylder alle kravene, vil du og dine venner modtage handelsbonusser på $50 op til maksimumgrænsen.
Hvordan får jeg B I T G E T bonussen?
Optjen point dagligt og byt dem til USDT. Gennemfør udfordringen inden for syv dage for at låse op for alle belønninger. Tilmeld dig for at modtage en velkomstpakke til en værdi af $1.000. Indbetal mindst $50 for at optjene 200 point. Lav din første handel til en værdi af mindst $50 og optjen 500 point.
Anvendes handelskommissionsrabatter automatisk?
Absolut. Når du registrerer dig med vores eksklusive henvisningskode B I T G E T qp29, vil 30% rabatten blive anvendt automatisk. Der kræves ingen yderligere handling. Du skal bare dykke ned i handel og nyde godt af en permanent 30% rabat på alle kommissioner.
Henvisningskode B I T G E T: qp29 (B I T G E T 1000 USDT registreringsbonus) | Ny kampagnekode B I T G E THenvisningskode B I T G E T: qp29 (B I T G E T 1000 USDT registreringsbonus) | Ny kampagnekode B I T G E T 2024Leder du efter henvisningskoden B I T G E T? Den sidste for 2024 er qp29. Med denne kode får du 30% rabat. Derudover kan nye B I T G E T-brugere, der tilmelder sig med kampagnekoden “qp29”, modtage en eksklusiv kampagnebelønning til en værdi af op til $1.000.Hvad er henvisningskoden B I T G E T?Koden “qp29” i BIT G E T-programmet fungerer som en henvisningskode. Ved at indtaste denne kode vil du modtage en permanent reduktion i handelsgebyrer samt 30% rabat på dine handler. Hvis du deler din henvisningskode med dine venner, har du også en chance for at vinde en generøs 50% bonus. Brug af denne kode giver en værdifuld mulighed for at reducere gebyrer og potentielt øge din indtjening ved at tiltrække andre til platformen.Hvad er den bedste B I T G E T 2024 henvisningskode?Den stærkt anbefalede B I T G E T-henvisningskode er qp29. Hvis du bruger denne kode, når du tilmelder dig, vil du modtage en generøs $100 bonus. Hvis du deler din kode med dine venner, har du mulighed for at tjene en kæmpe kommission på 50%. Dette giver dig i bund og grund muligheden for at modtage en maksimal tilmeldingsbonus på op til $1.000 som en velkomstbelønning. Dette er en fantastisk måde at udvide din handelsoplevelse med yderligere fordele, mens du opmuntrer andre til at deltage og tjene deres egne belønninger.Sådan bruger du henvisningskoden B I T G E THenvisningskoden B I T G E T er tilgængelig for nye brugere, som endnu ikke er registreret på børsen. Hvis du allerede har en konto, vil du desværre ikke kunne bruge henvisningskoden.B I T G E T tilbyder dog flere andre måder at deltage i kampagner og optjene belønninger på. Lad os se på disse alternativer.For B I T G E T nybegyndere er her trin-for-trin instruktioner om, hvordan man ansøger om en henvisningskode:For at komme i gang skal du besøge B I T G E T og klikke på den blå “Log ind”-knap.Angiv nøjagtige brugeroplysninger, da de vil blive kontrolleret for overholdelse af KYC- og AML-procedurer.Når du bliver bedt om din henvisningskode, skal du indtaste qp29.Fuldfør registreringsprocessen og fuldfør alle nødvendige bekræftelser.Når alle betingelser er opfyldt, kan du straks modtage velkomstbonussen.Denne tilgang sikrer, at nye brugere nemt kan gennemføre registreringsprocessen selv uden en henvisningskode og modtage en velkomstbonus efter at have opfyldt de fastsatte krav.Hvad er den anbefalede henvisningskode for B I T G E T?Henvisningskode B I T G E T – qp29. For at få 30 % rabat på din B I T G E T-kommission skal du blot følge disse trin:Registrer en ny konto hos B I T G E T.Sørg for at bruge referencekoden B I T G E T qp29.Hvor meget er henvisningsbonussen for B I T G E T?Inviter dine venner til at deltage i B I T G E T og vind en del af henvisningspræmiepuljen sammen! Hver ven, du henviser, kan tjene $50, op til et maksimum på $1.000 pr. bruger. Brugere kan invitere venner til at registrere sig hos B I T G E T. Hvis de opfylder alle kravene, vil du og dine venner modtage handelsbonusser på $50 op til maksimumgrænsen.Hvordan får jeg B I T G E T bonussen?Optjen point dagligt og byt dem til USDT. Gennemfør udfordringen inden for syv dage for at låse op for alle belønninger. Tilmeld dig for at modtage en velkomstpakke til en værdi af $1.000. Indbetal mindst $50 for at optjene 200 point. Lav din første handel til en værdi af mindst $50 og optjen 500 point.Anvendes handelskommissionsrabatter automatisk?Absolut. Når du registrerer dig med vores eksklusive henvisningskode B I T G E T qp29, vil 30% rabatten blive anvendt automatisk. Der kræves ingen yderligere handling. Du skal bare dykke ned i handel og nyde godt af en permanent 30% rabat på alle kommissioner. Read More
Using on prem AD security group for DLP
Our compliance team is testing DLP in our environment and has run into a hiccup. It seems when they use a security group with a source of Windows Server AD for the Scope of Exchange, SharePoint, OneDrive and Teams, the policy does not work (see attachment DLP_WindowsServerAD group.png for example of what I mean by source). When using an on prem AD group for scope, users are still able to send SSNs or CC#s in Teams messages or emails, for example.
However, when they use a security group with a source of Cloud for the Scope, the policy does work (see attachment DLP_Cloud group.png for example).
To clarify where I’m talking about, when you’re editing a DLP, click Next twice and you’re on the Choose where to apply the policy page. Here you click Edit in the far right column to set which groups are in scope for the given policy (see attachment DLP_scope.png).
Is this expected behavior, for DLP to have an issue using groups from on prem AD to scope the policy?
Our compliance team is testing DLP in our environment and has run into a hiccup. It seems when they use a security group with a source of Windows Server AD for the Scope of Exchange, SharePoint, OneDrive and Teams, the policy does not work (see attachment DLP_WindowsServerAD group.png for example of what I mean by source). When using an on prem AD group for scope, users are still able to send SSNs or CC#s in Teams messages or emails, for example. However, when they use a security group with a source of Cloud for the Scope, the policy does work (see attachment DLP_Cloud group.png for example). To clarify where I’m talking about, when you’re editing a DLP, click Next twice and you’re on the Choose where to apply the policy page. Here you click Edit in the far right column to set which groups are in scope for the given policy (see attachment DLP_scope.png). Is this expected behavior, for DLP to have an issue using groups from on prem AD to scope the policy? Read More
MY WINDOWS 10 COPILOT PREVIEW IS GONE HOW CAN I GET IT BACK?
I Re-installed Windows 10 after 6 years…. the one i installed in Feb 2024. was getting preview updates as i joined insider… in March 2024 Copilot Preview icon appeared automatically. i had to re-install windows on APRIL 13, 2024. i updated ….no preview updates installed then i signed into windows insider and got preview update & its release tell about improvement in performance of Copilot preview… but i dont have that icon of copilot preview ( which appeared automatically in old windows installed in feb removed in april 2024) this time…..??????
I Re-installed Windows 10 after 6 years…. the one i installed in Feb 2024. was getting preview updates as i joined insider… in March 2024 Copilot Preview icon appeared automatically. i had to re-install windows on APRIL 13, 2024. i updated ….no preview updates installed then i signed into windows insider and got preview update & its release tell about improvement in performance of Copilot preview… but i dont have that icon of copilot preview ( which appeared automatically in old windows installed in feb removed in april 2024) this time…..?????? Read More
Trusted Signing is in Public Preview!
The Trusted Signing service is in Public Preview: Trusted Signing is in Public Preview – Microsoft Community Hub!
The Trusted Signing service is in Public Preview: Trusted Signing is in Public Preview – Microsoft Community Hub! Read More
How to match matrix elements for a condition?
I am working on App Designer. I have a matrix and want to match the elements 3 by 3 with a condition. The condition is that addition of 3 elements must be near at a value.
I already can match them by making the addition from minimum to maximum, but it does not seem to be optimal. So, I want them to be around a value.I am working on App Designer. I have a matrix and want to match the elements 3 by 3 with a condition. The condition is that addition of 3 elements must be near at a value.
I already can match them by making the addition from minimum to maximum, but it does not seem to be optimal. So, I want them to be around a value. I am working on App Designer. I have a matrix and want to match the elements 3 by 3 with a condition. The condition is that addition of 3 elements must be near at a value.
I already can match them by making the addition from minimum to maximum, but it does not seem to be optimal. So, I want them to be around a value. matlab gui, matlab, appdesigner, app designer, data, sort, match MATLAB Answers — New Questions
summation of aij & i, j dependent function in matlab
Hello, I am trying to create a code that can calculate the local resistance coefficient via formula above. the values of ai and aij are defined.
I have created a code using for loops, but getting a really high number.
I have defined example values for Re, f0, and f1 values below. Using the published graph, I should be getting around 1-1.1
ai and bi are values defined.
Please forgive me, it might be that I got matrix algebra incorrect, as I am thinking that might be the suspicion but not sure what I need to change at this point.
Thank you.
%
% initial contraction from flow, formula from diagram 4.10
%
%
%given test values
Re_0=60.46;
f0=1;
f1=2.7225;
%
ind=8;
acoeff=0;
ai=[-25.12458,18.5076,-170.4147,118.1949,-44.42141,9.09524,-.9244027,.03408265];
for i = 1:ind
acoeff=acoeff+ai(i)*log(Re_0)^i;
end
acoeff
bi=[1.07 1.22 2.933;.05 -.51668 .8333; 0 0 0];
iB=3;
jB=3;
count=0;
B_inner=0;
Bcoeff=0;
for i=1:iB
for j=1:jB
B_inner=B_inner+bi(i,j)*((f0/f1)^j);
end
Bcoeff=Bcoeff+B_inner*log(Re_0)^i;
end
Coeff_local=(acoeff*Bcoeff)*(1-f0/f1)Hello, I am trying to create a code that can calculate the local resistance coefficient via formula above. the values of ai and aij are defined.
I have created a code using for loops, but getting a really high number.
I have defined example values for Re, f0, and f1 values below. Using the published graph, I should be getting around 1-1.1
ai and bi are values defined.
Please forgive me, it might be that I got matrix algebra incorrect, as I am thinking that might be the suspicion but not sure what I need to change at this point.
Thank you.
%
% initial contraction from flow, formula from diagram 4.10
%
%
%given test values
Re_0=60.46;
f0=1;
f1=2.7225;
%
ind=8;
acoeff=0;
ai=[-25.12458,18.5076,-170.4147,118.1949,-44.42141,9.09524,-.9244027,.03408265];
for i = 1:ind
acoeff=acoeff+ai(i)*log(Re_0)^i;
end
acoeff
bi=[1.07 1.22 2.933;.05 -.51668 .8333; 0 0 0];
iB=3;
jB=3;
count=0;
B_inner=0;
Bcoeff=0;
for i=1:iB
for j=1:jB
B_inner=B_inner+bi(i,j)*((f0/f1)^j);
end
Bcoeff=Bcoeff+B_inner*log(Re_0)^i;
end
Coeff_local=(acoeff*Bcoeff)*(1-f0/f1) Hello, I am trying to create a code that can calculate the local resistance coefficient via formula above. the values of ai and aij are defined.
I have created a code using for loops, but getting a really high number.
I have defined example values for Re, f0, and f1 values below. Using the published graph, I should be getting around 1-1.1
ai and bi are values defined.
Please forgive me, it might be that I got matrix algebra incorrect, as I am thinking that might be the suspicion but not sure what I need to change at this point.
Thank you.
%
% initial contraction from flow, formula from diagram 4.10
%
%
%given test values
Re_0=60.46;
f0=1;
f1=2.7225;
%
ind=8;
acoeff=0;
ai=[-25.12458,18.5076,-170.4147,118.1949,-44.42141,9.09524,-.9244027,.03408265];
for i = 1:ind
acoeff=acoeff+ai(i)*log(Re_0)^i;
end
acoeff
bi=[1.07 1.22 2.933;.05 -.51668 .8333; 0 0 0];
iB=3;
jB=3;
count=0;
B_inner=0;
Bcoeff=0;
for i=1:iB
for j=1:jB
B_inner=B_inner+bi(i,j)*((f0/f1)^j);
end
Bcoeff=Bcoeff+B_inner*log(Re_0)^i;
end
Coeff_local=(acoeff*Bcoeff)*(1-f0/f1) matrix, index MATLAB Answers — New Questions
How to improve the simulation time in a comprehensive Simulink battery model?
Hello,
In my Simulink model I want to simulate a battery pack with about 5000 individual cells. These should differ slightly from each other, which is why I use the generic battery model from Simscape for each cell (I don’t have the license for Simscape Battery). Now it is not surprising that the simulation time is very high with this number. However, since the blocks are repeated with serial and parallel connection, I tried to improve the simulation time with Scalable Compilation (Referenced Subsystems) according to the following instructions:
https://de.mathworks.com/help/simscape/ug/prepare-your-model-for-scalable-compilation.html
Contrary to expectations, this worsened the simulation time.
Is there another way to simulate such an extensive model in a reasonable time? I would be very grateful for any suggestions.Hello,
In my Simulink model I want to simulate a battery pack with about 5000 individual cells. These should differ slightly from each other, which is why I use the generic battery model from Simscape for each cell (I don’t have the license for Simscape Battery). Now it is not surprising that the simulation time is very high with this number. However, since the blocks are repeated with serial and parallel connection, I tried to improve the simulation time with Scalable Compilation (Referenced Subsystems) according to the following instructions:
https://de.mathworks.com/help/simscape/ug/prepare-your-model-for-scalable-compilation.html
Contrary to expectations, this worsened the simulation time.
Is there another way to simulate such an extensive model in a reasonable time? I would be very grateful for any suggestions. Hello,
In my Simulink model I want to simulate a battery pack with about 5000 individual cells. These should differ slightly from each other, which is why I use the generic battery model from Simscape for each cell (I don’t have the license for Simscape Battery). Now it is not surprising that the simulation time is very high with this number. However, since the blocks are repeated with serial and parallel connection, I tried to improve the simulation time with Scalable Compilation (Referenced Subsystems) according to the following instructions:
https://de.mathworks.com/help/simscape/ug/prepare-your-model-for-scalable-compilation.html
Contrary to expectations, this worsened the simulation time.
Is there another way to simulate such an extensive model in a reasonable time? I would be very grateful for any suggestions. simscape, battery, simulation time, scalable compilation, referenced subsystems MATLAB Answers — New Questions
How to plot from .txt file
How do I plot the 2D and mesh graphs asked for if this is the code I’m using?
%start with a right triangle of length x = 1 and y = 1
%calculate all values (hypotenuse, perimeter, and area)
%for combinations of x = 1:5 and y = 1:5
%Print all of those as a table to a .txt file
%output should look something like this
%{
x y h p a
1 1 1.4 3.41 0.5
1 2 2.24 5.24 1
…..
…..
….. etc
%}
% using the data from the table
% plot a line (2d) graph of the perimeter(x axis) vs area (y axis)
% plot a mesh (3d) graph with x, y (respectively), and h on the ‘z’ axis
x = 1
y = 1
myFile = fopen(‘myValues.txt’, ‘w’)
fprintf(myFile, "X LengthtY Lengtht Hypot LengthttPerimeterttArean")
for i = 1:5
for j = 1:5
myHypot = hValue(i,j)
myPerim = pValue(i,j)
myArea = aValue(i,j)
fprintf(myFile, string(i) + "ttt" + string(j) + "tttt" + string(myHypot) + "ttt" + string(myPerim) + "ttt" + string(myArea) + "n")
end
end
plot(myPerim,myArea)
function hValue = hValue(xValue,yValue)
hValue = sqrt(xValue.^2+yValue.^2);
end
function pValue = pValue(xValue,yValue)
pValue = (xValue + yValue + (sqrt(xValue.^2+yValue.^2)));
end
function aValue = aValue(xValue,yValue)
aValue = 0.5*xValue*yValue;
endHow do I plot the 2D and mesh graphs asked for if this is the code I’m using?
%start with a right triangle of length x = 1 and y = 1
%calculate all values (hypotenuse, perimeter, and area)
%for combinations of x = 1:5 and y = 1:5
%Print all of those as a table to a .txt file
%output should look something like this
%{
x y h p a
1 1 1.4 3.41 0.5
1 2 2.24 5.24 1
…..
…..
….. etc
%}
% using the data from the table
% plot a line (2d) graph of the perimeter(x axis) vs area (y axis)
% plot a mesh (3d) graph with x, y (respectively), and h on the ‘z’ axis
x = 1
y = 1
myFile = fopen(‘myValues.txt’, ‘w’)
fprintf(myFile, "X LengthtY Lengtht Hypot LengthttPerimeterttArean")
for i = 1:5
for j = 1:5
myHypot = hValue(i,j)
myPerim = pValue(i,j)
myArea = aValue(i,j)
fprintf(myFile, string(i) + "ttt" + string(j) + "tttt" + string(myHypot) + "ttt" + string(myPerim) + "ttt" + string(myArea) + "n")
end
end
plot(myPerim,myArea)
function hValue = hValue(xValue,yValue)
hValue = sqrt(xValue.^2+yValue.^2);
end
function pValue = pValue(xValue,yValue)
pValue = (xValue + yValue + (sqrt(xValue.^2+yValue.^2)));
end
function aValue = aValue(xValue,yValue)
aValue = 0.5*xValue*yValue;
end How do I plot the 2D and mesh graphs asked for if this is the code I’m using?
%start with a right triangle of length x = 1 and y = 1
%calculate all values (hypotenuse, perimeter, and area)
%for combinations of x = 1:5 and y = 1:5
%Print all of those as a table to a .txt file
%output should look something like this
%{
x y h p a
1 1 1.4 3.41 0.5
1 2 2.24 5.24 1
…..
…..
….. etc
%}
% using the data from the table
% plot a line (2d) graph of the perimeter(x axis) vs area (y axis)
% plot a mesh (3d) graph with x, y (respectively), and h on the ‘z’ axis
x = 1
y = 1
myFile = fopen(‘myValues.txt’, ‘w’)
fprintf(myFile, "X LengthtY Lengtht Hypot LengthttPerimeterttArean")
for i = 1:5
for j = 1:5
myHypot = hValue(i,j)
myPerim = pValue(i,j)
myArea = aValue(i,j)
fprintf(myFile, string(i) + "ttt" + string(j) + "tttt" + string(myHypot) + "ttt" + string(myPerim) + "ttt" + string(myArea) + "n")
end
end
plot(myPerim,myArea)
function hValue = hValue(xValue,yValue)
hValue = sqrt(xValue.^2+yValue.^2);
end
function pValue = pValue(xValue,yValue)
pValue = (xValue + yValue + (sqrt(xValue.^2+yValue.^2)));
end
function aValue = aValue(xValue,yValue)
aValue = 0.5*xValue*yValue;
end plots, mesh, graph, text file, matlab MATLAB Answers — New Questions
Common factor
Is there a function to make it find a common factor in an expression with symbolic variables?
For example:
ab+ac–(matlab command)—>a(b+c)
ThanksIs there a function to make it find a common factor in an expression with symbolic variables?
For example:
ab+ac–(matlab command)—>a(b+c)
Thanks Is there a function to make it find a common factor in an expression with symbolic variables?
For example:
ab+ac–(matlab command)—>a(b+c)
Thanks matlab, factor MATLAB Answers — New Questions
Standalone Intune subscription for onboarding computer with Windows 11/10
Hello,
I have 3 computers that are used for running specific company workloads and are not used by users… These are running Windows 11 or 10 OS. 2 of them are on-prem and one is a VM in Azure.
Now, I would like to have them managed by Intune – same as all end user computers. What is the recommended approach to onboard them to Intune? Is there any “per device” Intune subscription? Or should I just have an extra user account that I will assign Intune subscription and use that account to log in to those computers so that they are enrolled to Intune with that account? Would it cause any conflicts if I have one user account used to onboard several devices?
Not sure what is the best way in those situations…
Thank you
Hello, I have 3 computers that are used for running specific company workloads and are not used by users… These are running Windows 11 or 10 OS. 2 of them are on-prem and one is a VM in Azure. Now, I would like to have them managed by Intune – same as all end user computers. What is the recommended approach to onboard them to Intune? Is there any “per device” Intune subscription? Or should I just have an extra user account that I will assign Intune subscription and use that account to log in to those computers so that they are enrolled to Intune with that account? Would it cause any conflicts if I have one user account used to onboard several devices? Not sure what is the best way in those situations… Thank you Read More
Protecting your IP in the Azure Marketplace
The Azure Marketplace is an online store for Azure customers to discover, evaluate, and purchase a wide array of solutions with integrated billing and easy deployment. While the Azure Marketplace is used for billing, it does not manage licenses directly. It’s essential to integrate your own license management system to protect your intellectual property (IP) from unauthorized access or misuse.
We are seeing an increase in these types of questions, especially from our AI partners. This article outlines strategies to safeguard your IP effectively when deploying an Azure VM or Azure Container Offer.
Obfuscate Your Code
Restrict Shell Access
Use a License Manager
Protect AI Models
Secure Containers with ENTRYPOINT
Utilize Azure Metadata Service
Conclusion
Microsoft Tech Community – Latest Blogs –Read More

AI Frontiers: Human insights on AI training
Recent developments in AI require more computing power to train the models. During training, the model learns from data how to perform specific tasks. Now, recent models like GPT, which have billions of parameters, require memory-intensive processing and power-intensive trainings. This requires a massive infrastructure. Thus, we have two main components for AI model training: data and compute. In my post, I explained training by drawing simple comparisons with human learning, discussed why the cloud can be a perfect fit for training AI models, and outlined some future directions that I believe will be important.
Inferencing and training
Let’s start by briefly comparing the training of AI models with the human learning process. A major difference is that the training of current models is massive and relatively fast, whereas human learning is much more diverse and incremental process, spanning over a long period of time. Consider the development of a baby’s or child’s brain; the learning process here includes observations and discoveries across a wide range of fields over the years. Human learning is a much more incremental and slow process compared to the massive model training conducted today.
AI models are trained on massive datasets, through which they learn to perform specific tasks. During training, these models learn from a training dataset that contains broad knowledge, enabling them to exhibit behaviours that can be described as common sense/behaviour. The objective of this base training is to instil such common sense, where the model showcases human-like behaviours based on general/shared knowledge. In contrast, the human brain undergoes a different kind of trainings by nature, where the subjects are diverse and the environment is constantly changing. Each day, we learn from a multitude of small observations across various fields.
I would like to emphasize two key concepts here: multimodality and model refinement.
Multi-modality & Domain-specific Finetuning
As the brain is complex, we are not sure exactly how different pieces of information correlate within it. Take a simple example: How does reading books improve math skills? We don’t know the exact correlation between them, but we do know that one exists. Skills or insights gained from one area might be beneficial when performing tasks in another field. This underscores the importance of direction with multi-modality, which enhances a model’s ability to reason about an answer. Reasoning is also related to common sense, which we mentioned earlier. A model can exhibit better behaviour when trained on diverse tasks from different domains. Referring again to human learning, we noted that it is more like a slow, incremental process across various fields over a long period. Here, we can draw some parallels between multi-modality/training in different domains and human learning across different fields.
Optimized Fine-tuning
As trained models should be adapted for production use, model refinement is becoming an increasingly important topic. Today, model refinement is achieved through a process called fine-tuning. Through fine-tuning, the model is adapted to specific domains by changing/reconfiguring its parameters. To make it easier to understand, let’s consider an example of human learning. Imagine an exam period where you have exams on different subjects, with one week between each exam. Ideally, you should focus your preparation on the subject of the next exam each week. At the exam, this enables you to answer questions related to that subject more effectively. Fine-tuning is similar in some respects, as the model is fine-tuned specifically for a domain to perform tasks better within that domain. When you fine-tune your model on physics datasets, it is expected to answer physics-related questions better. Similarly, when you fine-tune on Azure Q&A, you can expect your model to answer questions in the Azure context more accurately.
Here we speak of a customization of the model. The model is refined in terms of we adjust model parameters. Thus, we do not require to retrain the base model from scratch. But just to mention, not like training but fine-tuning is also a compute & cost intensive process.
A significant improvement in this area came with LoRA. The concept is to conduct training focused only on the parts of the model that need improvement. Thus, a very small part of the model is fine-tuned (<1%). This requires much less memory in comparison. The added parameters, known as LoRAs, act as adapters associated with the task. The resulting models with adapters can be viewed as experts, effective in their respective tasks. They are referred to as LoRA Experts.
LoRA: Low-Rank Adaptation of Large Language Models – Microsoft Research
To draw an analogy with the exam period example mentioned earlier, imagine you have one exam each week from a different subject. For each exam, you need specific knowledge for that subject, so ideally, you prepare the week before to be capable of understanding and solving the exam problems related to that specific subject. I see many similarities with the concept of LoRA here. Using different LoRA adapters will provide expert models that can be used for task- or domain-specific applications. Based on a user query, the appropriate LoRA adapter can be selected from a library. This allows the use of an expert model (LoRA Expert) for the task, where it is expected to perform well. The analogy here is like a person who has prepared for a week for a biology exam, then taking the biology exam.
Training LoRA models is very energy-efficient, as it reduces the number of trainable parameters. This introduces a new concept: centralized training for the base model (like GPT) and decentralized training for the Expert models (LoRA adapters).
The initial large-scale training required will be done centrally to generate a base model. This base model will then be used with relatively small refinements, known as LoRA adapters, in a decentralized manner. This approach is logical by nature because the fine-tuning of the model is mostly done for production, where the model is expected to serve a specific domain that requires domain-specific adaptation. This does not necessarily require large-scale centralized training.
Initially, we discussed multi-modality. I don’t want to delve deeply into LoRA here. I would like to just highlight a recent work on multi-modal adaptation of LoRA, which involves the addition of ~2.5% more parameters to the model. The user can refer to [2311.11501] MultiLoRA: Democratizing LoRA for Better Multi-Task Learning (arxiv.org)
Transparent checkpointing
During training, things can go wrong. Ideally, you don’t want the training to have to restart, as this may not be possible due to time and cost constraints. Transparent checkpointing is a promising step forward. It allows you to set checkpoints during the model training process. If an error occurs during training, you can revert to the previous checkpoint without needing to restart from the beginning. This is a significant cost-saving improvement and also makes it easier to change models at the hardware level. Since the model states can be saved, training can be paused and another model, along with its state, can be uploaded. This offers a lot of flexibility, especially in the cloud. I believe that in the future, it might even provide interesting insights into training itself, as it allows observation of disk states at different training milestones.
It is demonstrated as the GPU-adapted version of CRIU for Linux. With CRIU it is possible to freeze and save the CPU state by containers.
As checkpointing builds some kind of insurance, as no complete training restart is needed. Still there is a custom decision needed to be made, where you can choose to set less or more frequent checkpoints. Here comes the trade-off between the cost of more frequent checkpoint vs costs in the case of training failure/loss.
Why checkpoint optimization for large model training matters? – MS Learn
Energy Consumption
The topic of energy consumption and the efficiency of AI systems is very important. To create a sustainable platform, the underlying hardware must be efficient as first. Two key aspects to consider are the efficiency and utilization of the infrastructure. The hardware should be used efficiently and be inherently efficient.
The benefits of training AI models on Azure Cloud Infrastructure include scalability. We are talking about multiple GPUs not operating on the same board and not even in the same rack. They are spread out through consumption and heat. It has a global scheduler across one global hardware fleet of CPUs and GPUs. Thus, this infrastructure can scale from modest training sessions up to an OpenAI supercomputing system.
Before the Azure AI infrastructure was announced, it was expected that the infrastructure would be mostly used for training. However, unexpectedly, the trend appears to be different, showing a comparable utilization of the platform for both training and inference. Inference is an ongoing process that also requires a significant amount of power.
The power consumption is often correlated with the complexity of the task. It is not easy to measure. As of today, we can track the input and output tokens of the model. You can think of tokens as pieces of words, where approximately 750 words are represented by ~1000 tokens. Pricing is also based on the number of tokens. When we consider this, each prompt can lead to a task with varying complexity. Energy usage is highly correlated with complexity, as a more complex prompt will require more memory and hardware resources. As energy becomes more of a critical aspect and even a limitation, assessing the prompt in terms of complexity might help in finding the most efficient hardware fit and provide insights about the required power.
LLM application profiles
Currently, an interesting approach is the use of LLM application profiles. With LLM application profiles, users can be categorized according to the complexity of their queries. This enables matching the complexity of the query with the required or more specialized compute power. Here you can see a categorization of four different use cases with respect to whether the user query requires more prompt or generation-oriented processing: Content Creation, Prompt Engineering, Summarization, and Chatbot.
An optimization related to this is Splitwise. Splitwise introduces the concept of Phase Splitting, which separates the prompt computation and token-generation phases. This is intended to optimally utilize available hardware and parallelize as well. User can refer to Splitwise improves GPU usage by splitting LLM inference phases – Microsoft Research
Project Forge
Recent work like Project Forge showed that using a specialized GPU/accelerator could also be possible and optimal. Forge is a resource manager that can schedule across GPUs/accelerators. It has a global scheduler on one global hardware fleet CPUs and GPUs. The GPUs are clustered with High bandwidth network – Infiniband – to provide a good quality connectivity. On layer on top of them are the hypervisors. Networks are taken care of and tuned to be maintained with a high utilization & efficiency.
Models will be available via AI Frameworks like ONNIX, Deepspeed (to train), Azure OpenAI on top of custom kernels and different kernel libraries. This will provide the user the opportunity to use different and specialized accelerators on NVIDIA, AMD GPUs and Maia.
What runs ChatGPT? Inside Microsoft’s AI supercomputer | Featuring Mark Russinovich
What to learn?
Training Dataset
You don’t want your kids to see harmful content or to go to locations where they might witness non-exemplary behaviour. The same applies to AI models. When a model is exposed to harmful elements or biased content during its training, it might also reflect that in its learned behaviour. You should keep your model away from the toxic junk on the internet.
Even if you protect your kid/model from harmful content, a bad actor/malicious user can still attempt to interact with it for their own purposes. A recent article by Crescendo reveals an interesting case of a ‘jailbreak’ as well, where a user tries to convince/fool the model into saying harmful information. This reported behaviour showcases how complex it can be to draw the lines.
What to unlearn? (forget)
Above, we talked mostly about training and learning. But what about forgetting? We can refer to this as ‘unlearning‘ by AI models. The concept of enabling models to forget involves generating a process, after training, that allows them to unlearn information associated with content that needs to be removed from the training data. I think this is promising, as it can be used to unlearn harmful or biased content. Furthermore, it can be utilized for protecting intellectual property (IP).
The question here is: While the model unlearns certain content, can it still perform as well as before on tasks that are unrelated to that content? The paper presents promising results, reporting that performance on benchmarks remains comparable.
Who’s Harry Potter? Making LLMs forget – Microsoft Research
A second, related question arises: How big does the model need to be to continue performing the task effectively? The user can refer to for further insights: TinyStories: How Small Can Language Models Be and Still Speak Coherent English? – Microsoft Research
Unlearning information, characters, events, and items related to the person/event, while carrying forward valuable and helpful configurations, allows the model to continue performing the task effectively.
Today, we often view models as a black box, lacking the capability to fully understand them due to their complexity. The reasoning behind the model’s output and interpretability is the focus here, to make AI more explainable. In research, this direction is referred to as Explainable AI. I think that, among all the new research directions above, the new fine-tuning adapters, forgetting capabilities, multi-modality, and the ideal model size will help us gain some insights and unlock some mysteries with efficient learning to perform the tasks. In parallel, this also unlocks new possibilities in GPU usage as a consequence.
all the images in this post are AI-generated – by Copilot Designer.
Microsoft Tech Community – Latest Blogs –Read More
Stop m365 access from personal laptops
I want to block my users ability to access corporate outlook, excel, teams, SharePoint when they open the portal.office.com from their personal laptop. What is the method of doing this please?
I want to block my users ability to access corporate outlook, excel, teams, SharePoint when they open the portal.office.com from their personal laptop. What is the method of doing this please? Read More







