

Month: January 2024

Introducing the SharePoint Embedded Visual Studio Code extension
Microsoft SharePoint Embedded is a new API-only solution that enables app developers to harness the power of the Microsoft 365 file and document storage platform for any app, and is suitable for enterprises building line of business applications and ISVs building multitenant applications. SharePoint Embedded is part of the Microsoft advanced content management and experiences portfolio, which also includes SharePoint Premium, Microsoft 365 Backup, and Microsoft 365 Archive.
Today, we are excited to announce the preview release of the SharePoint Embedded Visual Studio Code extension, a new tool that helps developers get started with SharePoint Embedded application development.
What can you do with the SharePoint Embedded Visual Studio Code extension?
• Create and configure Azure Entra app registrations for use with SharePoint Embedded
• Create and manage free trial container types
• Create additional guest apps on a free trial container type
• Load one of the sample apps and auto-populate its runtime configuration
• Export Container Type and Azure Entra app settings to a Postman Environment file for use with the SharePoint Embedded Postman Collection
The SharePoint Embedded Visual Studio Code extension is also designed to work with the SharePoint Embedded Postman Collection, a set of pre-configured requests that help you interact with the SharePoint Embedded REST API. You can use the Postman Collection to test your SharePoint Embedded applications, perform operations on container types and guest apps, and explore SharePoint Embedded features and capabilities.
How to get started with the SharePoint Embedded Visual Studio Code extension?
To get started with the SharePoint Embedded Visual Studio Code extension, you need Visual Studio Code installed on your machine.
Next, install the SharePoint Embedded Visual Studio Code extension from the Visual Studio Marketplace. You can find the extension by searching for “SharePoint Embedded” in the Visual Studio Code Extensions view, or by visiting the link above.
Once you have installed the extension, you can access it from the Visual Studio Code Activity Bar, where you will see a new icon for SharePoint Embedded. Clicking on the icon will open the SharePoint Embedded view, where you can perform various tasks related to SharePoint Embedded application development.
Sign In
In order to use this extension, you’ll need to sign into a Microsoft 365 tenant with an administrator account. Also, if you haven’t done so already, enable SharePoint Embedded on your Microsoft 365 tenant.
If you don’t have administrator access to a Microsoft 365 tenant, get your own tenant with the Microsoft 365 Developer Program.
Create a Free Trial Container Type
Once you’ve signed in, the first (and only) thing to do is to create a free trial container type. A free trial container type lets you get started calling SharePoint Embedded APIs and building a proof-of-concept application using SharePoint Embedded.
Create an Azure Entra (AD) App
Every container type is owned by an Azure Entra (AD) application. The first step when creating a free trial container type is to create a new or select an existing Azure Entra application as the owning application. You can either specify the name of your new application or pick one of your existing applications.
Note that if you choose an existing application, the extension will update that app’s configuration settings in order for it to work with both SharePoint Embedded and this extension. Doing this is NOT recommended on production applications.
Name your Free Trial Container Type
Once you have an Azure Entra application, the last step is to provide a name for your new free trial container type.
Load Sample App
With a free trial container type created, you can use the extension to load one of the SharePoint Embedded sample apps and automatically populate the runtime configuration file with the details of your Azure Entra app and container type. This allows you to immediately run the sample app on your local machine using the instructions located in the README.md file in each sample app.
Export Postman Environment
The SharePoint Embedded Postman Collection allows you to explore and call the SharePoint Embedded APIs. The Collection requires an environment file with variables used for authentication and various identifiers. This extension automates the generation of this populated environment file so you can import it into Postman and immediately call the SharePoint Embedded APIs.
Add a Guest App to your Free Trial Container Type
You can use the extension to add one or more guest apps on your existing free trial container type. Guest apps can be used to create different applications that have access to the same set of Containers. For example, you might have one app that delivers your Web experiences, another for mobile experiences, and another for background processing. You can specify both the delegated and application permissions on each guest application you create.
Learn More
• Sign up for the SharePoint Embedded preview and get product updates
• Join us for our monthly Microsoft advanced content management community calls – keep an eye out for the March call focusing on SharePoint Embedded!
• Learn more about Microsoft content management
• Meet us at an upcoming event around the world such as AIIM24 and Microsoft 365 Conference
Microsoft Tech Community – Latest Blogs –Read More
What’s New in Microsoft Teams | January 2024
In our January 2024 edition of What’s New in Microsoft Teams, we are highlighting 33 new features and enhancements to Microsoft Teams. These updates will help you collaborate more effectively, streamline workflows, and stay connected with your team. Keep reading to find out more about the latest updates and how they can help you and your organization. From new enhancements to meetings to improvements in chats, Teams Phone, Teams Devices, Platform, and Frontline Workers, there is something for everyone.
Some of my favorite features are Immersive Spaces and Decorate your Background. Immersive Spaces lets you transform your meeting into a 3D immersive experience by allowing your team to join a pre-built immersive space by selecting the view menu in a Teams meeting. Decorate your Background uses AI decorate and customize your real-world room, such as by removing clutter or adding plants to a wall. And this month we announced Intelligent recap is included with the Copilot for Microsoft 365 so users with a Copilot license will now also have access to Intelligent Recap in Teams even if you do not have a Teams Premium license.
And every month we highlight new devices that are certified and ready to use for Teams. You can find more devices for all types of spaces and uses at aka.ms/teamsdevices.
Please check out all the updates and give me your feedback! I’ll try to reply and answer questions as they come up.
IT Administration and Security
Chat and Collaboration
Forward chat messages
Forward chat makes it easier to get your work done with fewer clicks. Share a message with another colleague by right clicking the message and selecting “forward” or by clicking the “…” on the message and then “forward”. You can also add additional context to the message to provide greater clarity for the recipient. Messages can be forwarded to 1:1 chats and group chats.
Meetings
Mesh in Microsoft Teams
To support hybrid work and geographically distributed organizations, we created Microsoft Mesh and integrated it right into Teams.
Mesh in Teams transforms your Teams meeting into a 3D immersive experience using next-generation technology that helps virtual connections feel more like face-to-face ones.
Getting started is easy. From the View menu in a Teams meeting, select the immersive space (3D) option, and enter a pre-built immersive space where you can connect and collaborate with others in 3D and with those in the standard 2D meeting experience. Whether you choose to use Mesh in Teams for a team social gathering, a brainstorming session, or a round-table discussion, you can use the same Teams features you love from within a 3D space, like accessing shared content for collaboration, communicating with Teams chat, and using live reactions to express yourself.
Mesh in Teams enhances your favorite Teams features by making you feel like you are physically co-located with others. Being in the same 3D environment creates a strong feeling of togetherness, or co-presence. This co-presence can spark spontaneous moments of dialogue and strengthen the bond of a shared experience. Visual and audio cues enable a sense of immersion that help keep you in the moment and eliminate external distractions. Spatial Audio and audio zones enable you to have multiple, simultaneous conversations and communicate effectively in subgroups without talking over each other – just like in the physical world.
Mesh in Teams is available with core Teams licenses. Organizations can also host larger events with custom, immersive experiences tailored to their needs with Microsoft Mesh, available through Teams Premium.
Learn more about Mesh in Teams.
Intelligent recap included with Copilot for Microsoft 365 License
If you have a Copilot for Microsoft 365 License you now have intelligent recap for Teams included in your license. Use intelligent recap after meetings to get a summary of the meeting. This summary includes personalized timeline markers to easily browse recordings by when you joined or left, when a screen was shared, and when your name was mentioned. You can also browse recordings by speakers, chapters, and topics as well as access AI-generated meeting notes, tasks, and go to name mentions in the transcript.
Decorate your background
Make meetings more fun and personal with Decorate your background. Meeting participants can now use generative background effects in Teams to show up their best – even when the space they’re working from isn’t at its best. With Decorate your background, meeting participants can use the power of AI to generate a background that decorates and enhances their real-world room, such as by cleaning up clutter or adding plants to a wall. This capability is available for users with a Teams Premium license.
People specific link support for Collaborative notes
With the launch of Collaborative notes, we are making meetings more effective and secure by using a new link type created by Collaborative notes. The new Collaborative notes component will generate a People specific link (PSL) by default. This link type offers more controlled access than a Company specific link (CSL) and aligns with tenants who have their file-sharing policy set as specific people. Tenants who previously had Collaborative notes disabled due to lack of PSL support can now enable and use the feature.
Automatically view up to 9 videos (3×3) in Teams meetings in Chrome and Edge
With this update, you will now be able to automatically see up to 9 videos (3×3) on Chrome and Edge on your screen by default without an explicit action. Previously, Microsoft Teams Meetings supported a maximum of 4 videos (2×2) on the screen by default on web browsers.
Simplified audio and video controls
Audio and video fly-outs in meetings are designed to make it easier and more efficient for you to manage your audio and video settings during Teams meetings. Now, when you want to select your camera or mic device, you can choose the right device directly from the fly-outs. You can also adjust the volume, spatial audio, and noise suppression controls from the audio fly-out. If you didn’t select your background during the pre-join screen, you can easily change your background directly from the camera fly-out. We’ve also made avatars accessible from the camera fly-out so you can use avatars in meetings. You can also adjust brightness and soft focus from the camera fly-out.
Virtual appointments
Assign staff and set duration for on-demand Virtual Appointments
Scheduling administrators and staff managing on-demand appointments can assign specific staff members and set appointment duration to handle on-demand services. This ensures that when an on-demand appointment is requested, there is a designated staff member assigned to the appointment and the duration of the appointment will be determined. The designated staff member also receives a notification to attend the on-demand appointment. This capability is available for users with a Teams Premium license.
SMS notifications in Virtual Appointments template
SMS notifications are available for appointments set up and scheduled using the virtual appointments template within the Teams app to improve the attendees’ appointment experience. Attendees will receive SMS text notifications about their appointment, including appointment details and the meeting join link so they can join directly from mobile if desired. Text notifications are sent for appointment confirmation, updates, and a reminder 15 minutes before the appointment begins. This capability is available for users with a Teams Premium license and is available for users in Canada, United Kingdom, and United States.
Teams Rooms and Devices
Find Certified for Teams devices for all types of spaces and uses at aka.ms/teamsdevices.
Newly certified for Teams AVer VB350
With a Hybrid 18X Zoom for Medium & Large Rooms With a streamlined design, dual 4K lenses, seamless lens switching, upgraded audio technology, and simple setup, the VB350 is the ultimate all-in-one solution for next-level video meetings. Level up to premium audio and video by using this powerful new video bar in your mid-to-large conference rooms. Learn more about AVer – VB350.
Newly certified for Teams Lenovo ThinkSmart 180
This premium conference bar delivers superior audio and visual experience featuring a modern form factor and best-in-class AI-accelerated performance. This stylish and easy-to-set-up meeting room bar will transform your small and medium-sized meeting rooms into next-generation collaboration spaces in no time at all. Impressive AI features follow the conversation, adjusting the view and audio to allow remote participants to feel like they’re sitting around the table, even if they’re across the world. Learn more about Smart Collaboration | Lenovo Tech today.
AudioCodes RXV200-B20 bundle is now certified for Teams
The RXV200 bundle is designed to deliver an optimal hybrid meeting experience for focus rooms and includes the RXV200 intelligent A/V hub, the RX-PAD touch room controller, the RXVCam50 camera and RX15 speaker. The RXV200 is an Android Microsoft Teams Rooms device that orchestrates multiple audio and video peripherals to deliver an optimal hybrid meeting experience for all participants wherever they are located. The RXV200’s modular design supports content sharing, allowing participants to connect their personal devices via an HDMI cable, as well as dual screens and a wide range of AI capabilities. Learn more about AudioCodes RXV200 bundles.
AudioCodes RXVCam10-CC
AudioCodes RXVCam10-CC content camera is now certified for Teams. The RXVCam10-CC enables whiteboard content to be easily shared between physically present and remote meeting participants. In conjunction with Microsoft Teams AI content enhancement capabilities, the RXVCam10-CC simplifies team collaboration and brainstorming in hybrid meetings. Leveraging Microsoft Teams AI, the RXVCam10-CC offers intelligent whiteboard detection and automatically adjusts the frame to include the entire whiteboard. It also offers additional content enhancements such as image sharpening, contrast adjustment and overlaying a transparent view of the presenter. The RXVCam10-CC is designed for durability and is easy to install in any meeting room thanks to its adjustable whiteboard mount accessory.
Learn more about RXVCam10-CC.
Management of BYOD (Bring your own device) meeting spaces with Teams Rooms Pro Management
The ability to view BYOD (bring your own device) rooms in the Pro Management Portal provides IT admins with a comprehensive overview of their BYOD rooms’ utilization and activities. With this new addition, IT admins will gain valuable insights into how these spaces are being utilized, enabling them to make data driven decisions.
New Shared display mode for BYOD meeting rooms
The new shared display mode provides you the ability to extend your Teams meeting via a pop-out and view-only version of the stage onto the TV screen in BYOD meeting rooms. This mode ensures the meeting content is extended to the front of the room for others to see and provides you the peace of mind that your desktop is for their viewing only, minimizing the personal information others in the room can see.
Teams Phone
New partner integrations for Teams Phone contact center
The Teams Phone contact center and compliance recording certification programs ensure that contact center and compliance recording solutions work smoothly and dependably with Teams by requiring them to pass third-party testing. We have recently certified two new ISV partners, BrightPattern and CenterPal. With these additions we now have 24 Contact Center certified solution partners and 13 Compliance Recording certified solution partners, and there are many more on the way.
Mobile
Updates to mobile in-call user experience
Improving your access to calling features with a new and improved user interface during calls.
Live meeting status for mobile
On mobile devices, Teams calendar shows the live status of a meeting with the pictures of the people who are on the call, if the meeting is being recorded and how long the meeting has lasted.
Play Azure protected voicemail in mobile Teams app
You can now use a link to get to your Azure protected voicemails from the Teams App. You will see a notification for the voicemail on the Teams App and can click the attached link to open the voicemail on the web browser.
Collaborative Apps
1Page
The 1Page app is the all-in-one productivity tool that creates a platform to empower sales professionals by connecting them with data, insights, and even prospective or existing customers. Now, with a co-pilot plugin, streamlined data and real-time insights can be accessed from the 1Page app with conversational language prompts across the Microsoft 365 ecosystem.
Alvao
Alvao for Microsoft Teams automates routine processes, boosts team productivity, and helps users focus on key projects. With the latest extension into Microsoft 365 applications, tickets opened in outlook can more easily connect with an agent. The app helps with logging chat messages to tickets, creating a simple to track list of tickets to solve, and gives agents the ability to take and resolve tickets immediately.
Calm
Calm for Microsoft Teams integrates the #1 app for sleep, meditation, and relaxation into your everyday workflow. Calm’s mindfulness content helps you feel more relaxed, productive, and connected by allowing you to engage with more than 3,000 Calm sessions within the Teams interface. This includes content to prepare for key moments at work, music to help focus, breathing exercises, movement, and more. You can access mindfulness sessions for yourself or with others during meetings, share mindfulness content via chat, and set reminders for mental health breaks to help reduce stress and anxiety, reset, refocus, and build resilience.
Planning for Educators
Planning for Educators gives users the tools to streamline the planning process in Microsoft Teams so they can spend more time focusing on teaching. This flexible planning tool allows educators to organize and manage class resources including lesson plans, assignments, files, videos, and links. Students can also benefit from Planning’s comprehensive visual timeline and content made more accessible through Microsoft’s Immersive Reader.
SYNQ Frontline Hero
The SYNQ Frontline Hero app brings SYNQ’s retail services to Microsoft Teams to connect retail store staff with customers at the speed and convenience of Teams. Staff can use this to efficiently manage in-store and curbside pickup orders, quickly answer customer queries in chat, and respond to requests for staff assistance or customer service.
IT Administration and Security
Configure maintenance window for Teams devices
Within the Teams Admin Center, admins can set up the time windows for their Teams devices maintenance. These time windows will be used for performing any device maintenance tasks, such as automatic updates.
Extended real-time telemetry retention for up to 7 days
Admins in Teams admin center can troubleshoot meeting quality more efficiently thanks to real-time telemetry that is available for an extended period (up to 7 days following the conclusion of a meeting) for users with Teams Premium licenses. This helps admins find and solve quality issues with detailed telemetry after the meeting for up to 7 days. s This feature is available with a Teams Premium license.
Microsoft Teams admin center – external domain activity report
Teams administrators can see which managed domains their users interact with using the external domain activity report. The report will surface the list of domains that your tenant has communicated with via managed communication, and how many internal users have been part of that communication. This report is available for those with open federation on and those with explicit allow lists.
Watermark support for recording playback
Watermarked meetings can now have recording enabled. A watermark with an email ID will show up during the playback of the recorded meeting. After a meeting is over, users can view the recorded content with watermarking on web and mobile platforms. This feature requires a Teams Premium license.
New Meeting Option and Meeting Policy ‘Turn off copying or forwarding of meeting chat’
A new meeting option called ‘Turn off copying or forwarding of meeting chat’ lets the meeting organizer disable the ability to copy and share meeting chat messages for participants to prevent data leakage. With this restriction on, meeting participants will not be able to copy chat messages using the menu option or keyboard shortcut, forward messages, or share messages to Outlook. Admins can control whether an organizer can use this feature in the Meeting Options page by using Meeting Policy setting in Teams admin center. Admins can also choose the default value for this meeting option in Meeting Templates they create. This feature requires a Teams Premium license.
Frontline Worker Solutions
Walkie Talkie: Automatically listen to multiple channels
Frontline workers who use Walkie Talkie in Teams can now choose to automatically listen to incoming messages from any of their pinned favorite Teams channels (up to 5 favorite channels). This new feature helps you keep in touch with and easily initiate PTT transitions on multiple channels without needing to switch channels manually.
Allow frontline teams to set their shift availability for specific dates
Frontline workers can now choose their preferred dates to work, making it easier for them to handle different scheduling needs. This new feature adds to the existing options for weekly availability that repeat. To learn more about recent enhancements to Shifts in Teams, read the latest blog – Discover the latest enhancements in Microsoft Shifts.
Microsoft Tech Community – Latest Blogs –Read More
Azure AI Speech launches new zero-shot TTS models for Personal Voice
At the Ignite conference on Nov 15, 2023, we announced the public preview of Personal Voice, which is specifically designed to enable customers to build apps that allow their users to easily create and use their own AI voices (see the blog).
Today we’re thrilled to announce that Azure AI Speech Service has upgraded its Personal Voice feature with new zero-shot TTS (text-to-speech) models. Compared to the initial model, these new models improve the naturalness of synthesized voices and better resemble the speech characteristics of the voice in the prompt.
In this blog, we’ll explore how new zero-shot TTS models enable users to create a more natural sounding voice that captures their unique speech characteristics. We’ll also provide a step-by-step guide on how to integrate the personal voice capability into your apps using the Personal Voice API with different zero-shot TTS models.
Zero-shot model upgrades
The Personal Voice capability in Azure AI Speech Service allows customers to create personalized synthetic voices for their users based on their unique speech characteristics. With Personal Voice, users can get AI replicating their voice in a few seconds by providing just a short speech sample as the audio prompt, and then use it to generate speech in any of the 100 languages supported. This feature can be used for various use cases, such as personalizing voice experience for a chatbot, or dubbing video content in different languages with the actor’s native voice.
Zero-shot TTS or foundation TTS models have evolved rapidly in the past year. The industry and academia have proposed various approaches to advance the technology, including Microsoft’s state-of-the-art research models such as VALL-E (X) , FoundationTTS, NaturalSpeech 2 etc. These models are typically trained with large amounts of speech data to cover different text content and voice characteristics, such as timbre, speech styles and accents. With that, the model can gain the zero-shot text-to-speech ability to clone a voice with very little data of target speakers through modules such as auto-regressive transformers or diffusion.
Every model has its strengths and weaknesses, and we understand each customer’s needs are unique. We offer a variety of base models for Personal Voice customers to choose from based on their specific scenarios. Our latest addition, the “DragonLatestNeural” model, features cutting-edge technology that allows for more realistic prosody, higher fidelity, and personalized voices that mimic the nuances of the human speaker in the prompt, with various speech characteristics. This model is currently optimized for content generation scenarios where expressiveness is highly demanded, and latency is of less concern. Our updated “PhoenixLatestNeural” model also enhances the similarity of voice to the human speaker, while maintaining low-latency performance and higher pronunciation accuracy, making it ideal for real-time scenarios. Both models have undergone significant improvements and have been trained in 10x more data than the previous “PhoenixV2Neural” model.
Here are a few voice samples with different speaking styles, generated from the latest Dragon model:
Audio prompt (human voice)
Style
Generated speech and the script
Voice assistant
Good morning! Today’s weather is sunny with a high of 75 degrees. You have two meetings scheduled and a reminder to call your mom. How can I assist you further?
News
In today’s news, a major breakthrough in renewable energy has been achieved by researchers at the GreenTech Innovation Lab. The team, led by Dr. Emily Huang, announced the development of a new solar panel technology that promises to double the efficiency of current models. This significant advancement could lead to a substantial reduction in solar energy costs.
Conversation
Hey, um, everyone, it’s Lisa. So, about dinner tonight, uh, I’m trying to decide whether to cook or maybe order something. I’m thinking, uh, pasta with garlic bread sounds good, but then I saw this new Thai place nearby, and their menu looks really tempting.
Whisper
Sure, here is the note. What else can I do for you?
Excited
Guess what? I just won the lottery – we’re going on a dream vacation!
Shout
Watch out! The ball is heading right towards you!
Story
The moment water started flooding in from the kitchen, I dropped my tools and gasped, “Shit, shit, shit!” instantly realizing my day had taken a turn for the worse.
Below are samples of two voices speaking different languages with zero-shot TTS:
Female
Male
Prompt
Prompt
朋友们,你们真是太给力了。昨天我发了一条视频,希望有人来关注我,结果真的有很多朋友关注我了。我内心非常激动,而且还有人私信我说喜欢我,这让我很感动,感受到了大伙们的友善,谢谢你们!
Okay, um, so, like, I was, uh, trying to, you know, explain this thing to, um, my friend the other day, and, well, I just couldn’t, like, find the right, uh, words? And then, you know, I thought maybe, um, I was just, kind of, overthinking it or, um, something. It’s just, uh, sometimes hard to, you know, put thoughts into, um, words, you know? How was that? Anything else on your mind?
Once upon a time, there was a little rabbit named Benny. Benny loved to hop around in the fields and nibble on carrots. One day, while he was out exploring, he stumbled upon a beautiful garden filled with all sorts of delicious vegetables.
C’era una volta un piccolo coniglio di nome Benny. A Benny piaceva saltellare nei campi e rosicchiare le carote. Un giorno, mentre esplorava, incappò in un bellissimo giardino pieno di verdure deliziose. Benny non riuscì a resistere e iniziò a mangiare la fresca lattuga e i pomodori succosi.
Customer case
GRUP MEDIAPRO, a global media company and the leader of the European audiovisual market, has partnered with Microsoft to respond to the profound transformations in the media sector brought about by AI. In a recent announcement at the ISE fair on Jan 30th, the company unveiled its Artificial Intelligence and Synthetic Media Laboratory, which has been developed in partnership with Microsoft, as part of its commitment to innovation (read the news here).
The lab leverages the latest advances in AI, including zero-shot TTS, to support research and solution development in fields such as personalization of audiovisual and digital content, voice cloning, and video processing. GRUP MEDIAPRO and Microsoft approach this collaboration with a people-centered focus, while remaining committed to legal commitments and ethical principles in the development, deployment, and use of Artificial Intelligence solutions.
You can listen to the story in the CEO’s own personal voice, which was created using the Dragon zero-shot TTS model, in Chinese and Arabic. Tatxo Benet, the CEO, leads the way in showcasing the capabilities of this new technology, which has enabled him to reach to a global audience with the languages he doesn’t speak himself.
How to use it
As part of Microsoft’s commitment to responsible AI, Personal Voice is designed with the intention of protecting the rights of individuals and society, fostering transparent human-computer interaction, and counteracting the proliferation of harmful deepfakes and misleading content. For this reason, Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To access the API and use the feature in your business applications, register your use case here and apply for the access.
Once you’ve got your access, you can start to build your personal voice project. Use the Projects_Create operation of the custom voice API, to create a personal voice project. Check out more instructions here.
Then you can follow these steps to create a personal voice using zero-shot TTS with the Dragon model.
First, you’ll need to provide the user’s consent for creating a voice profile.
With the Personal Voice feature, it’s required that every voice be created with explicit consent from the user. A recorded statement from the user is required acknowledging that the customer (Azure AI Speech resource owner) will create and use their voice. You can find the template of the verbal statement in different languages here.
Follow the samples here to add a consent from a file or from a URL.
Once you’ve given consent, you can record and upload your voice samples to create a speaker profile ID.
To use Personal Voice in your application, you need to get a speaker profile ID. The speaker profile ID is used to generate synthesized audio with the text input provided. You create a speaker profile ID based on the speaker’s verbal consent statement and an audio prompt.
Follow the code samples here to create a speaker profile ID from a file or from a URL.
After the voice profile ID is created, you can use the zero-shot TTS feature with the selected base model to synthesize speech that matches your natural speaking style, intonation, and accent.
To get a list of supported base model voice names, use the BaseModels_List operation of the custom voice API. Note that DragonLastNeural and PhoenixLastNeural are evolving models. Their performance may vary with updates for ongoing improvements. PhoenixV2Neural is stable without further updates, ensuring a consistent performance. Select the base model that best meets your needs, and use the speaker profile ID to synthesize speech in any of the 100 languages supported.
A locale tag isn’t required in the SSML when using zero-shot TTS. Personal Voice employs automatic language detection at the sentence level. Below is an SSML example using DragonLatestNeural to generate speech for your personal voice in different languages. More details are provided here.
<speak version=’1.0′ xmlns=’http://www.w3.org/2001/10/synthesis’ xmlns:mstts=’http://www.w3.org/2001/mstts’ xml:lang=’en-US’>
<voice name=’DragonLatestNeural’>
<mstts:ttsembedding speakerProfileId=’your speaker profile ID here’>
I’m happy to hear that you find me amazing and that I have made your trip planning easier and more fun. 我很高兴听到你觉得我很了不起,我让你的旅行计划更轻松、更有趣。Je suis heureux d’apprendre que vous me trouvez incroyable et que j’ai rendu la planification de votre voyage plus facile et plus amusante.
</mstts:ttsembedding>
</voice>
</speak>
All customers must comply with the Guidelines for responsible deployment of synthetic voice technology and the code of conduct when using the service.
Get started
With the newly released zero-shot TTS models, the Personal Voice feature of Azure AI Speech is upgraded with higher quality. It generates speech that well captures the nuances of the user’s natural speech. Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To get started, register your use case here and apply for the access.
In addition to creating personal voices for your users, you can create a brand voice for your business with Custom Neural Voice’s professional voice feature. Azure AI Speech also offers over 400 neural voices covering more than 140 languages and locales. With these pre-built text-to-speech voices, you can quickly add read-aloud functionality for a more accessible app design or give a voice to chatbots to provide a richer conversational experience to your users.
Microsoft Tech Community – Latest Blogs –Read More
Azure AI Speech launches new zero-shot TTS models for Personal Voice
At the Ignite conference on Nov 15, 2023, we announced the public preview of Personal Voice, which is specifically designed to enable customers to build apps that allow their users to easily create and use their own AI voices (see the blog).
Today we’re thrilled to announce that Azure AI Speech Service has upgraded its Personal Voice feature with new zero-shot TTS (text-to-speech) models. Compared to the initial model, these new models improve the naturalness of synthesized voices and better resemble the speech characteristics of the voice in the prompt.
In this blog, we’ll explore how new zero-shot TTS models enable users to create a more natural sounding voice that captures their unique speech characteristics. We’ll also provide a step-by-step guide on how to integrate the personal voice capability into your apps using the Personal Voice API with different zero-shot TTS models.
Zero-shot model upgrades
The Personal Voice capability in Azure AI Speech Service allows customers to create personalized synthetic voices for their users based on their unique speech characteristics. With Personal Voice, users can get AI replicating their voice in a few seconds by providing just a short speech sample as the audio prompt, and then use it to generate speech in any of the 100 languages supported. This feature can be used for various use cases, such as personalizing voice experience for a chatbot, or dubbing video content in different languages with the actor’s native voice.
Zero-shot TTS or foundation TTS models have evolved rapidly in the past year. The industry and academia have proposed various approaches to advance the technology, including Microsoft’s state-of-the-art research models such as VALL-E (X) , FoundationTTS, NaturalSpeech 2 etc. These models are typically trained with large amounts of speech data to cover different text content and voice characteristics, such as timbre, speech styles and accents. With that, the model can gain the zero-shot text-to-speech ability to clone a voice with very little data of target speakers through modules such as auto-regressive transformers or diffusion.
Every model has its strengths and weaknesses, and we understand each customer’s needs are unique. We offer a variety of base models for Personal Voice customers to choose from based on their specific scenarios. Our latest addition, the “DragonLatestNeural” model, features cutting-edge technology that allows for more realistic prosody, higher fidelity, and personalized voices that mimic the nuances of the human speaker in the prompt, with various speech characteristics. This model is currently optimized for content generation scenarios where expressiveness is highly demanded, and latency is of less concern. Our updated “PhoenixLatestNeural” model also enhances the similarity of voice to the human speaker, while maintaining low-latency performance and higher pronunciation accuracy, making it ideal for real-time scenarios. Both models have undergone significant improvements and have been trained in 10x more data than the previous “PhoenixV2Neural” model.
Here are a few voice samples with different speaking styles, generated from the latest Dragon model:
Audio prompt (human voice)
Style
Generated speech and the script
Voice assistant
Good morning! Today’s weather is sunny with a high of 75 degrees. You have two meetings scheduled and a reminder to call your mom. How can I assist you further?
News
In today’s news, a major breakthrough in renewable energy has been achieved by researchers at the GreenTech Innovation Lab. The team, led by Dr. Emily Huang, announced the development of a new solar panel technology that promises to double the efficiency of current models. This significant advancement could lead to a substantial reduction in solar energy costs.
Conversation
Hey, um, everyone, it’s Lisa. So, about dinner tonight, uh, I’m trying to decide whether to cook or maybe order something. I’m thinking, uh, pasta with garlic bread sounds good, but then I saw this new Thai place nearby, and their menu looks really tempting.
Whisper
Sure, here is the note. What else can I do for you?
Excited
Guess what? I just won the lottery – we’re going on a dream vacation!
Shout
Watch out! The ball is heading right towards you!
Story
The moment water started flooding in from the kitchen, I dropped my tools and gasped, “Shit, shit, shit!” instantly realizing my day had taken a turn for the worse.
Below are samples of two voices speaking different languages with zero-shot TTS:
Female
Male
Prompt
Prompt
朋友们,你们真是太给力了。昨天我发了一条视频,希望有人来关注我,结果真的有很多朋友关注我了。我内心非常激动,而且还有人私信我说喜欢我,这让我很感动,感受到了大伙们的友善,谢谢你们!
Okay, um, so, like, I was, uh, trying to, you know, explain this thing to, um, my friend the other day, and, well, I just couldn’t, like, find the right, uh, words? And then, you know, I thought maybe, um, I was just, kind of, overthinking it or, um, something. It’s just, uh, sometimes hard to, you know, put thoughts into, um, words, you know? How was that? Anything else on your mind?
Once upon a time, there was a little rabbit named Benny. Benny loved to hop around in the fields and nibble on carrots. One day, while he was out exploring, he stumbled upon a beautiful garden filled with all sorts of delicious vegetables.
C’era una volta un piccolo coniglio di nome Benny. A Benny piaceva saltellare nei campi e rosicchiare le carote. Un giorno, mentre esplorava, incappò in un bellissimo giardino pieno di verdure deliziose. Benny non riuscì a resistere e iniziò a mangiare la fresca lattuga e i pomodori succosi.
Customer case
GRUP MEDIAPRO, a global media company and the leader of the European audiovisual market, has partnered with Microsoft to respond to the profound transformations in the media sector brought about by AI. In a recent announcement at the ISE fair on Jan 30th, the company unveiled its Artificial Intelligence and Synthetic Media Laboratory, which has been developed in partnership with Microsoft, as part of its commitment to innovation (read the news here).
The lab leverages the latest advances in AI, including zero-shot TTS, to support research and solution development in fields such as personalization of audiovisual and digital content, voice cloning, and video processing. GRUP MEDIAPRO and Microsoft approach this collaboration with a people-centered focus, while remaining committed to legal commitments and ethical principles in the development, deployment, and use of Artificial Intelligence solutions.
You can listen to the story in the CEO’s own personal voice, which was created using the Dragon zero-shot TTS model, in Chinese and Arabic. Tatxo Benet, the CEO, leads the way in showcasing the capabilities of this new technology, which has enabled him to reach to a global audience with the languages he doesn’t speak himself.
How to use it
As part of Microsoft’s commitment to responsible AI, Personal Voice is designed with the intention of protecting the rights of individuals and society, fostering transparent human-computer interaction, and counteracting the proliferation of harmful deepfakes and misleading content. For this reason, Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To access the API and use the feature in your business applications, register your use case here and apply for the access.
Once you’ve got your access, you can start to build your personal voice project. Use the Projects_Create operation of the custom voice API, to create a personal voice project. Check out more instructions here.
Then you can follow these steps to create a personal voice using zero-shot TTS with the Dragon model.
First, you’ll need to provide the user’s consent for creating a voice profile.
With the Personal Voice feature, it’s required that every voice be created with explicit consent from the user. A recorded statement from the user is required acknowledging that the customer (Azure AI Speech resource owner) will create and use their voice. You can find the template of the verbal statement in different languages here.
Follow the samples here to add a consent from a file or from a URL.
Once you’ve given consent, you can record and upload your voice samples to create a speaker profile ID.
To use Personal Voice in your application, you need to get a speaker profile ID. The speaker profile ID is used to generate synthesized audio with the text input provided. You create a speaker profile ID based on the speaker’s verbal consent statement and an audio prompt.
Follow the code samples here to create a speaker profile ID from a file or from a URL.
After the voice profile ID is created, you can use the zero-shot TTS feature with the selected base model to synthesize speech that matches your natural speaking style, intonation, and accent.
To get a list of supported base model voice names, use the BaseModels_List operation of the custom voice API. Note that DragonLastNeural and PhoenixLastNeural are evolving models. Their performance may vary with updates for ongoing improvements. PhoenixV2Neural is stable without further updates, ensuring a consistent performance. Select the base model that best meets your needs, and use the speaker profile ID to synthesize speech in any of the 100 languages supported.
A locale tag isn’t required in the SSML when using zero-shot TTS. Personal Voice employs automatic language detection at the sentence level. Below is an SSML example using DragonLatestNeural to generate speech for your personal voice in different languages. More details are provided here.
<speak version=’1.0′ xmlns=’http://www.w3.org/2001/10/synthesis’ xmlns:mstts=’http://www.w3.org/2001/mstts’ xml:lang=’en-US’>
<voice name=’DragonLatestNeural’>
<mstts:ttsembedding speakerProfileId=’your speaker profile ID here’>
I’m happy to hear that you find me amazing and that I have made your trip planning easier and more fun. 我很高兴听到你觉得我很了不起,我让你的旅行计划更轻松、更有趣。Je suis heureux d’apprendre que vous me trouvez incroyable et que j’ai rendu la planification de votre voyage plus facile et plus amusante.
</mstts:ttsembedding>
</voice>
</speak>
All customers must comply with the Guidelines for responsible deployment of synthetic voice technology and the code of conduct when using the service.
Get started
With the newly released zero-shot TTS models, the Personal Voice feature of Azure AI Speech is upgraded with higher quality. It generates speech that well captures the nuances of the user’s natural speech. Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To get started, register your use case here and apply for the access.
In addition to creating personal voices for your users, you can create a brand voice for your business with Custom Neural Voice’s professional voice feature. Azure AI Speech also offers over 400 neural voices covering more than 140 languages and locales. With these pre-built text-to-speech voices, you can quickly add read-aloud functionality for a more accessible app design or give a voice to chatbots to provide a richer conversational experience to your users.
Microsoft Tech Community – Latest Blogs –Read More
Azure AI Speech launches new zero-shot TTS models for Personal Voice
At the Ignite conference on Nov 15, 2023, we announced the public preview of Personal Voice, which is specifically designed to enable customers to build apps that allow their users to easily create and use their own AI voices (see the blog).
Today we’re thrilled to announce that Azure AI Speech Service has upgraded its Personal Voice feature with new zero-shot TTS (text-to-speech) models. Compared to the initial model, these new models improve the naturalness of synthesized voices and better resemble the speech characteristics of the voice in the prompt.
In this blog, we’ll explore how new zero-shot TTS models enable users to create a more natural sounding voice that captures their unique speech characteristics. We’ll also provide a step-by-step guide on how to integrate the personal voice capability into your apps using the Personal Voice API with different zero-shot TTS models.
Zero-shot model upgrades
The Personal Voice capability in Azure AI Speech Service allows customers to create personalized synthetic voices for their users based on their unique speech characteristics. With Personal Voice, users can get AI replicating their voice in a few seconds by providing just a short speech sample as the audio prompt, and then use it to generate speech in any of the 100 languages supported. This feature can be used for various use cases, such as personalizing voice experience for a chatbot, or dubbing video content in different languages with the actor’s native voice.
Zero-shot TTS or foundation TTS models have evolved rapidly in the past year. The industry and academia have proposed various approaches to advance the technology, including Microsoft’s state-of-the-art research models such as VALL-E (X) , FoundationTTS, NaturalSpeech 2 etc. These models are typically trained with large amounts of speech data to cover different text content and voice characteristics, such as timbre, speech styles and accents. With that, the model can gain the zero-shot text-to-speech ability to clone a voice with very little data of target speakers through modules such as auto-regressive transformers or diffusion.
Every model has its strengths and weaknesses, and we understand each customer’s needs are unique. We offer a variety of base models for Personal Voice customers to choose from based on their specific scenarios. Our latest addition, the “DragonLatestNeural” model, features cutting-edge technology that allows for more realistic prosody, higher fidelity, and personalized voices that mimic the nuances of the human speaker in the prompt, with various speech characteristics. This model is currently optimized for content generation scenarios where expressiveness is highly demanded, and latency is of less concern. Our updated “PhoenixLatestNeural” model also enhances the similarity of voice to the human speaker, while maintaining low-latency performance and higher pronunciation accuracy, making it ideal for real-time scenarios. Both models have undergone significant improvements and have been trained in 10x more data than the previous “PhoenixV2Neural” model.
Here are a few voice samples with different speaking styles, generated from the latest Dragon model:
Audio prompt (human voice)
Style
Generated speech and the script
Voice assistant
Good morning! Today’s weather is sunny with a high of 75 degrees. You have two meetings scheduled and a reminder to call your mom. How can I assist you further?
News
In today’s news, a major breakthrough in renewable energy has been achieved by researchers at the GreenTech Innovation Lab. The team, led by Dr. Emily Huang, announced the development of a new solar panel technology that promises to double the efficiency of current models. This significant advancement could lead to a substantial reduction in solar energy costs.
Conversation
Hey, um, everyone, it’s Lisa. So, about dinner tonight, uh, I’m trying to decide whether to cook or maybe order something. I’m thinking, uh, pasta with garlic bread sounds good, but then I saw this new Thai place nearby, and their menu looks really tempting.
Whisper
Sure, here is the note. What else can I do for you?
Excited
Guess what? I just won the lottery – we’re going on a dream vacation!
Shout
Watch out! The ball is heading right towards you!
Story
The moment water started flooding in from the kitchen, I dropped my tools and gasped, “Shit, shit, shit!” instantly realizing my day had taken a turn for the worse.
Below are samples of two voices speaking different languages with zero-shot TTS:
Female
Male
Prompt
Prompt
朋友们,你们真是太给力了。昨天我发了一条视频,希望有人来关注我,结果真的有很多朋友关注我了。我内心非常激动,而且还有人私信我说喜欢我,这让我很感动,感受到了大伙们的友善,谢谢你们!
Okay, um, so, like, I was, uh, trying to, you know, explain this thing to, um, my friend the other day, and, well, I just couldn’t, like, find the right, uh, words? And then, you know, I thought maybe, um, I was just, kind of, overthinking it or, um, something. It’s just, uh, sometimes hard to, you know, put thoughts into, um, words, you know? How was that? Anything else on your mind?
Once upon a time, there was a little rabbit named Benny. Benny loved to hop around in the fields and nibble on carrots. One day, while he was out exploring, he stumbled upon a beautiful garden filled with all sorts of delicious vegetables.
C’era una volta un piccolo coniglio di nome Benny. A Benny piaceva saltellare nei campi e rosicchiare le carote. Un giorno, mentre esplorava, incappò in un bellissimo giardino pieno di verdure deliziose. Benny non riuscì a resistere e iniziò a mangiare la fresca lattuga e i pomodori succosi.
Customer case
GRUP MEDIAPRO, a global media company and the leader of the European audiovisual market, has partnered with Microsoft to respond to the profound transformations in the media sector brought about by AI. In a recent announcement at the ISE fair on Jan 30th, the company unveiled its Artificial Intelligence and Synthetic Media Laboratory, which has been developed in partnership with Microsoft, as part of its commitment to innovation (read the news here).
The lab leverages the latest advances in AI, including zero-shot TTS, to support research and solution development in fields such as personalization of audiovisual and digital content, voice cloning, and video processing. GRUP MEDIAPRO and Microsoft approach this collaboration with a people-centered focus, while remaining committed to legal commitments and ethical principles in the development, deployment, and use of Artificial Intelligence solutions.
You can listen to the story in the CEO’s own personal voice, which was created using the Dragon zero-shot TTS model, in Chinese and Arabic. Tatxo Benet, the CEO, leads the way in showcasing the capabilities of this new technology, which has enabled him to reach to a global audience with the languages he doesn’t speak himself.
How to use it
As part of Microsoft’s commitment to responsible AI, Personal Voice is designed with the intention of protecting the rights of individuals and society, fostering transparent human-computer interaction, and counteracting the proliferation of harmful deepfakes and misleading content. For this reason, Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To access the API and use the feature in your business applications, register your use case here and apply for the access.
Once you’ve got your access, you can start to build your personal voice project. Use the Projects_Create operation of the custom voice API, to create a personal voice project. Check out more instructions here.
Then you can follow these steps to create a personal voice using zero-shot TTS with the Dragon model.
First, you’ll need to provide the user’s consent for creating a voice profile.
With the Personal Voice feature, it’s required that every voice be created with explicit consent from the user. A recorded statement from the user is required acknowledging that the customer (Azure AI Speech resource owner) will create and use their voice. You can find the template of the verbal statement in different languages here.
Follow the samples here to add a consent from a file or from a URL.
Once you’ve given consent, you can record and upload your voice samples to create a speaker profile ID.
To use Personal Voice in your application, you need to get a speaker profile ID. The speaker profile ID is used to generate synthesized audio with the text input provided. You create a speaker profile ID based on the speaker’s verbal consent statement and an audio prompt.
Follow the code samples here to create a speaker profile ID from a file or from a URL.
After the voice profile ID is created, you can use the zero-shot TTS feature with the selected base model to synthesize speech that matches your natural speaking style, intonation, and accent.
To get a list of supported base model voice names, use the BaseModels_List operation of the custom voice API. Note that DragonLastNeural and PhoenixLastNeural are evolving models. Their performance may vary with updates for ongoing improvements. PhoenixV2Neural is stable without further updates, ensuring a consistent performance. Select the base model that best meets your needs, and use the speaker profile ID to synthesize speech in any of the 100 languages supported.
A locale tag isn’t required in the SSML when using zero-shot TTS. Personal Voice employs automatic language detection at the sentence level. Below is an SSML example using DragonLatestNeural to generate speech for your personal voice in different languages. More details are provided here.
<speak version=’1.0′ xmlns=’http://www.w3.org/2001/10/synthesis’ xmlns:mstts=’http://www.w3.org/2001/mstts’ xml:lang=’en-US’>
<voice name=’DragonLatestNeural’>
<mstts:ttsembedding speakerProfileId=’your speaker profile ID here’>
I’m happy to hear that you find me amazing and that I have made your trip planning easier and more fun. 我很高兴听到你觉得我很了不起,我让你的旅行计划更轻松、更有趣。Je suis heureux d’apprendre que vous me trouvez incroyable et que j’ai rendu la planification de votre voyage plus facile et plus amusante.
</mstts:ttsembedding>
</voice>
</speak>
All customers must comply with the Guidelines for responsible deployment of synthetic voice technology and the code of conduct when using the service.
Get started
With the newly released zero-shot TTS models, the Personal Voice feature of Azure AI Speech is upgraded with higher quality. It generates speech that well captures the nuances of the user’s natural speech. Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To get started, register your use case here and apply for the access.
In addition to creating personal voices for your users, you can create a brand voice for your business with Custom Neural Voice’s professional voice feature. Azure AI Speech also offers over 400 neural voices covering more than 140 languages and locales. With these pre-built text-to-speech voices, you can quickly add read-aloud functionality for a more accessible app design or give a voice to chatbots to provide a richer conversational experience to your users.
Microsoft Tech Community – Latest Blogs –Read More
Azure AI Speech launches new zero-shot TTS models for Personal Voice
At the Ignite conference on Nov 15, 2023, we announced the public preview of Personal Voice, which is specifically designed to enable customers to build apps that allow their users to easily create and use their own AI voices (see the blog).
Today we’re thrilled to announce that Azure AI Speech Service has upgraded its Personal Voice feature with new zero-shot TTS (text-to-speech) models. Compared to the initial model, these new models improve the naturalness of synthesized voices and better resemble the speech characteristics of the voice in the prompt.
In this blog, we’ll explore how new zero-shot TTS models enable users to create a more natural sounding voice that captures their unique speech characteristics. We’ll also provide a step-by-step guide on how to integrate the personal voice capability into your apps using the Personal Voice API with different zero-shot TTS models.
Zero-shot model upgrades
The Personal Voice capability in Azure AI Speech Service allows customers to create personal voices for their users based on their unique speech characteristics. This feature can be used for various use cases, such as personalizing voice experience for a chatbot, or dubbing video content in different languages with the actor’s native voice.
Zero-shot TTS or foundation TTS models have evolved rapidly in the past year. The industry and academia have proposed various approaches to advance the technology, including Microsoft’s state-of-the-art research models such as VALL-E (X) , FoundationTTS, NaturalSpeech 2 etc. These models are typically trained with large amounts of speech data to cover different text content and voice characteristics, such as timbre, speech styles and accents. With that, the model can gain the zero-shot text-to-speech ability to clone a voice with very little data of target speakers through modules such as auto-regressive transformers or diffusion.
Every model has its strengths and weaknesses, and we understand each customer’s needs are unique. We offer a variety of base models for Personal Voice customers to choose from based on their specific scenarios. Our latest addition, the “DragonLatestNeural” model, features cutting-edge technology that allows for more realistic prosody, higher fidelity, and personalized voices that mimic the nuances of the human speaker in the prompt, with various speech characteristics. This model is currently optimized for content generation scenarios where expressiveness is highly demanded, and latency is of less concern. Our updated “PhoenixLatestNeural” model also enhances the similarity of voice to the human speaker, while maintaining low-latency performance and higher pronunciation accuracy, making it ideal for real-time scenarios. Both models have undergone significant improvements and have been trained in 10x more data than the previous “PhoenixV2Neural” model.
Here are a few voice samples with different speaking styles, generated from the latest Dragon model:
Audio prompt (human voice)
Style
Generated speech and the script
Voice assistant
Good morning! Today’s weather is sunny with a high of 75 degrees. You have two meetings scheduled and a reminder to call your mom. How can I assist you further?
News
In today’s news, a major breakthrough in renewable energy has been achieved by researchers at the GreenTech Innovation Lab. The team, led by Dr. Emily Huang, announced the development of a new solar panel technology that promises to double the efficiency of current models. This significant advancement could lead to a substantial reduction in solar energy costs.
Conversation
Hey, um, everyone, it’s Lisa. So, about dinner tonight, uh, I’m trying to decide whether to cook or maybe order something. I’m thinking, uh, pasta with garlic bread sounds good, but then I saw this new Thai place nearby, and their menu looks really tempting.
Whisper
Sure, here is the note. What else can I do for you?
Excited
Guess what? I just won the lottery – we’re going on a dream vacation!
Shout
Watch out! The ball is heading right towards you!
Story
The moment water started flooding in from the kitchen, I dropped my tools and gasped, “Shit, shit, shit!” instantly realizing my day had taken a turn for the worse.
Below are samples of two voices speaking different languages with zero-shot TTS:
Female
Male
Prompt
Prompt
朋友们,你们真是太给力了。昨天我发了一条视频,希望有人来关注我,结果真的有很多朋友关注我了。我内心非常激动,而且还有人私信我说喜欢我,这让我很感动,感受到了大伙们的友善,谢谢你们!
Okay, um, so, like, I was, uh, trying to, you know, explain this thing to, um, my friend the other day, and, well, I just couldn’t, like, find the right, uh, words? And then, you know, I thought maybe, um, I was just, kind of, overthinking it or, um, something. It’s just, uh, sometimes hard to, you know, put thoughts into, um, words, you know? How was that? Anything else on your mind?
Once upon a time, there was a little rabbit named Benny. Benny loved to hop around in the fields and nibble on carrots. One day, while he was out exploring, he stumbled upon a beautiful garden filled with all sorts of delicious vegetables.
C’era una volta un piccolo coniglio di nome Benny. A Benny piaceva saltellare nei campi e rosicchiare le carote. Un giorno, mentre esplorava, incappò in un bellissimo giardino pieno di verdure deliziose. Benny non riuscì a resistere e iniziò a mangiare la fresca lattuga e i pomodori succosi.
Customer case
GRUP MEDIAPRO, a global media company and the leader of the European audiovisual market, has partnered with Microsoft to respond to the profound transformations in the media sector brought about by AI. In a recent announcement at the ISE fair on Jan 30th, the company unveiled its Artificial Intelligence and Synthetic Media Laboratory, which has been developed in partnership with Microsoft, as part of its commitment to innovation (read the news here).
The lab leverages the latest advances in AI, including zero-shot TTS, to support research and solution development in fields such as personalization of audiovisual and digital content, voice cloning, and video processing. GRUP MEDIAPRO and Microsoft approach this collaboration with a people-centered focus, while remaining committed to legal commitments and ethical principles in the development, deployment, and use of Artificial Intelligence solutions.
You can listen to the story in the CEO’s own personal voice, which was created using the Dragon zero-shot TTS model, in Chinese and Arabic. Tatxo Benet, the CEO, leads the way in showcasing the capabilities of this new technology, which has enabled him to reach to a global audience with the languages he doesn’t speak himself.
How to use it
As part of Microsoft’s commitment to responsible AI, Personal Voice is designed with the intention of protecting the rights of individuals and society, fostering transparent human-computer interaction, and counteracting the proliferation of harmful deepfakes and misleading content. For this reason, Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To access the API and use the feature in your business applications, register your use case here and apply for the access.
Once you’ve got your access, you can start to build your personal voice project. Use the Projects_Create operation of the custom voice API, to create a personal voice project. Check out more instructions here.
Then you can follow these steps to create a personal voice using zero-shot TTS with the Dragon model.
First, you’ll need to provide the user’s consent for creating a voice profile.
With the Personal Voice feature, it’s required that every voice be created with explicit consent from the user. A recorded statement from the user is required acknowledging that the customer (Azure AI Speech resource owner) will create and use their voice. You can find the template of the verbal statement in different languages here.
Follow the samples here to add a consent from a file or from a URL.
Once you’ve given consent, you can record and upload your voice samples to create a speaker profile ID.
To use Personal Voice in your application, you need to get a speaker profile ID. The speaker profile ID is used to generate synthesized audio with the text input provided. You create a speaker profile ID based on the speaker’s verbal consent statement and an audio prompt.
Follow the code samples here to create a speaker profile ID from a file or from a URL.
After the voice profile ID is created, you can use the zero-shot TTS feature with the selected base model to synthesize speech that matches your natural speaking style, intonation, and accent.
To get a list of supported base model voice names, use the BaseModels_List operation of the custom voice API. Note that DragonLastNeural and PhoenixLastNeural are evolving models. Their performance may vary with updates for ongoing improvements. PhoenixV2Neural is stable without further updates, ensuring a consistent performance. Select the base model that best meets your needs, and use the speaker profile ID to synthesize speech in any of the 100 languages supported.
A locale tag isn’t required in the SSML when using zero-shot TTS. Personal Voice employs automatic language detection at the sentence level. Below is an SSML example using DragonLatestNeural to generate speech for your personal voice in different languages. More details are provided here.
<speak version=’1.0′ xmlns=’http://www.w3.org/2001/10/synthesis’ xmlns:mstts=’http://www.w3.org/2001/mstts’ xml:lang=’en-US’>
<voice name=’DragonLatestNeural’>
<mstts:ttsembedding speakerProfileId=’your speaker profile ID here’>
I’m happy to hear that you find me amazing and that I have made your trip planning easier and more fun. 我很高兴听到你觉得我很了不起,我让你的旅行计划更轻松、更有趣。Je suis heureux d’apprendre que vous me trouvez incroyable et que j’ai rendu la planification de votre voyage plus facile et plus amusante.
</mstts:ttsembedding>
</voice>
</speak>
All customers must comply with the Guidelines for responsible deployment of synthetic voice technology and the code of conduct when using the service.
Get started
With the newly released zero-shot TTS models, the Personal Voice feature of Azure AI Speech is upgraded with higher quality. It generates speech that well captures the nuances of the user’s natural speech. Personal Voice is a Limited Access feature available by registration only, and only for certain use cases. To get started, register your use case here and apply for the access.
In addition to creating personal voices for your users, you can create a brand voice for your business with Custom Neural Voice’s professional voice feature. Azure AI Speech also offers over 400 neural voices covering more than 140 languages and locales. With these pre-built text-to-speech voices, you can quickly add read-aloud functionality for a more accessible app design or give a voice to chatbots to provide a richer conversational experience to your users.
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Monitoring Life Cycle Management Policy Runs
The blog talks about how you can leverage the existing metrics and diagnostic logging to monitor or track the execution of lifecycle management policies.
To start, with the Lifecycle management, you will be mainly transitioning blobs from one tier to another or delete the blobs based on the specified rule configuration. So, either Set Blob Tier (REST API) – Azure Storage | Microsoft Learn or Delete Blob (REST API) – Azure Storage | Microsoft Learn will be called underneath respectively.
Now, the policy executes as part of backend scheduling and so the exact timings as to when the policy be executing on a particular day isn’t available directly. However, the policy will run once a day, and we can check for these metrics specifically. We will do this via a 2-step method.
Step 1
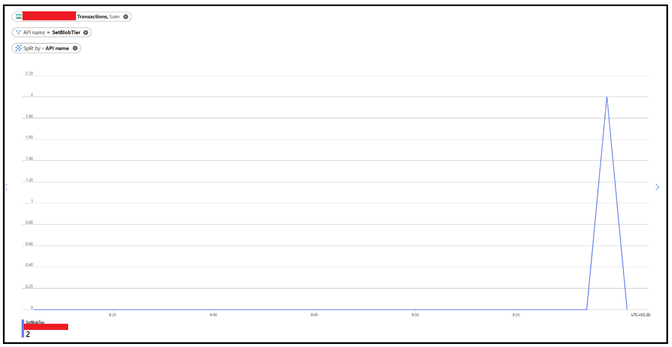
You can start by navigating to Monitoring Tab and thereafter select Metrics option. Select the Account as Metrics Namespace and Transactions as Metric. Considering the policy runs once in 24 hours we can keep the time range of last 24 or 48 hours.
Post that you can apply splitting based on API name and filter specifically for the 2 API’s i.e. SetBlobTier or DeleteBlob
You can only apply splitting too which will highlight the API however with other operations happening, filtering specifically with the API name give a cleaner picture.
Another option is to apply a filter of Transaction Type as System as LCM request come as System requests. Now, there could be other system requests however you can apply filtering via logging as discussed in the step 2 to narrown down the results.
With this step, it will give you an indication on when these operations were performed in terms on timings.
Step 2
This step is inclined to use the diagnostics logging to verify if these operations were performed using lifecycle management policy or not. Once we have identified the timings from step 1, we can use that to narrow down the query window in Step 2 or you can completely skip step 1 and directly run a flat query checking for operation specifically as well.
Typically, for the Life Cycle Management, the user Agent Header shall be something like “ObjectLifeCycleScanner” or “OLCMScanner” so we will put our query to search out for those keywords for filtration.
In the below example, we have applied filtering on UserAgentHeader field along the OperationName and have kept the time range of 24 hours. The user agent shall help verifying if the operations were performed via Life cycle management policy. In case you are using classic logging, the field to check is User Agent.
By following the above 2 steps, although there is no direct metrics available for monitoring the lifecycle management stats however you can leverage the existing ones to narrow it down to some extent.
There are couple of more scenarios where in you can leverage or capitalize on this mechanism such as below:
Scenario 1: You have a rule for moving between one tier to another. Once you have validated the SetBlobTier is happening correctly, you can monitor the blob counts via metrics too to see the effects of the same.
Scenario 2: You have a rule for deletion of blob. Once you have validated the DeleteBlob operation is happening correctly, you can monitor the capacity or blob counts to see the effects of the same.
Scenario 3: For any kind of un-intentional deletion, you could monitor via above method to verify if the deletion happened via lifecycle management policy or something else.
Additional Pointers:
Policy executes once in 24 hours so we shall keep the time window of min 24 hours for the assessment.
In case you observe policy isn’t having affects there are couple of checks to evaluate such as correct prefix match (refer to FAQ link in the reference link section), base blob type shouldn’t be page blob etc.
In case you observe policy is executing but the blobs aren’t getting not deleted completely over the path, please verify if there is multi-million blob scenario. If yes, in rare scenarios, it is quite possible that policy executes for a day and might not be able to process everything in single run. In that case, the remainder is processed in the subsequent runs so you might have to continue to monitor it for some time.
Apart from using the available monitoring and logging, there is also LifecyclePolicyCompleted event which is triggered and give a high-level information regarding actions performed as part of the policy run. You can subscribe to this event as well and leverage it too.
Hope this helps!
Reference Links:
Optimize costs by automatically managing the data lifecycle – Azure Storage | Microsoft Learn
Monitoring Azure Blob Storage – Azure Storage | Microsoft Learn
Azure Blob Storage as Event Grid source – Azure Event Grid | Microsoft Learn
Frequently asked questions – Azure Blob Storage | Microsoft Learn
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Build it with AI: Tawi’s Home-Based Auditory Processing Disorder (APD) Toolkit
Build it with AI is a series hosting AI entrepreneurs who share their journeys and experiences driving innovation in the Era of AI.
In this episode, we host Muna Numan and Syntiche Musawu, co-founders of Tawi, an app that uses speech recognition technology to suppress background noise, enhance speech quality and transcribe speech all in real-time for children living with Auditory Processing Disorder (APD). With just earphones and a mobile phone, children with APD overcome a huge communication barrier, comfortably interacting with their peers and navigating the world with more confidence to achieve their full potential.
Team TAWI also emerged as the Microsoft Imagine Cup 2023 World Champions, and in this episode, they talk about:
The ins and outs of their product (including the architecture under the hood)
AI technologies that power the product – Azure AI Service (Speech service) and OpenAI’s Whisper (now available on Microsoft Azure)
Challenges, including conflicts during the team formation stage and how they resolved this to achieve their mission.
A one-stop shop for all founders, Microsoft Founders Hub, that provided the cloud infrastructure they needed to build their product, at no cost.
Resources
TAWI Website: https://tawi-ai.com/
Founders Hub to unlock benefits for your tech Azure credits, OpenAI credits, expert 1:1 consultation for your products among other benefits.
Microsoft Tech Community – Latest Blogs –Read More
Data MVPs and Microsoft Fabric Super Users in the Era of AI | Data Exposed: MVP Edition
Taking a step back in this episode of Data Exposed: MVP Edition to dive into the Microsoft MVP program and learn what Fabric Super Users are.
Resources:
Microsoft Fabric Learn Together
Become a Fabric Analytics Engineer
View/share our latest episodes on Microsoft Learn and YouTube!
Microsoft Tech Community – Latest Blogs –Read More

What’s New in Excel (January 2024)
Happy 2024!! Welcome to our first update of the year, the January update.
This month, we are excited to share that users can now sync form data to Excel for the web. Insert pictures into cells is available to users of Excel on Windows and Mac, and PivotTables has expanded functionality in Excel for iPad.
Many of these features are the result of your feedback. THANK YOU! Your continued Feedback in Action (#FIA) helps improve Excel for everyone.
Excel for Web:
Sync Forms Data to Excel
Date Picker #FIA
Excel for Windows:
Insert Pictures in Cells #FIA
Check Performance
Excel for Mac:
Insert Pictures in Cells #FIA
Excel for iPad:
PivotTables on iPad
Excel for Web
1. Sync Forms Data to Excel
With just one click, you can now easily access all your form responses in Excel for the web and take advantage of Excel’s rich functions to analyze and visualize your data. With automatic syncing of new responses in real-time, you can keep working on your existing spreadsheet without missing a beat. Read more here >
Data Sync to Microsoft Forms
#FIA
2. Date Picker
The Date Picker feature in Excel allows you to quickly insert a date from a calendar within a cell. This tool also enables you to display preset dates within your Excel worksheets. You can activate the Date Picker pop-up by either double-clicking in a cell or entering a date manually.
Excel for Windows
#FIA
1. Insert Pictures in Cells
We’ve enabled the ability for a picture to become the actual cell value. It remains attached to the data even when the sheet’s layout is modified. You can use it in tables, sort, filter, include it in formulas, and much more! Read more here > or watch this YouTube instructional video from one of our Excel MVP’s Leila Gharani.
Insert Pictures in Cells
2. Check Performance
When you open your workbook, Excel can detect whether your workbook contains unwanted formatted cells that can slow down your workbook. If so, Excel suggests launching “Check Performance”. You can also manually launch the feature from Review > Check Performance. Read more and try it yourself >. This capability is already available for all web users.
Excel for Mac
#FIA
1. Insert Pictures in Cells
We’ve enabled the ability for a picture to become the actual cell value. It remains attached to the data even when the sheet’s layout is modified. You can use it in tables, sort, filter, include it in formulas, and much more! Read more here > or watch this YouTube instructional video from one of our Excel MVP’s Leila Gharani.
Insert Pictures in Cells
Excel for iPad
1. PivotTables for iPad
PivotTables allow you to calculate, summarize, and analyze data. This powerful tool has now been tailored for the iPad’s smaller screen and touch interface. Read more here >
PivotTables on iPad
Check if a specific feature is in your version of Excel
Click here to open in a new browser tab
Your feedback helps shape the future of Excel. Please let us know how you like a particular feature and what we can improve upon—“Give a compliment” or “Make a suggestion”.. You can also submit new ideas or vote for other ideas via Microsoft Feedback.
Subscribe to our Excel Blog and the Insiders Blog to get the latest updates. Stay connected with us and other Excel fans around the world – join our Excel Community and follow us on X, formerly Twitter.
Special thanks to our Excel MVPs David Benaim and Bill Jelen for their contribution to this month’s What’s New in Excel article. David publishes weekly YouTube videos and regular LinkedIn posts about the latest innovations in Excel and more. Bill is the founder and host of MrExcel.com and the author of several books bout Excel.
Microsoft Tech Community – Latest Blogs –Read More

Common Deployment Challenges and Workarounds for HCI 23H2
Introduction
Azure Stack HCI 23H2 introduces a new method for deploying the cluster from the Azure portal. You use the Azure portal to join on-premises servers to the domain, build a cluster, and set up an AKS on top of that to act as the resource bridge created by an AKS Cluster. These involve numerous steps and tasks that need completion, spanning from the cloud to your on-premises servers. In this blog, I will share the most common steps to help you avoid any issues that could lead to your cluster failing in the middle of the deployment.
OS Installation
If you are using existing hardware with a previous version of HCI, the wizard will prompt you to choose between a new installation or an upgrade. Opt for a new installation, but ensure to clean all the disks. This involves deleting all volumes on the OS disk, and if you had Storage Spaces Direct (S2D) configured on other disks, take the opportunity to delete the data disks as well.
Post OS Installation
Local Administrator Credentials
Once the OS is installed, you will be prompted to enter a new password for the default Administrator. I suggest you create a password following Azure recommendations. The reason is, during the deployment, you will be asked to enter a username and password for the local administrator, just in case If you decide to use the default administrator credentials, of course you can change the password later on using PowerShell.
$NewPassword = Read-Host -AsSecureString
Set-ADAccountPassword Administrator –NewPassword $NewPassword -Reset
However I suggest you create a new local user and adding to local Administrators
$NewLocalAdmin = Read-Host
$Password = Read-Host -AsSecureString
New-LocalUser “$NewLocalAdmin” -Password $Password -FullName “$NewLocalAdmin” -Description “Local User for HCI Deployment” | Add-LocalGroupMember -Group “Administrators”
Networking
There are some steps you should consider performing at the beginning the deployment , some of them are required and other you need to make it easier for yourself while you are preparing the nodes
Windows Firewall
Enable file and print share on each node after the deployment you need to disable it
netsh advfirewall firewall set rule group=”File and Printer Sharing” new enable=Yes
Enable Internet Control Message Protocol (ICMP). This command is required for the other nodes to access the first node. (Required for the deployment )
netsh advfirewall firewall add rule name=”ICMP Allow incoming V4 echo request” protocol=icmpv4:8,any dir=in action=allow
NetworkAdapter
Rename the adapter based on the usage , probably in each node you have 6 ports 2 for Management, 2 for Management , 2 for Compute and 2 for storage , obviously I would make the RDMA capable Network Interface for the storage the following are cmdlet that needed to manage the network adapter
List all Network Adapters
Get-NetAdapter
Rename Network Adapter
Rename-NetAdapter -Name “CURRENT NETWORK ADAPTER NAME” -NewName “NEW Network NAME”
** I suggest renaming the adapter based on the intended use (e.g., Storage01 for storage, MGMT-COMPUTE01 for combined Management and Compute on the same NIC, etc.). Ensure that the names are consistent across all nodes for the same purpose or usage.
Assign a VLAN to the network interface
Set-Netadapter -VlanID “VLAN NUMBER” – Name “NETWORK ADAPTER NAME”
Identify RDMA capable network adapters that have RDMA enabled
Get-NetAdapterRdma -Name “*” | Where-Object -FilterScript { $_.Enabled }
Assign IP to the Management interface
New-NetIPAddress -InterfaceAlias “NETWORK ADAPTER NAME” -IPAddress “IP Address for Management” -PrefixLength 24 -DefaultGateway “Default Gateway” -AddressFamily IPv4
Assign DNS to the management interface
Set-DnsClientServerAddress -InterfaceAlias “NETWORK ADAPTER NAME” -ServerAddresses (“IP FOR DNS SERVER1″,”IP FOR DNS SERVER1”)
**Ensure that only one network adapter has a configured gateway; the deployment prerequisites will fail if multiple gateways are detected on the server. Verify that the Component IDs are consistent for network cards with the same intent
Get-NetAdapter | Select name , ComponentID
Disable IPV6 on all adapters
Disable-NetAdapterBinding -Name * -ComponentID ms_tcpip6
Disable DHCP on all adapters
Set-NetIPInterface -InterfaceAliace * -Dhcp Disabled
Proxy Setup
If the node are behind a proxy the following configuration are required
Install and configure WinInetProxy module
$proxyurl = ‘http://PROXYURL:PORTNUMBER‘
$proxy= ‘PROXYURL:PORTNUMBER’
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
[system.net.webrequest]::defaultwebproxy = new-object system.net.webproxy($proxyurl)
[system.net.webrequest]::defaultwebproxy.credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials
[system.net.webrequest]::defaultwebproxy.BypassProxyOnLocal = $true
$WebClient = New-Object System.Net.WebClient
$WebClient.DownloadFile(“https://psg-prod-eastus.azureedge.net/packages/wininetproxy.0.1.0.nupkg“,”C:wininetproxy.0.1.0.zip”)
New-Item -Path $env:ProgramFilesWindowsPowerShellModulesWinInetProxy -ItemType Directory
cd $env:ProgramFilesWindowsPowerShellModulesWinInetProxy
Expand-Archive -Path C:wininetproxy.0.1.0.zip
Move-Item -Path .wininetproxy.0.1.0 -Destination ..1.0
Set-ExecutionPolicy -ExecutionPolicy Bypass
Import-Module WinInetProxy
Set-WinInetProxy -ProxySettingsPerUser 0 -ProxyServer proxy -ProxyBypass “<local>”
Set up netsh winhttp proxy
netsh winhttp set proxy proxy-server=’http://PROXYURL:PORTNUMBER‘ bypass-list=”localhost;<local>;*.Internaldomain;Node1;Node2;clustername;first three octets of the IP address.*”
Example
netsh winhttp set proxy proxy-server=”http://globalproxy.Contoso.com:9400” bypass-list=”localhost;<local>;*.corp.contoso.com;HCIN1;HCIN2;HCIN3;HCIN4;Cluster01;192.90.8.*”
Set up environment variables
[Environment]::SetEnvironmentVariable(“HTTPS_PROXY”, “http://globalproxy.Contoso.com:9400“, “Machine”)
$env:HTTPS_PROXY = [System.Environment]::GetEnvironmentVariable(“HTTPS_PROXY”, “Machine”)
[Environment]::SetEnvironmentVariable(“HTTP_PROXY”, “http://globalproxy.Contoso.com:9400“, “Machine”)
$env:HTTP_PROXY = [System.Environment]::GetEnvironmentVariable(“HTTP_PROXY”, “Machine”)
$no_proxy = “localhost,127.0.0.1,.svc,192.90.8.192/22,.corp.Contoso.com”
[Environment]::SetEnvironmentVariable(“NO_PROXY”, $no_proxy, “Machine”)
$env:NO_PROXY = [System.Environment]::GetEnvironmentVariable(“NO_PROXY”, “Machine”)
Set up PowerShell and install Az.StackHCI module
$proxy = ‘http://globalproxy.Contoso.com:9400‘
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
[system.net.webrequest]::defaultwebproxy = new-object system.net.webproxy($proxy)
[system.net.webrequest]::defaultwebproxy.credentials = [System.Net.CredentialCache]::DefaultNetworkCredentials
[system.net.webrequest]::defaultwebproxy.BypassProxyOnLocal = $true
Install-PackageProvider -Name nuget -Scope AllUsers -Confirm:$false -Force -MinimumVersion 2.8.5.201
Set-PSRepository PSGallery -InstallationPolicy Trusted
install-module az.stackhci
Network Driver Update
HCI doesn’t support home driver, you need to download the driver from the hardware vendor, the following cmdlet will help you
Start-BitsTransfer -Source “http://VENDORURL/NetworkDrive.exe” -Destination “c:tempNetworkDrive.exe”
After you install the vendor driver , make sure to check the driver provider name, as well as the ComponentID
Get-NetAdapter | Select name , ComponentID, DriverProvider | FT
After the upgrade, I’ve observed that the ComponentID for the same card can change, even though it may remain the same but in a different letter format. For example, in a dual-card setup, Port 1 might have the ComponentID in small letters, while Port 2 has it in capital letters. To address this, consider uninstalling the drivers, installing a lower version of the driver, and then upgrading to the latest driver update.
Register HCI Node with ARC
On all the nodes, make sure you have the required Modules
Register PSGallery as a trusted repo
Register-PSRepository -Default -InstallationPolicy Trusted
Install Arc registration script from PSGallery
Install-Module AzsHCI.ARCinstaller
Install required PowerShell modules in your node for registration
Install-Module Az.Accounts -Force
Install-Module Az.ConnectedMachine -Force
Install-Module Az.Resources -Force
Create the following variable and assign the appropriate value
Define the subscription where you want to register your server as Arc device
$Subscription = “YourSubscriptionID” #Define the resource group where you want to register your server as Arc device
$RG = “YourResourceGroupName” #Define the tenant you will use to register your server as Arc device
$Tenant = “YourTenantID”
Connect to Azure using the Devise Code switch
Connect-AzAccount -SubscriptionId $Subscription -TenantId $Tenant -DeviceCode
Get the Access Token for the registration
$ARMtoken = (Get-AzAccessToken).Token
Get the Account ID for the registration
$id = (Get-AzContext).Account.Id
Invoke the registration script. For this release, eastus and westeurope regions are supported.
Invoke-AzStackHciArcInitialization -SubscriptionID$Subscription -ResourceGroup$RG -TenantID$Tenant -Regioneastus -Cloud”AzureCloud” -ArmAccessToken$ARMtoken -AccountID$id
In case you have a proxy use the following command
Invoke-AzStackHciArcInitialization -SubscriptionID$Subscription -ResourceGroup$RG -TenantID$Tenant -Regioneastus -Cloud”AzureCloud” -ArmAccessToken$ARMtoken -AccountID$id – proxy http://PROXYURL:PORTNUMBER
After the node appears in Azure as an hybrid machine, verify that you have all the extension have been successfully installed
I often see the TelemetryAndDiagnostics and AzureEdgeLifeCyclemanager extension in failed state after registering the nodes to ARC
How to Fix
TelemetryAndDiagnostics
From any of the HCI node run the following
Remove-AzConnectedMachineExtension -MachineName <NodeName> -Name “TelemetryAndDiagnostics ” -ResourceGroupName <Resource Group name> -SubscriptionId <SubscriptionID> -NoWait
After the extension get removed from the portal reinstall the extension
New-AzConnectedMachineExtension -MachineName <NodeName> -Name “TelemetryAndDiagnostics” -ResourceGroupName <Resource Group name> -SubscriptionId <SubscriptionID> -Location <region>-Publisher “Microsoft.AzureStack.Observability.TelemetryAndDiagnostics” -ExtensionType “TelemetryAndDiagnostics” -NoWait
What happen if the extension get stuck in deleting status
Try to use the ARM client to delete the extension , then reboot the node
.ARMClient.exe delete “<ResourceID>?api-version=2023-10-03-preview
You can get the resource ID from by checking the checkbox to show hidden resources
AzureEdgeLifecycleManager
On the affected node go to Go to `C:MASLogsLCMECELiteLogs`
run $filename = Get-ChildItem *.xml -recurse | Select-String -pattern “InitializeDeploymentService” | select Path -last 1
Copy the XML to the C:EceStore
copy $filename.path C:EceStoreefb61d70-47ed-8f44-5d63-bed6adc0fb0f`
remane the XML file you just copied to “dcd7bf4e-5148-83f1-1fdb-dbfca46c6840”
Rename-Item $filename -NewName dcd7bf4e-5148-83f1-1fdb-dbfca46c6840
** keep the above GUIDs as they are
Reboot the node and wait for 5 minutes and check the portal.
Microsoft Tech Community – Latest Blogs –Read More
Data MVPs and Microsoft Fabric Super Users in the Era of AI | Data Exposed: MVP Edition
Taking a step back in this episode of Data Exposed: MVP Edition to dive into the Microsoft MVP program and learn what Fabric Super Users are.
Resources:
Microsoft Fabric Learn Together
Become a Fabric Analytics Engineer
View/share our latest episodes on Microsoft Learn and YouTube!
Microsoft Tech Community – Latest Blogs –Read More
Data MVPs and Microsoft Fabric Super Users in the Era of AI | Data Exposed: MVP Edition
Taking a step back in this episode of Data Exposed: MVP Edition to dive into the Microsoft MVP program and learn what Fabric Super Users are.
Resources:
Microsoft Fabric Learn Together
Become a Fabric Analytics Engineer
View/share our latest episodes on Microsoft Learn and YouTube!
Microsoft Tech Community – Latest Blogs –Read More
Data MVPs and Microsoft Fabric Super Users in the Era of AI | Data Exposed: MVP Edition
Taking a step back in this episode of Data Exposed: MVP Edition to dive into the Microsoft MVP program and learn what Fabric Super Users are.
Resources:
Microsoft Fabric Learn Together
Become a Fabric Analytics Engineer
View/share our latest episodes on Microsoft Learn and YouTube!
Microsoft Tech Community – Latest Blogs –Read More
Data MVPs and Microsoft Fabric Super Users in the Era of AI | Data Exposed: MVP Edition
Taking a step back in this episode of Data Exposed: MVP Edition to dive into the Microsoft MVP program and learn what Fabric Super Users are.
Resources:
Microsoft Fabric Learn Together
Become a Fabric Analytics Engineer
View/share our latest episodes on Microsoft Learn and YouTube!
Microsoft Tech Community – Latest Blogs –Read More







